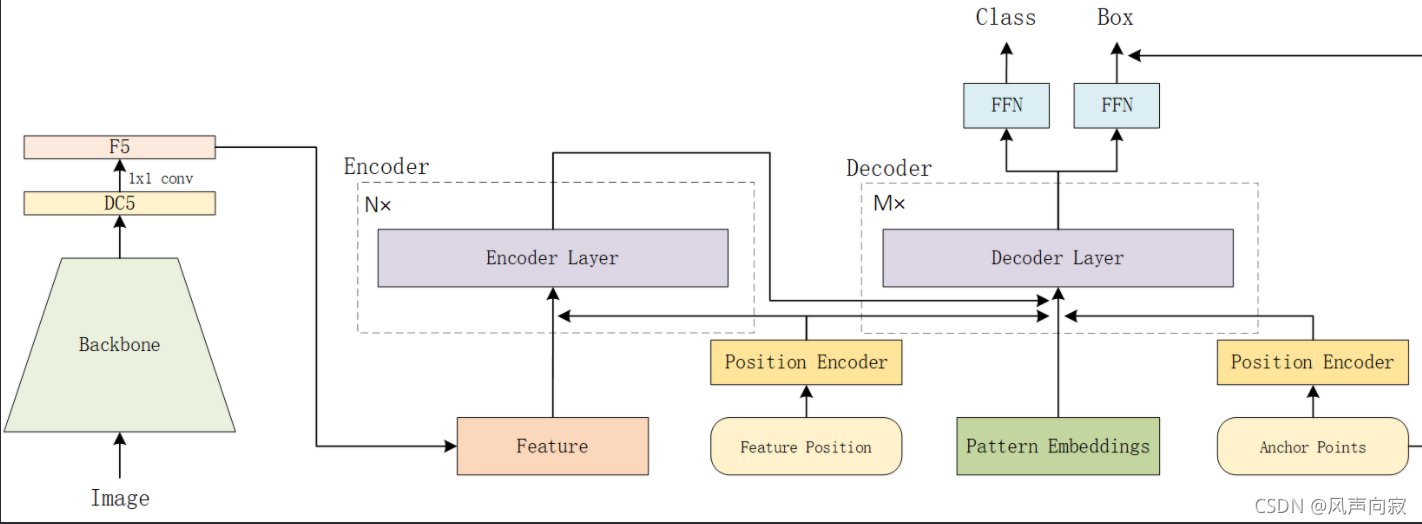
这里介绍如何修改 Anchor 的尺寸来提高小目标的检测效果,算法tricks优化小目标检测
修改 Anchor 尺寸
在实际的应用场景中,我们按照 MS COCO 标准中把大小不大于 32x32 或者占原始图片比率不足 0.01 的目标物体定义为一个小目标物体。
在使用 Anchor 的检测算法(以目标检测网络 Faster RCNN 为例)中,如下图所示:算法会按照一定的规则在主干网络的所有输出 Feature Map 上生成不同尺寸的 Anchor,而候选提议框生成层 RPN(RPN 的输出结果和最后生成的预测目标物体框的大小、分类以及定位息息相关)则会预测这些 Anchor 中是否含有目标物以及目标物体框离 Anchor 框的偏移。
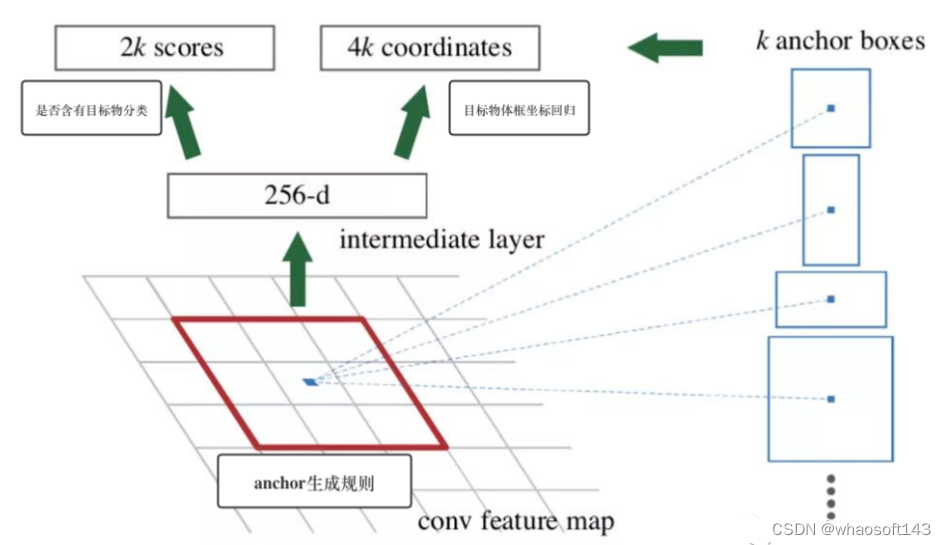
为了提高小目标物体的检测效果,我们可以通过修改 Anchor 的尺寸来生成合适的 Anchor。
下面我们详细介绍如何修改 Anchor 的尺寸来提高小目标的检测效果。根据上图所示我们知道 Anchor 生成在主干网络的输出特征图上进行,如果我们选择合适的 Anchor 来 Match 小目标,我们就可以提高小目标物体的分类准确度和定位精准度,从而提高小目标的检测精准度。
下面我们以 Faster RCNN 网络中 Anchor 的生成代码为例,说明如何调节输入参数来对调节 Anchor 的尺寸。
import numpy as np # 传入anchor的左上角和右下角的坐标,返回anchor的中心坐标和长宽
def _whctrs(anchor): """ :param anchor: list,某个anchor的坐标信息[xmin, ymin, xmax, ymax] :return: anchor的中心点坐标和anchor的长宽 """ w = anchor[2] - anchor[0] + 1 h = anchor[3] - anchor[1] + 1 x_ctr = anchor[0] + 0.5 * (w - 1) y_ctr = anchor[1] + 0.5 * (h - 1) return w, h, x_ctr, y_ctr # 给定一个anchor的中心坐标和长宽,输出各个anchor,即预测窗口,**输出anchor的面积相等,只是宽高比不同**
def _mkanchors(ws, hs, x_ctr, y_ctr): """ :param ws: anchor的宽 :param hs: anchor的长 :param x_ctr: anchor中心点x坐标 :param y_ctr: anchor中心点y坐标 :return: numpy array, 生成的符合条件的一组anchor """ # 将ws和hs数组转置 ws = ws[:, np.newaxis] hs = hs[:, np.newaxis] # 生成符合条件的一组anchor anchors = np.hstack((x_ctr - 0.5 * (ws - 1), y_ctr - 0.5 * (hs - 1), x_ctr + 0.5 * (ws - 1), y_ctr + 0.5 * (hs - 1))) return anchors # 将给定的anchor放大scales中指定的倍数
def _scale_enum(anchor, scales): """ :param anchor: list,某个anchor的坐标信息[xmin, ymin, xmax, ymax] :param scales: list,将anchor中的元素放大到scales中指定的倍数 :return: numpy array, 生成的符合条件的一组anchor """ # 找到anchor的中心坐标 w, h, x_ctr, y_ctr = _whctrs(anchor) # 将anchor的长宽放大到scales中指定的倍数 ws = w * scales hs = h * scales # 根据指定的anchor长宽和中心点坐标信息生成一组anchor anchors = _mkanchors(ws, hs, x_ctr, y_ctr) return anchors # 计算不同长宽尺度下的anchor的坐标
def _ratio_enum(anchor, ratios): """ :param anchor: 基准anchor :param ratios: list, anchor长宽比例尺寸 :return: list, 生成的anchor信息 """ # 获取anchor的中心点坐标和长宽 w, h, x_ctr, y_ctr = _whctrs(anchor) # 获取anchor的面积 size = w * h # 在保持面积不变的情况下生成ratios中指定长宽比的anchor长和宽 size_ratios = size / ratios ws = np.round(np.sqrt(size_ratios)) hs = np.round(ws * ratios) # 获取指定长宽和中心点坐标的anchors anchors = _mkanchors(ws, hs, x_ctr, y_ctr) return anchors def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2 ** np.arange(3, 6)): """ :param base_size: int, 基准anchor尺寸 :param ratios: list, anchor长宽比例尺寸 :param scales: list, anchor边长放大的倍数 :return: list, 生成的anchor信息 """ # 请注意anchor的表示形式有两种,一种是记录左上角和右下角的坐标,一种是记录中心坐标和宽高 # 这里生成一个基准anchor,采用左上角和右下角的坐标表示[0,0,15,15] # base_anchor = [0,0,15,15] base_anchor = np.array([1, 1, base_size, base_size]) - 1 # 按照ratios元素信息生成不同长宽比的anchor ratio_anchors = _ratio_enum(base_anchor, ratios) # 将ratio_anchors中的每个anchor放大到scales里指定的倍数 anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales) for i in range(ratio_anchors.shape[0])]) return anchors if __name__ == '__main__': import time t = time.time() # 生成anchor a = generate_anchors(base_size=16, ratios=[0.25, 0.5, 1, 2], scales=2 ** np.arange(2, 6)) # 打印生成过程所需要的时间 print(time.time() - t) print(a)
结果如下:
0.00026607513427734375
[[ -56. -8. 71. 23.] [-120. -24. 135. 39.] [-248. -56. 263. 71.] [-504. -120. 519. 135.] [ -38. -16. 53. 31.] [ -84. -40. 99. 55.] [-176. -88. 191. 103.] [-360. -184. 375. 199.] [ -24. -24. 39. 39.] [ -56. -56. 71. 71.] [-120. -120. 135. 135.] [-248. -248. 263. 263.] [ -14. -36. 29. 51.] [ -36. -80. 51. 95.] [ -80. -168. 95. 183.] [-168. -344. 183. 359.]]
上述 Anchor 函数生成的所有 Anchor,我们可以根据主干网络的网络架构计算出其在原始图像上的感受野大小。进而可以比对原始图片上感受野大小和原始图片上目标标注框大小。而在实际操作过程中,原始图片上目标标注框已经获取,我们需要通过分析这些目标标注框的大小反推 Anchor 生成函数的参数,进而调控生成 Anchor 的尺寸来更好的 Match 小目标物体的尺寸。上面给出的 Anchor 生成函数 generate_anchors 共有三个可调节参数:
-
第一个参数 base_size 为基准 Anchor 的大小。
-
第二个参数 ratios=[0.5, 1, 2] 指的是在保持面积不变的情况下,Anchor 框的边长按照 1:2、1:1、2:1 三种比例进行变换得到一组新的 Anchor,如下图所示:
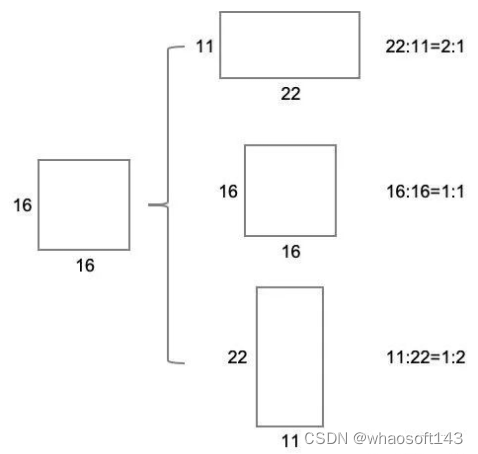
-
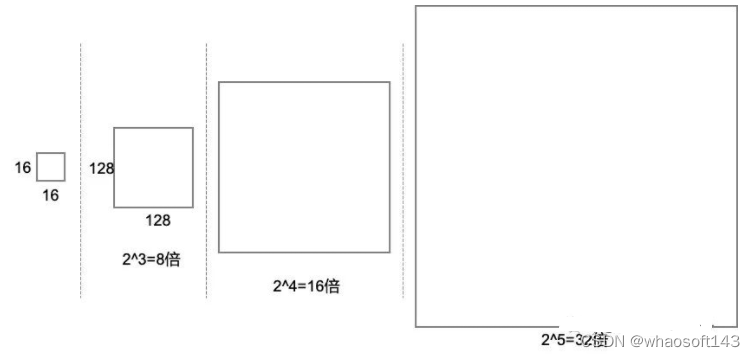
第三个参数 scales=2 ** np.arange(3, 6),指的是将各个 Anchor 放大 [8, 16, 32] 倍,得到一组新的 Anchor。如下图所示:
修改 Anchor 数量
根据上述所阐述的生成 Anchor 的尺寸和预测目标物体框的关系可知,如果我们能根据实际应用场景中目标物的大小来设计 Anchor 的尺寸,我们能在一定的程度上提高小目标物体的分类和定位精准度。而在实际应用场景中,我们会碰到一类数据集目标物的大小变化范围比较大且含有大部分的小目标物体,这种情况下,如果我们仅仅通过调节参数值修改 Anchor 的尺寸,可能不足以达到提高所有目标物的分类和定位准确度,我们还需要适当的增加 Anchor 的个数,让 Anchor 更加多尺度的来 Match 不同大小的目标物体。根据上述给出的 Anchor 生成函数可知,修改 anchor ratio 或者 anchor scale 的值的个数可以生成更多数量的 Anchor,即在实际预测过程中,会生成更多的不同尺寸的目标候选框来 Match 更多不同大小的目标物体。下面我们介绍一种在实际应用过程中的普适方法,来详细说明在不同数据集上,如何修改 Anchor 的尺寸和数量让 Anchor 机制生成更加符合实际目标物体大小的 Anchor。第一步:解析并读取目标物标注信息,计算并统计目标物体的坐标信息,代码如下:
import os
import tqdm
import xml.etree.ElementTree as ET
import config def convert_annotation(year, classes, image_name): """ :param year: str, 数据集版本(voc2012) :param classes: list, 数据集类别list :param image_name: str, 标注图片名字 :return: list, 标注框坐标信息和类别信息 """ # 获取图片对应的标注文件路径并打开 xml_file = open(os.path.join(config.PLANE_CUT_DATASET, 'VOC%s/Annotations/%s.xml' % (year, image_name))) # 使用xml读取三方包解析xml信息 tree = ET.parse(xml_file) # 遍历根目录下的所有标注信息 b = [] root = tree.getroot() for obj in root.iter('object'): # 是否是难检出目标物 difficult = obj.find('difficult').text # 标注类别名字并过滤掉不在类别list中的标注信息 cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue # 获取对应的类别id cls_id = classes.index(cls) # 获取标注框信息 bbox = obj.find('bndbox') box_info = (int(bbox.find('xmin').text), int(bbox.find('ymin').text), int(bbox.find('xmax').text), int(bbox.find('ymax').text), cls_id) # 过滤掉切图产生的空背景标注 if box_info == (1, 1, 1, 1, 0): continue else: b.append(box_info) return b def main(): # 设置数据集版本和类别等信息 sets = [('2012', 'train'), ('2012', 'val')] classes = ["plane"] wd = os.getcwd() # 遍历分别为训练集、验证集、测试集生成标注信息文件 for year, image_set in sets: # 读取数据文件信息 temp_path = 'VOC%s/ImageSets/Main/%s.txt' % (year, image_set) # 获取图像数据名字 image_names = open(os.path.join(config.PLANE_CUT_DATASET, temp_path)).read().strip().split() # 用只读模式打开标注信息记录文件 info_fp = open('%s_%s.txt' % (year, image_set), 'w') # 遍历写入每个标注文件的标注信息 for image_name in tqdm.tqdm(image_names): # 解析并读取标注文件信息,并写入文件 idx_info = convert_annotation(year, classes, image_name) if idx_info: info_fp.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg' % (wd, year, image_name)) # 将标注框坐标等信息写入文件 for box_info in idx_info: info_fp.write(" " + ",".join([str(a) for a in box_info])) info_fp.write('\n') info_fp.close() if __name__ == '__main__': main()
第二步:使用 Kmeans 方法对目标物体的统计数据进行聚类,得到每一类的中心位置信息,代码如下:
import numpy as np class KMEANS(object): def __init__(self, cluster_number, filename): self.cluster_number = cluster_number self.filename = "2012_train.txt" # 计算每个标注框和聚类中心的iou值矩阵 def iou(self, boxes, clusters): """ :param boxes: numpy array, 每个元素为每个标注框宽高 :param clusters: numpy array, 元素个数=聚类中心个数,元素为从boxes中随机选取的元素 :return: float, iou值 """ # 获取标注框个数和聚类中心数目 n = boxes.shape[0] k = cluster_number # 计算标注框面积,并让每个元素重复k遍,整理成维度为(n, k)的numpy数组 box_area = boxes[:, 0] * boxes[:, 1] box_area = box_area.repeat(k) box_area = np.reshape(box_area, (n, k)) # 计算随机挑选的聚类中心面积, 并将元素复制n遍 cluster_area = clusters[:, 0] * clusters[:, 1] cluster_area = np.tile(cluster_area, [1, n]) cluster_area = np.reshape(cluster_area, (n, k)) # 构建标注框宽矩阵和聚类中心宽矩阵 box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k)) cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k)) # 获取两个矩阵中对应元素中较小的值 min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix) # 构建标注框高矩阵 box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k)) cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k)) # 获取最两个矩阵中对应元素中较大的值 min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix) # 计算两个矩阵对应元素的内积,即计算聚类中心和每个标注框的相交面积 inter_area = np.multiply(min_w_matrix, min_h_matrix) # 计算聚类中心和每个标注框的iou值 result = inter_area / (box_area + cluster_area - inter_area) return result # 计算iou均值 def avg_iou(self, boxes, clusters): """ :param boxes: numpy array, 每个元素为每个标注框宽高 :param clusters: numpy array, 每个元素为一个聚类中心 :return: 标注矩形框和聚类中心的iou均值 """ accuracy = np.mean([np.max(self.iou(boxes, clusters), axis=1)]) return accuracy # 训练kmeans模型 def kmeans(self, boxes, k, dist=np.median): """ :param boxes: numpy array, 每个元素为每个标注框宽高 :param k: 聚类类别数目 :param dist: 聚类中心距离计算函数 :return: 聚类中心信息 """ # 获取元素个数(标注框数目) box_number = boxes.shape[0] # 随机生成一个新的numpy数组,维度为(标注框数目, 聚类数目) distances = np.empty((box_number, k)) # 生成一个0元素构成的numpy数组 last_nearest = np.zeros((box_number,)) np.random.seed() # 从box_number中,随机选取大小为k的数据 clusters = boxes[np.random.choice( box_number, k, replace=False)] # init k clusters while True: # 计算每个元素和聚类中心的"距离"(1-每个标注框和聚类中心框的iou) distances = 1 - self.iou(boxes, clusters) # 判断模型是否收敛即聚类结果不再变化 current_nearest = np.argmin(distances, axis=1) if (last_nearest == current_nearest).all(): break # 重新计算新的聚类中心 for cluster in range(k): clusters[cluster] = dist( # update clusters boxes[current_nearest == cluster], axis=0) last_nearest = current_nearest return clusters # 将计算出来的kmeans计算出来的anchor结果写入txt文件 def result_txt(self, data): """ :param data: 聚类中心数据 :return: """ f = open("yolo_anchors.txt", 'w') row = np.shape(data)[0] for i in range(row): if i == 0: x_y = "%d,%d" % (data[i][0], data[i][1]) else: x_y = ", %d,%d" % (data[i][0], data[i][1]) f.write(x_y) f.close() # 获取每个标注框的宽高信息 def get_box_info(self): # 用只读模式打开标注信息统计文件 fp = open(self.filename, 'r') box_info_list = [] # 遍历文件的每一行(每个文件)获取标注框信息并计算其宽高 for line in fp: # 按照空格分割每个标注框信息 infos = line.split(" ") length = len(infos) # 遍历每个标注框信息并计算其宽和高 for i in range(1, length): width = int(infos[i].split(",")[2]) - \ int(infos[i].split(",")[0]) height = int(infos[i].split(",")[3]) - \ int(infos[i].split(",")[1]) box_info_list.append([width, height]) # 将标注框信息list转成numpy数组并返回 result = np.array(box_info_list) fp.close() return result # 训练kmeans并获取聚类结果 def get_clusters(self): # 获取标注信息统计文件中的每个标注框的宽高 all_boxes = self.get_box_info() # 将标注框宽高信息作为kmeans训练数据,获取其聚类中心 result = self.kmeans(all_boxes, k=self.cluster_number) # 将聚类中心按照第一列进行排序 result = result[np.lexsort(result.T[0, None])] # 将聚类中心结果存入txt文件 self.result_txt(result) print("value of {} anchors:\n {}".format(self.cluster_number, result)) print("Accuracy: {:.2f}%".format( self.avg_iou(all_boxes, result) * 100)) if __name__ == "__main__": # 设置聚类中心数目和训练数据文件信息 cluster_number = 9 filename = "2012_train.txt" # 创建KMEANS类对象 kmeans = KMEANS(cluster_number, filename) # 调用类成员函数获取聚类中心、聚类中心和标注框iou准确率信息 kmeans.get_clusters()
第三步:根据聚类中心修改 Anchor 生成机制参数。
whaosoft aiot http://143ai.com