开放性知识库的规范化(个人理解:这里的规范化实际上就是将相同语义的实体或关系聚集在一起,从而表示一个实体或关系),主要是OPENie提取的过程中没有进行区分,最近的研究发现,开放KBS的规范化实际上是特征空间的聚类,我们提出使用知识图谱嵌入+边信息的方法来得到(经过查询,KBE应该主要用在语义查询,链接预测等方面,这里创新性的用在知识库的规范化中)embedding,然后对embedding进行聚类
当然有些工作可以起到类似的作用,比如通过实体链接将短语链接到现有数据库中,但是这种方法效果并不好,我们这里采用新的CESI方法进行KB的规范化
KBE详解:首先我们清楚KB都是一些三元组组成的,一般来说都是(head,rela,tail)这样形式,但是如果我们要进行机器学习,则必须将三元组转化为向量来进行计算,那如何做这种嵌入,则首先要假设一个score函数,这个函数是来度量head与tail在某个关系上的相似度,主要是TransE和DistMult两大类代表,有了这个scre函数后,便可以设定positive triplets更高,而negative triplets更低(负样本在正样本的基础上生成)
这个KBE也是本篇文章的核心,也就是下面的公式:
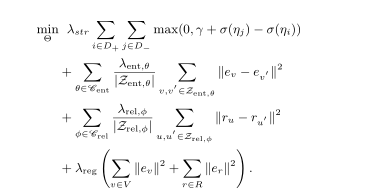
这个公式主要由三部分组成,第一部分就是前面提到的KBE部分,在score函数的基础上进行目标函数的构建:score函数主要是采用HOLE:如下:
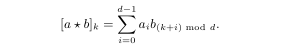
同时score函数经过逻辑激活函数与排序损失函数,得到现在的目标函数,后面的两项就是边信息(其实这个地方我不太明白为什么直接加),关于边信息,分为名词的边信息与关系的边信息,这个边信息在我看来是一种属性,一种名词与名词,关系与关系是否相等的附加项,比如名词链接边信息,当两个名词链接到同一个实体时,便表明这两个名词在语义上是相同的,在后面聚类的时候就会考虑到这个因素