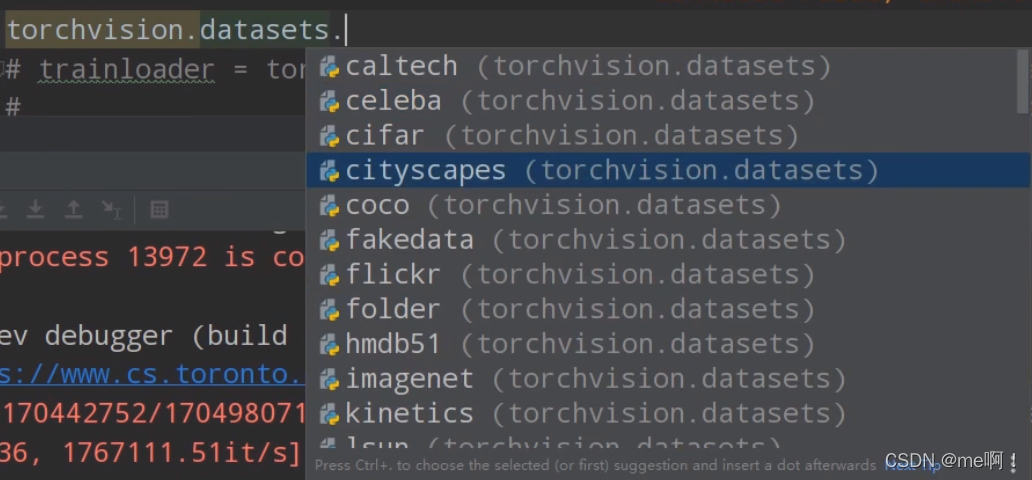
方法一:直接从官网下载,手动
GEO(GENE EXPRESSION OMNIBUS),https://www.ncbi.nlm.nih.gov/geo/,由美国国立生物技术信息中心NCBI创建维护的,是个公开的基因数据库,包含了测序和芯片数据。在前面,我们介绍过利用GEO数据库进行芯片数据检索,今天我们再进一步细化,如何利用GEO数据库下载信息。GEO数据包括五种,platforms、samples、series、datasets和profiles。
其中原始数据包括GPL、GSM和GSE。
GPL(GEOPlatform):平台信息,由芯片或测序公司提供,含有芯片或测序平台的描述信息,芯片还包含了其注释信息,每个平台列出了使用该平台的所有样本和系列。
GSM(GEO Sample):样本信息,记录单个样本的生物学信息,处理流程及该样本的原始数据(芯片或测序)。注意的是每个样本数据仅对应一个平台。
GSE(GSESeries):系列,将一项研究中所关联的GSM信息集合在一起,含研究名称、设计、概要信息。与GSM不同的是,GSE可以包含多个平台以及子系列,一个样本可以出现在多个系列中。
GDS(GEO DataSet):经挑选整理的数据集记录,如进行背景校正、均一化处理。每个GDS对应一个平台。
GEO profiles:来源与GDS数据,可以展现单个基因表达水平。
GEO测序文件存储形式包含SOFT、MINiML、Series Matrix files以及Supplementary files。
SOFT和MINiML存储的内容相同,但格式不同。SOFT为ASCII格式,MINiML为XML格式。Series Matrix files则以制表符为分隔的包含每个样本具体数值的文本文件,包含GSM和GSE。Supplementary files列出GSM原始数据或一些样本临床信息。
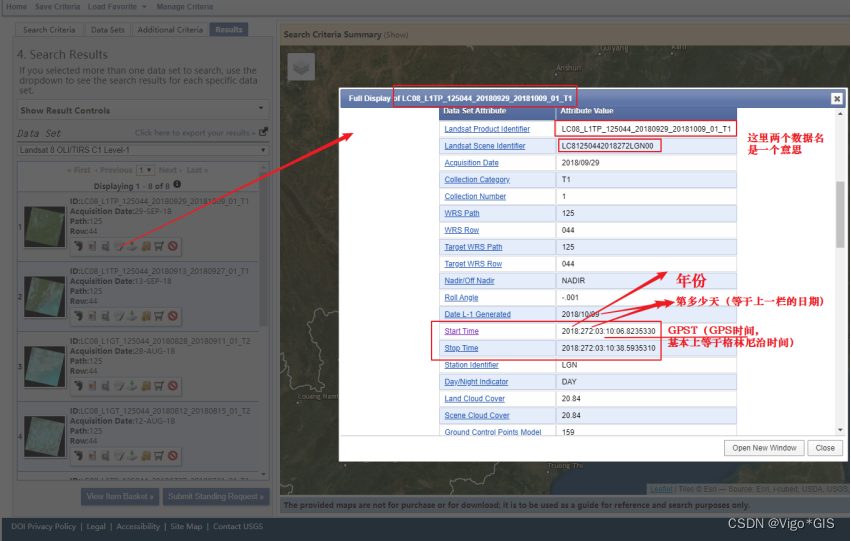
接下来我们到了我们演示环节,首先进入GEO官网。官网首页含有GEO数据库的概要,一些工具菜单,GEO数据库概况以及对于上传者的操作指南。


我们这一步需要下载两个文件:
(1)表达矩阵“series matrix”文件和(2)GPL平台注释文件。
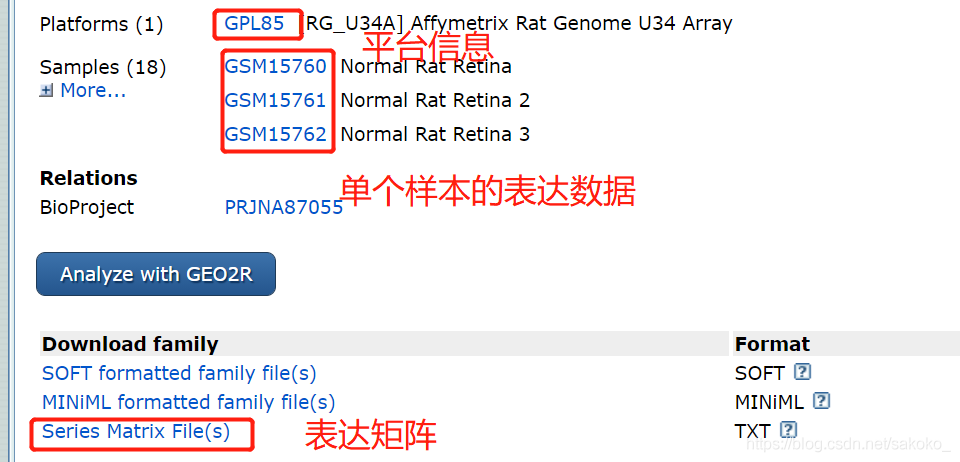

之后可以用R进行表达谱和平台数据的合并。
注意!到这里我们获得的只是初步的表达数据,还没有经过预处理,需要用R处理多个探针对应一个表达值,无对应symbol,以及合并多个探针对应一个symbol的情况后才可进行后续分析。
方法二:代码下载,自动化
我们使用的是 GEOquery 包,下来就来详细介绍一下
安装GEOquery
从 Bioconductor 安装
if (!requireNamespace("BiocManager", quietly=TRUE))install.packages("BiocManager")
BiocManager::install("GEOquery")从 GitHub 安装
library(devtools)
install_github('GEOquery','seandavi')使用
1 GEOquery 入门
从 GEO 中获取数据真的很容易。只需要一个命令: getGEO。这一个函数对其输入进行解释,以确定如何从 GEO 中获取数据,然后将数据解析成有用的 R 数据结构。
用法很简单。首先加载 GEOquery 库
library(GEOquery)现在,我们可以自由访问任何 GEO accession number。请注意,在下文中,我使用了一个与 GEOquery 包一起打包的文件。
一般来说,你只要传入正确的 GEO accession 就行,正如代码注释中所指出的那样
# 更常用的方式是传入 GEO accession,从 GEO 数据库中下载数据:
# gds <- getGEO("GDS507")
gds <- getGEO(filename=system.file("extdata/GDS507.soft.gz",package="GEOquery"))现在,gds 包含了 R 数据结构(GDS 类),表示 GEO 的 GDS507 条目。
你会注意到用于存储下载的文件名被输出到屏幕上(但没有保存到任何地方),以便以后调用 getGEO(filename=...) 时使用。
# 更常用的方式是直接传入 GSM 号,从数据库中下载:
# gds <- getGEO("GSM11805")
gsm <- getGEO(filename=system.file("extdata/GSM11805.txt.gz",package="GEOquery"))1.1 getGEO
描述
该函数是 GEOquery 包中主要的用户级函数。它引导下载(如果没有指定文件名)并将 GEO SOFT 格式文件解析为 R 数据结构,该结构是专门设计的,便于访问 GEO SOFT 格式的每个重要部分。
使用
getGEO(GEO =NULL, filename =NULL, destdir = tempdir(),GSElimits =NULL, GSEMatrix =TRUE, AnnotGPL =FALSE, getGPL =TRUE,parseCharacteristics =TRUE)参数
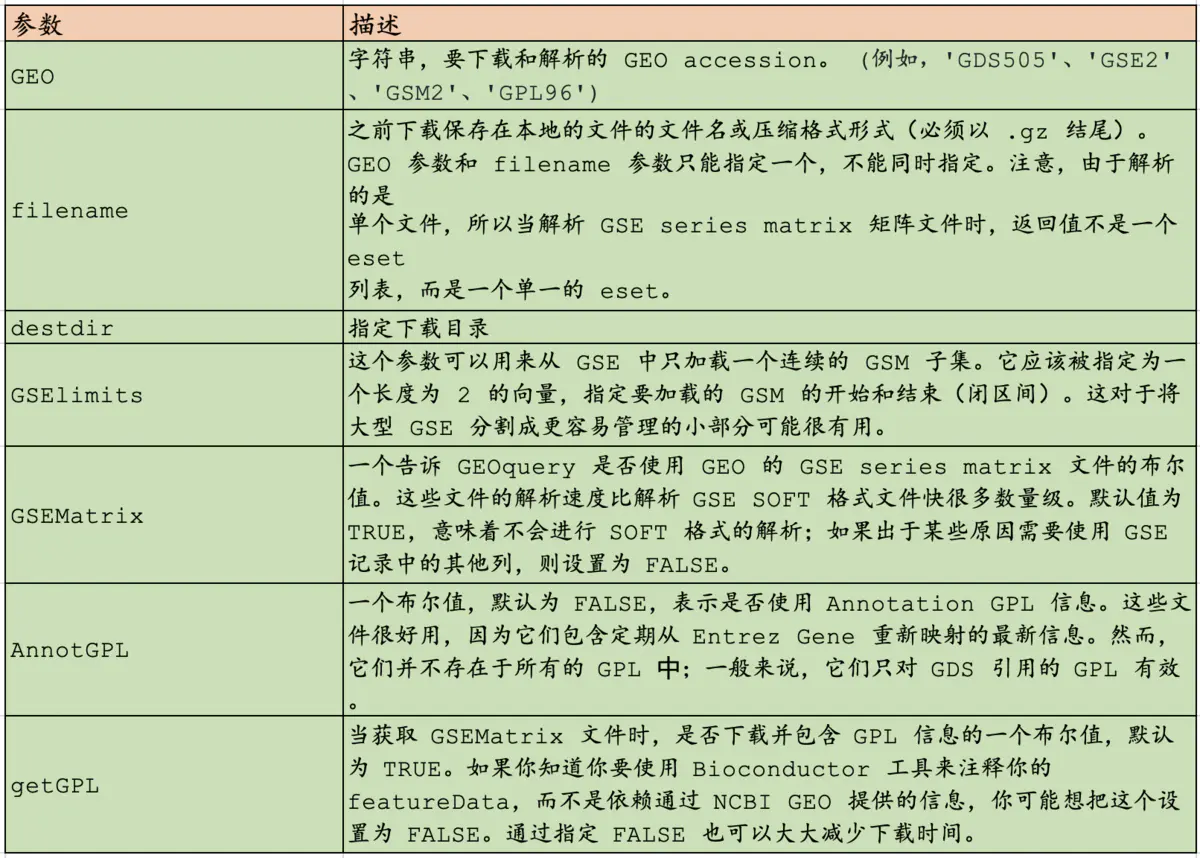
2 GEOquery 数据结构
GEOquery 的数据结构其实有两种形式。第一种,由 GDS、GPL 和 GSM 组成,它们的行为都是相似的,访问器对每一种都有相似的作用。
第四种 GEOquery 数据结构 GSE,是由 GSM 和 GPL 对象组合而成的复合数据类型。我先把前三个一起解释一下。
2.1 GDS、GSM 和 GPL 类
这些类中的每一个类都由一个元数据头(与 SOFT 格式头部信息几乎一致)和一个 GEODataTable 组成。
GEODataTable 有两个简单的部分: Columns 和 Table,Columns 部分是对 Table 部分的列的描述。此外,每个类还有一个 show 方法。
例如,对于上面的 gsm,查看元数据
> head(Meta(gsm))
$channel_count
[1] "1"$comment
[1] "Raw data provided as supplementary file"$contact_address
[1] "715 Albany Street, E613B"$contact_city
[1] "Boston"$contact_country
[1] "USA"$contact_department
[1] "Genetics and Genomics"查看与 GSM 相关的数据
> Table(gsm)[1:5,]ID_REF VALUE ABS_CALL
1 AFFX-BioB-5_at 953.9 P
2 AFFX-BioB-M_at 2982.8 P
3 AFFX-BioB-3_at 1657.9 P
4 AFFX-BioC-5_at 2652.7 P
5 AFFX-BioC-3_at 2019.5 P查看列描述
> Columns(gsm)Column Description
1 ID_REF
2 VALUE MAS 5.0 Statistical Algorithm (mean scaled to 500)
3 ABS_CALL MAS 5.0 Absent, Marginal, Present call with Alpha1 =0.05, Alpha2 =0.065GPL 类的行为与 GSM 类完全相同。然而,GDS 类的 Columns 方法保存了更多的信息。
> Columns(gds)[,1:3]sample disease.state individual
1 GSM11815 RCC 035
2 GSM11832 RCC 023
3 GSM12069 RCC 001
4 GSM12083 RCC 005
5 GSM12101 RCC 011
6 GSM12106 RCC 032
7 GSM12274 RCC 2
8 GSM12299 RCC 3
9 GSM12412 RCC 4
10 GSM11810 normal 035
11 GSM11827 normal 023
12 GSM12078 normal 001
13 GSM12099 normal 005
14 GSM12269 normal 1
15 GSM12287 normal 2
16 GSM12301 normal 3
17 GSM12448 normal 42.2 GSE 类
GSE 是 GEO 中最容易混淆的。一个 GSE 条目可以代表在任意数量的平台上运行的任意数量的样本。
GSE 类和其他类一样,有一个元数据部分,但是它没有 GEODataTable。
相反,它包含了两个列表,可以使用 GPLList 和 GSMList 方法进行访问,这两个列表分别是 GPL 和 GSM 对象的列表。
举个例子,我们从本地读取 soft 文件
gse <- getGEO(filename=system.file("extdata/GSE781_family.soft.gz",package="GEOquery"))查看元数据
> head(Meta(gse))
$contact_address
[1] "715 Albany Street, E613B"$contact_city
[1] "Boston"$contact_country
[1] "USA"$contact_department
[1] "Genetics and Genomics"$contact_email
[1] "mlenburg@bu.edu"$contact_fax
[1] "617-414-1646"获取 GSE 中包含的所有 GSM 对象的名称
> names(GSMList(gse))[1] "GSM11805" "GSM11810" "GSM11814" "GSM11815" "GSM11823" "GSM11827" "GSM11830" "GSM11832" "GSM12067"
[10] "GSM12069" "GSM12075" "GSM12078" "GSM12079" "GSM12083" "GSM12098" "GSM12099" "GSM12100" "GSM12101"
[19] "GSM12105" "GSM12106" "GSM12268" "GSM12269" "GSM12270" "GSM12274" "GSM12283" "GSM12287" "GSM12298"
[28] "GSM12299" "GSM12300" "GSM12301" "GSM12399" "GSM12412" "GSM12444" "GSM12448"获得列表中的第一个 GSM 对象
> GSMList(gse)[[1]]
An object of class "GSM"
channel_count
[1] "1"
comment
[1] "Raw data provided as supplementary file"
contact_address
[1] "715 Albany Street, E613B"
contact_city
[1] "Boston"
contact_country
[1] "USA"
contact_department
[1] "Genetics and Genomics"
contact_email
[1] "mlenburg@bu.edu"
...
****** Column Descriptions ******Column Description
1 ID_REF
2 VALUE MAS 5.0 Statistical Algorithm (mean scaled to 500)
3 ABS_CALL MAS 5.0 Absent, Marginal, Present call with Alpha1 = 0.05, Alpha2 = 0.065
****** Data Table ******ID_REF VALUE ABS_CALL
1 AFFX-BioB-5_at 953.9 P
2 AFFX-BioB-M_at 2982.8 P
3 AFFX-BioB-3_at 1657.9 P
4 AFFX-BioC-5_at 2652.7 P
5 AFFX-BioC-3_at 2019.5 P
22278 more rows ...获取所有 GPL 名称
> names(GPLList(gse))
[1] "GPL96" "GPL97"3 转换为表达谱
GEO 数据集与 limma 的 MAList 数据结构和 Biobase 的 ExpressionSet 数据结构非常相似
存在两个函数 GDS2MA 和 GDS2eSet,能够将 GEOquery 数据结构分别转换为 MAList 和 ExpressionSet
3.1 获取 GSE Series Matrix
除了解析较大的 soft 文件,我们也可以直接获取处理后的 Series matrix 文件。
getGEO 能够快速解析该类型的文件,解析返回的数据结构是 ExpressionSet 的列表
gset <- getGEO("GSE11675",destdir ='./')> show(gset)
$GSE11675_series_matrix.txt.gz
ExpressionSet (storageMode: lockedEnvironment)
assayData:12625 features,6 samples element names: exprs
protocolData: none
phenoDatasampleNames: GSM296630 GSM296635 ... GSM296639 (6 total)varLabels: title geo_accession ... data_row_count (34 total)varMetadata: labelDescription
featureDatafeatureNames:1000_at 1001_at ... AFFX-YEL024w/RIP1_at (12625 total)fvarLabels: ID GB_ACC ... Gene Ontology Molecular Function (16 total)fvarMetadata: Column Description labelDescription
experimentData: use 'experimentData(object)'pubMedIds:19855080
Annotation: GPL8300 使用 Biobase 包的函数,获取样本的表型数据
> show(pData(phenoData(gset[[1]]))[,1:5])title geo_accession status submission_date last_update_date
GSM296630 Lin-CD34- GSM296630 Public on Jan 052010 Jun 042008 Jan 052010
GSM296635 CML Lin-CD34- GSM296635 Public on Jan 052010 Jun 042008 Jan 052010
GSM296636 CML Lin-CD34+ GSM296636 Public on Jan 052010 Jun 042008 Jan 052010
GSM296637 Lin-CD34+ GSM296637 Public on Jan 052010 Jun 042008 Jan 052010
GSM296638 Lin+CD34+ GSM296638 Public on Jan 052010 Jun 042008 Jan 052010
GSM296639 CML Lin+CD34+ GSM296639 Public on Jan 052010 Jun 042008 Jan 0520103.2 将 GDS 转换为 ExpressionSet
对于上面的 gds 对象,我们可以简单地进行转换
eset <- GDS2eSet(gds,do.log2=TRUE)现在,eset 是一个 ExpressionSet 类型,它包含了 GEO 数据集信息,以及样本信息
> eset
ExpressionSet (storageMode: lockedEnvironment)
assayData:22645 features,17 samples element names: exprs
protocolData: none
phenoDatasampleNames: GSM11815 GSM11832 ... GSM12448 (17 total)varLabels: sample disease.state individual descriptionvarMetadata: labelDescription
featureDatafeatureNames:200000_s_at 200001_at ... AFFX-TrpnX-M_at (22645 total)fvarLabels: ID Gene title ... GO:Component ID (21 total)fvarMetadata: Column labelDescription
experimentData: use 'experimentData(object)'pubMedIds:14641932
Annotation:获取样本信息
> pData(eset)[,1:3]sample disease.state individual
GSM11815 GSM11815 RCC 035
GSM11832 GSM11832 RCC 023
GSM12069 GSM12069 RCC 001
GSM12083 GSM12083 RCC 005
GSM12101 GSM12101 RCC 011
GSM12106 GSM12106 RCC 032
GSM12274 GSM12274 RCC 2
GSM12299 GSM12299 RCC 3
GSM12412 GSM12412 RCC 4
GSM11810 GSM11810 normal 035
GSM11827 GSM11827 normal 023
GSM12078 GSM12078 normal 001
GSM12099 GSM12099 normal 005
GSM12269 GSM12269 normal 1
GSM12287 GSM12287 normal 2
GSM12301 GSM12301 normal 3
GSM12448 GSM12448 normal 43.3 将 GDS 转换为 MAList
由于 ExpressionSet 没有包含基因信息,所以没有检索到任何注释信息(也称为平台信息)
不过,要获得这些信息也很容易。首先,我们需要知道这个 GDS 使用的是什么平台。然后,再调用 getGEO 就可以得到我们需要的信息。
先获取 GDS 的平台
> Meta(gds)$platform
[1]"GPL97"再使用 getGEO 获取该平台的信息
gpl <- getGEO(filename=system.file("extdata/GPL97.annot.gz",package="GEOquery"))gpl 变量现在包含了来自 GEO 的 GPL97 的信息。
与 ExpressionSet 不同的是,limma MAList 是存储了基因的注释信息,我们可以在调用 GDS2MA 时将我们新创建的 GPL 结构对象 gpl 传入进去
MA <- GDS2MA(gds,GPL=gpl)查看 MA 类型信息
> class(MA)[1]"MAList"
attr(,"package")
[1]"limma"MA 是 MAList 类型,不仅包含数据,还包含与 GDS507 相关的样本信息和基因信息
3.4 将 GSE 转换为 ExpressionSet
首先,请确保使用 3.1 的方法是无法满足分析需求的。因为该方法快速且简便。
如果确实无法满足分析需求,那么可以使用下面的方法
将 GSE 对象转换为 ExpressionSet 对象需要一点点 R 基础数据操作,因为 GSE 的底层 GSM 和 GPL 对象中可以存储各种数据。
首先,我们需要确保所有的 GSM 都来自同一个平台。
> gsmplatforms <- lapply(GSMList(gse),function(x) {Meta(x)$platform_id})
> head(gsmplatforms)
$GSM11805
[1] "GPL96"$GSM11810
[1] "GPL97"$GSM11814
[1] "GPL96"$GSM11815
[1] "GPL97"$GSM11823
[1] "GPL96"$GSM11827
[1] "GPL97"这个例子包含两个平台 GPL96 和 GPL97。我们可以对 GSMlist 的结果进行过滤,提取出 GPL96 的样本
> gsmlist <- Filter(function(gsm){Meta(gsm)$platform_id=='GPL96'},GSMList(gse))
>length(gsmlist)
[1]17现在我们想知道哪一列数据是我们想要的,我们可以先查看某一个 GSM 的 Table 的前几行信息
> head(Table(gsmlist[[1]]))ID_REF VALUE ABS_CALL
1 AFFX-BioB-5_at 953.9 P
2 AFFX-BioB-M_at 2982.8 P
3 AFFX-BioB-3_at 1657.9 P
4 AFFX-BioC-5_at 2652.7 P
5 AFFX-BioC-3_at 2019.5 P
6 AFFX-BioDn-5_at 3531.5 P现在,我们知道了 VALUE 列是我们想要的,然后使用下面的代码来将这些数据转换为矩阵形式
# 先获取探针集
probesets <- Table(GPLList(gse)[[1]])$ID
# 将每个样本的 VALUE 列按列拼接起来
data.matrix <- do.call('cbind',lapply(gsmlist,function(x) {tab <- Table(x)# 我们使用 match 保证每列的探针顺序一致mymatch <- match(probesets,tab$ID_REF)return(tab$VALUE[mymatch])}))
data.matrix <- apply(data.matrix,2,function(x) {as.numeric(as.character(x))})
data.matrix <- log2(data.matrix)查看结果
> head(data.matrix)GSM11805 GSM11814 GSM11823 GSM11830 GSM12067 GSM12075 GSM12079 GSM12098 GSM12100
[1,] 10.926963 11.105254 11.275019 11.438636 11.424376 11.222795 11.469845 10.823367 10.835971
[2,] 5.749534 7.908092 7.093814 7.514122 7.901470 6.407693 5.165912 6.556123 8.207014
[3,] 7.066089 7.750205 7.244126 7.962896 7.337176 6.569856 7.477354 7.708739 7.428779
[4,] 12.660353 12.479755 12.215897 11.458355 11.397568 12.529870 12.240046 12.336534 11.762839
[5,] 6.195741 6.061776 6.565293 6.583459 6.877744 6.652486 3.981853 5.501439 6.247928
[6,] 9.251956 9.480790 8.774458 9.878817 9.321252 9.275892 9.802355 9.046578 9.414474GSM12105 GSM12268 GSM12270 GSM12283 GSM12298 GSM12300 GSM12399 GSM12444
[1,] 10.810893 11.062653 10.323055 11.181028 11.566387 11.078151 11.535178 11.105450
[2,] 6.816344 6.563768 7.353147 5.770829 6.912889 4.812498 7.471675 7.488644
[3,] 7.754888 7.126188 8.742815 7.339850 7.602142 7.383704 7.432959 7.381110
[4,] 11.237509 12.412490 11.213408 12.678380 12.232901 12.090939 11.421802 12.172834
[5,] 6.017922 6.525129 6.683696 5.918863 5.837943 6.281698 5.419539 5.469235
[6,] 9.030115 9.252665 9.631359 8.656782 8.920948 8.629357 9.526695 9.494656最后,我们将其转换为 ExpressionSet 对象
require(Biobase)
# 构建 ExpressionSet 对象
rownames(data.matrix)<- probesets
colnames(data.matrix)<- names(gsmlist)
pdata <- data.frame(samples=names(gsmlist))
rownames(pdata)<- names(gsmlist)
pheno <- as(pdata,"AnnotatedDataFrame")
eset2 <- new('ExpressionSet',exprs=data.matrix,phenoData=pheno)查看对象
> eset2
ExpressionSet (storageMode: lockedEnvironment)
assayData:22283 features,17 samples element names: exprs
protocolData: none
phenoDatasampleNames: GSM11805 GSM11814 ... GSM12444 (17 total)varLabels: samplesvarMetadata: labelDescription
featureData: none
experimentData: use 'experimentData(object)'
Annotation:4 获取原始数据
NCBI GEO 会保存有一些原始数据,如 .CEL、.CDF 等文件。有时我们想快速的获取这个文件,可以使用 getGEOSuppFiles 函数
getGEOSuppFiles 函数接受一个 GEO accession number,然后下载与其相关的所有原始数据。
默认情况下,该函数会在当前工作目录下创建一个文件夹来存储这些数据。
getGEOSuppFiles('GSE11675')获取下载的原始文件的信息
> eList <- getGEOSuppFiles('GSE11675', fetch_files =FALSE)
> eList fname url
1 GSE11675_RAW.tar https://ftp.ncbi.nlm.nih.gov/geo/series/GSE11nnn/GSE11675/suppl//GSE11675_RAW.tar下载的原始文件中包含 .CEL 或 .CDF 文件,我们可以使用 affy 或 oligo 包进行分析。
5 使用示例
GEOquery 对于快速收集大量数据来说是相当强大的,下面展示一个例子
5.1 获取给定平台的所有 Series
有时我们想对某个平台的所有 GSE 数据进行数据挖掘,使用 GEOquery 可以让这一切变得非常简单。
但在使用之前,我们需要对 GPL 记录有一些了解。
gpl97 <- getGEO('GPL97')
info <- Meta(gpl97)获取 title
> info$title
[1]"[HG-U133B] Affymetrix Human Genome U133B Array"获取 Series ID
> head(info$series_id)[1]"GSE362""GSE473""GSE620""GSE674""GSE781""GSE907"> length(info$series_id)[1]165获取样本号
> head(info$sample_id)[1]"GSM3922""GSM3924""GSM3926""GSM3928""GSM3930""GSM3932"> length(info$sample_id)[1]7917该平台共包含了 165 个 Series,样本总量为 7917。获取到了这些信息,就可以进行批量下载了。
我们以下载前 5 个样本为例,进行说明
> gsmids <- Meta(gpl97)$sample_id
> gsmlist <- sapply(gsmids[1:5], getGEO)> names(gsmlist)[1]"GSM3922""GSM3924""GSM3926""GSM3928""GSM3930"