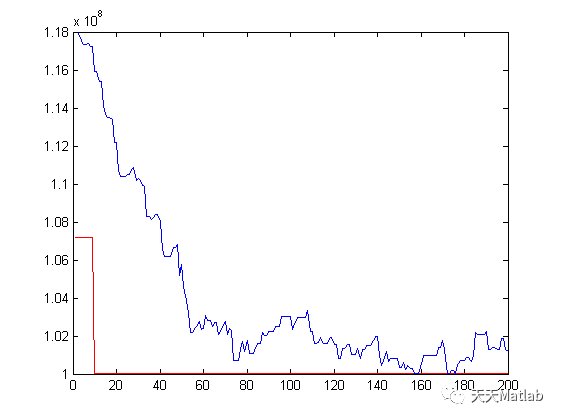
课题研究的是单目3D车辆的识别,采用的目标检测网络是SMOKE,为了可以更好的定量评测训练模型的性能,需要使用到合理的评测指标,目前比较流行的评测指标是得到多组precision和recall值画出PR曲线,然后计算PR曲线下的面积得到AP。
关于更详细的原理的介绍已经有很多优秀的文章,本篇博客主要是结合Kitti数据集的官网代码以及自己的理解做的一些总结,如有理解不当请斧正。
基本概念的理解
IOU:IOU指的是两个检测框的交并比,也就是两个框的重合程度,数值越大代表两个框重合度越高。在计算AP的过程中,IOU的一个作用是作为判断目标是否被检测出来的阈值,如果detection框与groundtruth框的IOU大于一定的阈值(比如说0.7),那么就说明目标别检测出来了。
注意:对于绘制PR曲线来说,判断目标是否被检测出来有两个重要指标,一个是上面说的IOU,还有一个就是置信度,所以我理解IOU的作用就是做一个固定值的过滤,后续画PR曲线的precision和recall值对其实是根据置信度的不断调整获得的。
TP,FP,FN:T和F代表true和false,P和N代表positive和negative,所以
- TP:检出目标是positive,groundtruth确实是true,说明目标被正确的检出
- FP:检出目标是positive,groundtruth却是false,说明误检出了不存在的目标,误检
- FN:检出目标是negative,groundtruth是true,说明本该被检出的没有检出,漏检
precision和recall:precision和recall的定义如下

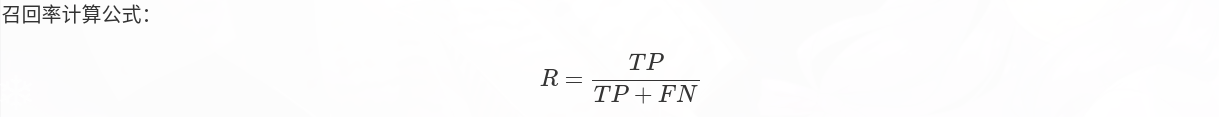
那么在程序中我们应该如何计算TP、FP、FN呢?
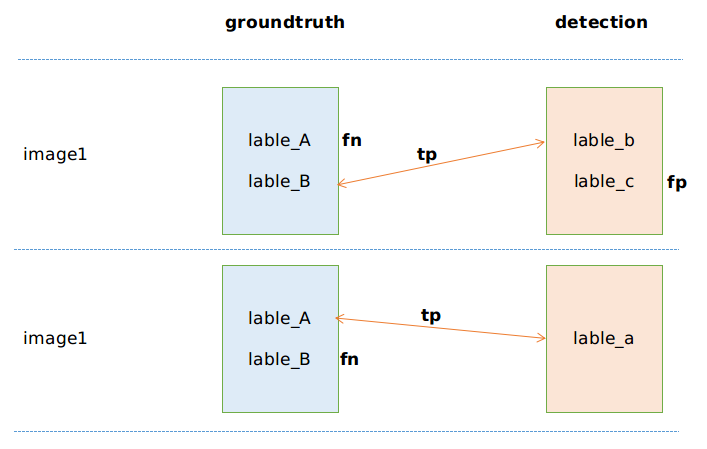
TP、FP:
遍历detection的每张image中的每个lable,比如image1中的label_b和lable_c,然后对于每一个lable,再遍历groundtruth中image1的所有lable,查看是否匹配,如果成功匹配到一个,那么TP+1,如果groundtruth中都没有匹配的,那么说明detection中此lable为误捡,则FP+1.
FN:
遍历groundtruth的每张image中的每个lable,比如image1中的label_A和lable_B,再去除刚才TP+1的时候匹配上的,如果还有剩下的,那么代表此lable漏检了,FN+1.
可以看到precision是针对detection,也就是所有detection检测的目标有多少是正确的,也叫作查准率;recall则是针对groundtruth,也就是groundtruth中所有的目标有多少是被检测出来的,也叫作查全率。
从定义可以看出,这两个是指标是矛盾的,要保证其中一个效果好,另一个必然保证不了效果。比如:如果希望precision(查准率)高,那么我就提高检测的阈值,我不用管没检测出来的,我只要保证我检测出来的就是真的目标,那么precision值肯定高,但是因为好多并没有检测出来,漏检很多,recall值肯定不高;如果希望recall(查全率)高,那么我就降低检测阈值,不用管误捡的状况,只要保证尽可能的把目标检测出来,那么recall值肯定高,但是因为误捡很多,precision得不到保证。
所以针对这一对天然矛盾的指标,取任何一方都不合理,因此使用更加合理的AP,也就是取不同的置信度得到若干对precision和recall,将其画在y轴为precision和x轴为recall的坐标系中构成PR曲线,围成的面积就是AP值。
为了保证AP值的统一,也需要统一其他的参数:IOU阈值和置信度数量,在SMOKE论文中

可以看到使用的IOU阈值是0.7 计算AP采用40个点
经过以上相关概念的分析,我们可以想一下,如果我们面对着groundtruth的labels和detection的labels,我们得到AP大体的思路是如何的?
如果我们想要得到AP,那我们必须根据40个置信度(假设采用40个点)来计算precision和recall,计算precision和recall可以依次比较两帧groundtruth和detection的结果得到TP,FP,FN,那么如何得到40个置信度呢? 也就是说我们还需要提前遍历一遍所有的labels得到所有的TP结果和它们的置信度,从这些置信度里面选择40个,经过这么一分析,我们可以大体得到代码的总体思路:
注意点:这个需要注意一个概念,就是如何定义“匹配”,这个需要考虑两个指标,一个是IOU,另一个就是置信度,在AP流程中,需要计算两次TP,第一次定义匹配是找满足最小IOU后找置信度最大的,也就是获取置信度列表的时候;第二次计算TP定义匹配则是寻找最大IOU的,也就是最终画曲线所需要的TP。所以整个流程计算了两次TP,一次是为了获取置信度列表,另一次是为了画AP曲线。
下面主要结合代码来分析
- 数据预处理
数据预处理的目的是将labels中的数据读入到程序的vector中,当然在读入的过程中可以针对自己的需求进行操作,比如我只比较Car类别,那么在读入的过程中我可以舍弃掉其他的类别以及dont care数据这一部分是在loadGroundtruth和loadDetections两个函数中
if (fscanf(fp, "%s %lf %d %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf",str, &g.truncation, &g.occlusion, &g.box.alpha,&g.box.x1, &g.box.y1, &g.box.x2, &g.box.y2,&g.h, &g.w, &g.l, &g.t1,&g.t2, &g.t3, &g.ry )==15 && !strcasecmp(str, "Car")) { // 只需要Car类型其中groundtruth和detection的label结果都存放在事先定义好的结构体tGroundtruth和tDetection中,下一个预处理的过程是在 cleanData这个函数里,这个函数所做的操作是是这样的:将单帧图像groundtruth中的所有label和detection中的所有label进行遍历来确定是不是应该ignore,而是否ignore的判断标准有class,occlusion,truncation和height,这里要说一下,kitti评价的时候会按照遮挡和截断情况将场景分为简单,中等,困难三个场景,考虑到自己的场景比较简单,因此修改代码为只评测Car这个类别,并且不对场景难度进行区分,同时因为训练集没有标定2D框,所以不考虑height这个类别(这些的修改都在阈值定义的数据结构里),进行判断的代码如下:
bool ignore = false;if(gt[i].occlusion>MAX_OCCLUSION[difficulty] || gt[i].truncation>MAX_TRUNCATION[difficulty] || height<=MIN_HEIGHT[difficulty])ignore = true;if(!strcasecmp(det[i].box.type.c_str(), CLASS_NAMES[current_class].c_str()))valid_class = 1;elsevalid_class = -1;int32_t height = fabs(det[i].box.y1 - det[i].box.y2);// set ignored vector for detections height不低于一定范围并且class正确if(height<MIN_HEIGHT[difficulty])ignored_det.push_back(1);else if(valid_class==1)ignored_det.push_back(0);elseignored_det.push_back(-1);- 置信度列表
这里再说明一下,为什么需要置信度列表?
因为为了更合理的评价结果,需要画AP曲线,也就是需要计算不同的precision和recall点对,而每一对不同的precision和recall,则对应着一个置信度阈值,比如说置信度阈值提高,那么groundtruth和detection中匹配的lable肯定会变少;如果我们把置信度阈值放宽,那么匹配的lable就会变多,也就是将目标检出的概率变大了。
这里获得的置信度的总数理想情况下应该是40,因为这是事先定好的,那么如何选择40个置信度呢?当然可以从0%到100%进行40等分,然后计算得到40个precision和recall点对,但是这种方法计算起来比较“繁琐”,这是因为对于每一个置信度,都需要去计算一遍TP,FP,FN,虽然理论上是这样的,不过代码中的方式更简洁一点而且也更有意思。
正常的思路是这样的:选择一个置信度---计算recall和precision---画图
而代码中思路是这样的:先确定recall值为i/40(i从1取到40)---找到每个recall对应的置信度---用这个置信度去计算precision---画图
计算先确定recall值再去确定置信度,比如说当前recall值为7/40,那么对应的置信度是多少呢?这就需要找到recall值与TP、FN与置信度之间的联系了,这也是代码中置信度列表选取的核心!
recall的计算公式是 recall = TP/(TP + FN),分母是groundtruth中非ignore的目标的个数,可以理解为所有待检测的目标,这个值在预处理数据的时候就被计算出来了,在程序中是n_gt,这样recall的值就取决于TP的值,而TP的值则取决于置信度的取值,置信度取值越高,TP值越小(这就是前面说的目标是否被检测出来一个取决于IOU阈值,另一个取决于置信度)。
TP值和置信度取值的关系可以看下图:

图解:当置信度取0.98以上的时候,由于所有detection的lable的置信度都达不到,那么其实就是所有的目标没有检测出来,因此给置信度过滤掉了,当我们把置信度降为0.98的时候,一个匹配上了,那么TP值就是1;当置信度再降为0.95的时候,有两个lable被判定为检出并匹配上,所以TP值就是2和3对应的置信度都是0.95;为什么TP值只能到60呢?这是因为在判断检出的时候还需要考虑IOU,及时置信度为0就算检出,但是因为有最低IOU的限制,也不能匹配上。
这样我们就得到TP值和置信度的关系了,那么如何获取到置信度列表呢?就是第一次计算TP的时候,记录每一个判定为“匹配”的lable的置信度,最后降序排序。注意这时候判定groundtruth和detection“匹配”,也就是TP+1的标准是:符合IOU最低标准的条件下,置信度最高的那个。
这时候有了置信度列表了,就可以按照刚才的思路进行了:加入recall值取到7/40,根据recall值的公式,得到对应的TP值,然后根据上面的表找到最接近的TP值对应的那一列的置信度记录下来,这里还要注意,recall值的取值是从1/40到40/40的,但是由于TP值取不到n_gt值,所以recall值列表后面可能对应的置信度都是0,表现在AP曲线上就是曲线与recall轴重合了,其实也很好理解,TP值不够大,说明模型效果不太好,AP曲线快速与recall轴重合,面积是0,AP值就比较小,恰好说明模型效果不太好。
下面是根据降序排序的所有置信度取置信度列表:
for(int32_t i=0; i<v.size(); i++){ //此时的置信度已经按照降序排序了// check if right-hand-side recall with respect to current recall is close than left-hand-side one// in this case, skip the current detection scoredouble l_recall, r_recall, recall;l_recall = (double)(i+1)/n_groundtruth;if(i<(v.size()-1))r_recall = (double)(i+2)/n_groundtruth;elser_recall = l_recall;// 也就是说只要current_call走的比较快,那么就不添加v了,直到v的索引跟上之后就把当前的v[i]值加入进去if( (r_recall-current_recall) < (current_recall-l_recall) && i<(v.size()-1))continue;// left recall is the best approximation, so use this and goto next recall step for approximationrecall = l_recall;// the next recall step was reachedt.push_back(v[i]);current_recall += 1.0/(N_SAMPLE_PTS-1.0);}- 计算P R
通过前面得到了40个置信度作为置信度列表(其实后面因为取不到,所以40个置信度后面好多都是0值)这一步就是取置信度列表中的值,计算模型对于测试样本的precision和recall(而且recall值不用计算了,因为recall值在一开始被人为定义为i/40了,是不是很方便),实现过程在computeStatistics函数中
首先对于计算FN和TP,我们需要遍历groundtruth所有的label,找在对应帧中label的状况,如果找到符合条件的,那么就tp++,如果没有找到,就说明漏检了,则fn++
if( !compute_fp && overlap>MIN_OVERLAP[metric][current_class] && det[j].thresh>valid_detection){det_idx = j;valid_detection = det[j].thresh;
}
else if(compute_fp && overlap>MIN_OVERLAP[metric][current_class] && (overlap>max_overlap || assigned_ignored_det) && ignored_det[j]==0){max_overlap = overlap;det_idx = j;valid_detection = 1;assigned_ignored_det = false;
}
else if(compute_fp && overlap>MIN_OVERLAP[metric][current_class] && valid_detection==NO_DETECTION && ignored_det[j]==1){det_idx = j;valid_detection = 1;assigned_ignored_det = true;
}上面是寻找匹配detection label的判断标准,其中compute_fp代表是否计算fp,第一次调用这个函数也就是为了得到置信度列表的时候,我们不需要计算fp,因为我们的目的是得到所有TP样本的置信度,而第二次调用的时候为了计算precision和recall,就需要置compute_fp为true了。
可以看到如果不计算fp的话,寻找最佳的匹配label在满足最低overlap阈值的情况下主要是寻找置信度最大的,而在计算fp的时候则主要考虑的是overlap。
下面主要是计算fn和tp
if(valid_detection==NO_DETECTION && ignored_gt[i]==0) {stat.fn++;
}else if(valid_detection!=NO_DETECTION && (ignored_gt[i]==1 || ignored_det[det_idx]==1)){assigned_detection[det_idx] = true;
}else if(valid_detection!=NO_DETECTION){stat.tp++;stat.v.push_back(det[det_idx].thresh);// clean upassigned_detection[det_idx] = true;
}然后下面计算fn,fn代表漏检,因此需要先遍历detection,然后在groundtruth里面寻找
for(int32_t i=0; i<det.size(); i++){ //遍历detection labels// count false positives if required (height smaller than required is ignored (ignored_det==1)// FP的意思是对于groundtruth没有的label,detection却检测出来了if(!(assigned_detection[i] || ignored_det[i]==-1 || ignored_det[i]==1 || ignored_threshold[i]))stat.fp++;}- PR曲线和计算AP
其实到上一步大部分的工作已经做完了,下面就是利用计算的TP,FP,FN画PR曲线和计算AP,画曲线就不说了,不过在计算AP的时候,需要事先对precisions做一个预处理,因为在我看来,之前recall选定固定值之后,AP的计算其实就是precision×(1/40)并求和,而为了画PR曲线,我想将precision按照降序排序,然后画图计算,可是源代码中给定的预处理方式是:
for (int32_t i=0; i<thresholds.size(); i++){precision[i] = *max_element(precision.begin()+i, precision.end());if(compute_aos)aos[i] = *max_element(aos.begin()+i, aos.end());
}对于此我的理解是这种方法是为了避免曲线出现摆动,保证曲线是下降的,而AP是一个评价指标,只要所有模型所采用的评价指标的计算方法是一样的就可以,不必拘泥于中间的一些细节问题。