maxcompute数据下载的三种方式
maxcoumpute下载数据有三种方式:
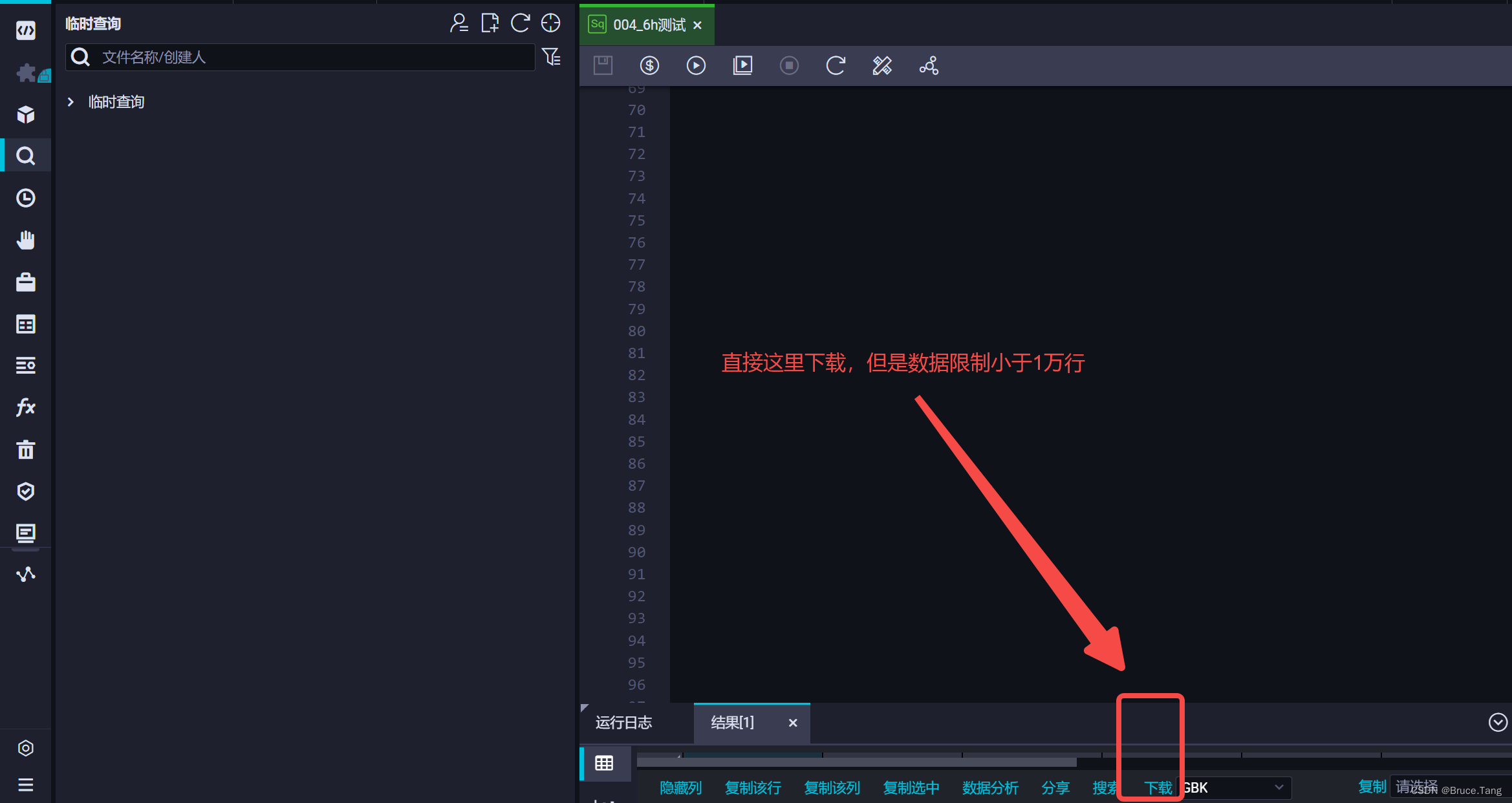
1、直接通过dataworks云端下载,但是这个只能下载小于1万行的数据;
2、通过odpscmd客户端下载,有两种方式:分区下载只能下一天数据;或者先运行dataworks(可以下多天数据),然后在odpscmd下载数据;
3、通过python下载,使用odps连接,然后下载数据,可以下载任意天数的数据,但是代码里面限制了字段,这个需要自己输入字段。
1、dataworks云端直接下载
2、odpscmd客户端下载数据
前面我们已经讲过odpscmd客户端怎么安装,如果忘记可以看下面
https://blog.csdn.net/Tanghaohao0/article/details/124867303
1、使用Tunnel下载和上传,详细的在阿里云在线文档里面都有,该方法限制只能下一个分区的数据:
https://help.aliyun.com/document_detail/27833.html
这里示范下我自己的下载命令:
tunnel download -h True -c "gbk" <项目名字>.<表名>/partition=<分区信息> D:\data\001-data\1.csv;
2、先运行dataworks(可以下多天数据),然后在odpscmd下载数据:
dataworks里面是这样的:数据太多无法下载,但是我们可以通过odpscmd的命令下载。
这里示范下我自己的下载命令:
tunnel download -h True -c "gbk" instance://<项目名字>/<id> <项目名字>.<表名>/partition=<分区信息> D:\data\001-data\1.csv;
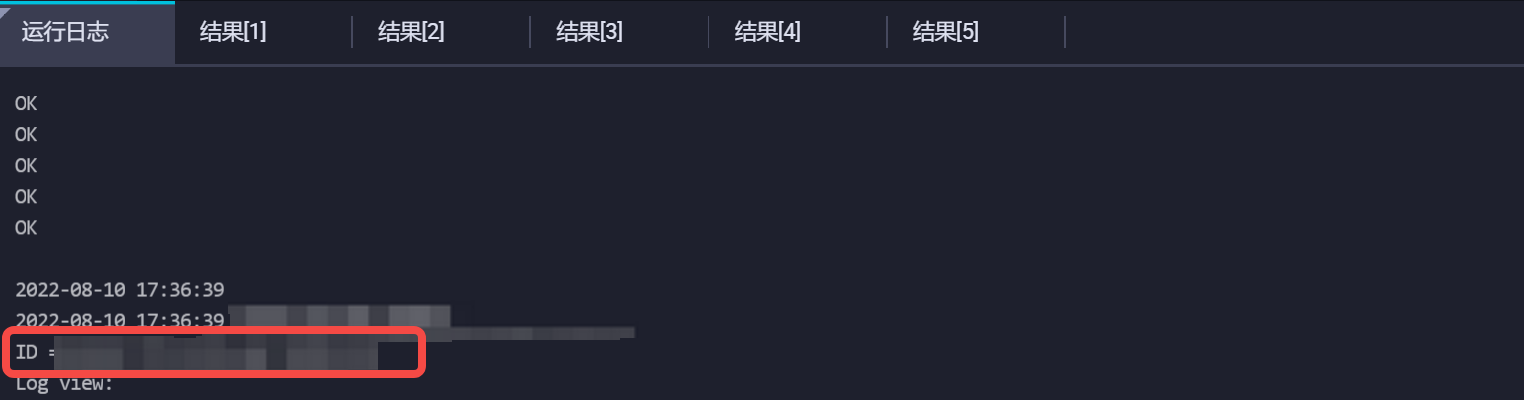
其中id通过下面方式获取
3、python连接odps下载数据
该方法可以下载任意天的数据,注意设置order limit超过1万行也执行,遇到设置order的时候就不会被限制。
示例代码如下:
from odps import ODPS
import csv
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
import smtplib
import os
import os.path
from odps import options
# --设置order limit超过10000行也执行
options.sql.settings = {'odps.sql.validate.orderby.limit': False}
dirs = "D:/data/001-data/2.csv"#将表查询数据写入到当前文件中
o = ODPS(access_id=" ",secret_access_key=" ",project=" ",endpoint=" ")
head=['s','s2']#这里是具体的想要的字段,之后通过该字段遍历数据写入到csv里面
data=[]
string_sql='''
<sql语句>
'''reader=o.execute_sql(string_sql).open_reader(tunnel=True, limit=False)
for record in reader:tmp_value=[]for name in head:tmp_value.append(record[name])data.append(tmp_value)with open(dirs,"w+",encoding="utf-8-sig",newline='') as f:csvf = csv.writer(f)csvf.writerow(head)csvf.writerows(data)print(csvf)
print('finish')