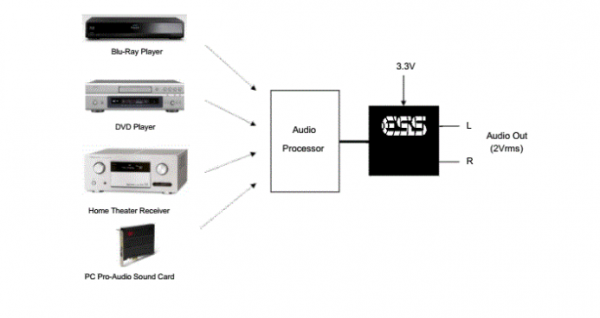
目录
项目背景
数据理解
指标维度
指标梳理
维度梳理
导入数据
数据预处理
数据格式整理
规范字段名
增加字段
简化地址
缺失值处理
异常值分析
重复值处理
数据分析
描述性统计
总体销售情况
周趋势、日趋势分析
产品价格分析
地区分析
转化率分析
总结
项目背景
本项目通过对2020年2月份淘宝真实订单成交数据的探索(共28010条记录),利用python进行数据清洗、数据可视化、数据分析,阐述销售现状、挖掘潜在规律、发现存在问题、提出可行性建议。
数据理解
数据集为2020年2月份的共28010条订单数据,存储于tmall_order_report.csv文件,有以下7个字段:
- 订单编号:共28010条
- 总金额:该笔订单的总金额
- 买家实际支付金额:实际成交金额。分为已付款和未付款两种情况:
- 已付款:买家实际支付金额 = 总金额 - 退款金额
- 未付款:买家实际支付金额 = 0
- 收货地址:维度为省市,共包含31个省市
- 订单创建时间:2020年2月1日 至 2020年2月29日
- 订单付款时间:2020年2月1日 至 2020年3月1日
- 退款金额:付款后申请退款的金额。没有申请退款或没有付过款,退款金额为0
指标维度
通过上面的字段分析可知,除了成交额作为结果指标外,还有一系列的过程指标,则需要对指标间的关系做逻辑处理。
电商的分析中最经典的公式:销售额 = UV * 转化率 * 客单价
指标梳理
- UV:一般指独立访客,在本数据集中,没有客户id作为UV数据,但我们可以把订单创建数量作为UV的数据
- 转化率:转化流程未订单创建->订单付款->订单成交->订单全额成交
- 客单价:平均每单的售价
维度梳理
- 时间:(周/日)订单创建/付款时间
- 地区:各省市
- 价格:本数据集没有单价,亦用订单总金额当成产品价格
- 产品:本数据集没有产品名称,亦用订单总金额对应唯一的产品时,总金额便可以作为产品品类的标识
- 销量:实际支付金额和成交订单数
导入数据
#导入部分库
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import plotly.graph_objs as go# PyCharm设置显示数据的行列
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width', 180)
pd.set_option('display.max_columns', 100)
pd.set_option('expand_frame_repr', False)
# 设置可显示中文,网格线
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.grid()查看数据
# 读取数据
data = pd.read_csv('C:/Users/G006696/Desktop/tmall_order_report.csv')
print(data.head(10))
数据的基本情况
print(data.info())
两个时间类型的字段数据少于20810,不适合数据类型分析,需要修改
数据预处理
数据格式整理
规范字段名
导入数据后发现有些字段名有空格,为了规范字段,将这些空格删除
data.rename(columns={'收货地址 ': '收货地址', '订单付款时间 ': '订单付款时间'}, inplace=True)
data['订单创建时间'] = pd.to_datetime(data['订单创建时间'])
data['订单付款时间'] = pd.to_datetime(data['订单付款时间'])增加字段
根据分析的需要,增加字段
data['创建时间'] = data['订单创建时间'].dt.strftime('%m月%d日')
data['付款时间'] = data['订单付款时间'].dt.strftime('%m月%d日')
# 创建函数,用来将weekday返回的数字转换为对应的星期几
def to_weekday(a):result = np.nanif a == 0:result = '周一'elif a == 1:result = '周二'elif a == 2:result = '周三'elif a == 3:result = '周四'elif a == 4:result = '周五'elif a == 5:result = '周六'elif a == 6:result = '周日'return result# 增加分析使用的字段
data['创建星期'] = data['订单创建时间'].dt.weekday.apply(to_weekday)
data['创建时刻'] = data['订单创建时间'].dt.hour
data['付款星期'] = data['订单付款时间'].dt.weekday.apply(to_weekday)
data['付款时刻'] = data['订单付款时间'].dt.hour简化地址
简化'收货地址'的省市名称,后面分析区域可以使用
data['收货地址'] = data['收货地址'].str.replace('省', '').str.replace('自治区', '')
data['收货地址'] = data['收货地址'].str.replace('壮族', '').str.replace('维吾尔', '').str.replace('回族', '')因PyCharm展示的数据格式不方便查看,导出excel后查看数整体情况
data.to_excel('C:/Users/Desktop/新增字段后的订单.xlsx')
缺失值处理
'订单付款时间'存在缺失值,缺失数量为3923 ,缺失比例为14%
print(sum(data['订单付款时间'].isnull()))
print(sum(data['订单付款时间'].isnull())/data.shape[0])检查数据
print(data[data['订单付款时间'].isnull() & data['买家实际支付金额']>0].size)结果:检查数据 0 得知'订单付款时间'为空的时候,实际付款金额都为0,没有出现错误数据.不需要对其处理
异常值分析
基本统计信息(分位数,均值,最大、最小值,标准差等)
print(data.describe())
画个箱线图辅助判断 可以看到‘总金额’>175000的数据远离上极限,且25000到175000中间都是空白,判断总金额>175000的为异常值
plt.boxplot(data['总金额'])
plt.show()
检查该异常情况的数量:‘总金额’大于175000的数据只有一条,并且没有付款,将其删除
print(data[data['总金额'] > 175000])
data = data.drop(index=data[data['总金额'] > 17500].index)画个箱线图辅助判断,'买家实际支付金额'异常值处理
plt.boxplot(data['买家实际支付金额'])
plt.show()
查看实际支付金额大于6000的数据:付款金额不是十分高,而且数量只有2,符合实际,不处理
print(data[data['买家实际支付金额'] > 6000])画个箱线图辅助判断 ,'退款金额'异常值处理
plt.boxplot(data['退款金额'])
plt.show()
查看退款金额大于2000的数据 :退款金额=总金额,没有出现数据错误,而且数量少,符合生活中的实际情况,不处理
print(data[data['退款金额'] > 2000])重复值处理
print(data.duplicated().sum())0:没有重复值,无需处理
数据分析
描述性统计
'订单付款时间'为空的代表买家没有付款,对应的'买家实际支付金额'为0的在描述性统计时应当成空值而不是0;
'退款金额'为0代表没有退款,在进行描述性统计时也应当成空值处理
#备份数据
data_desc = data.copy()
data_desc['买家实际支付金额'] = np.where(data_desc['订单付款时间'].isnull(), np.nan, data_desc['买家实际支付金额'])
data_desc['退款金额'] = data_desc['退款金额'].replace(0, np.nan)
print(data_desc.describe())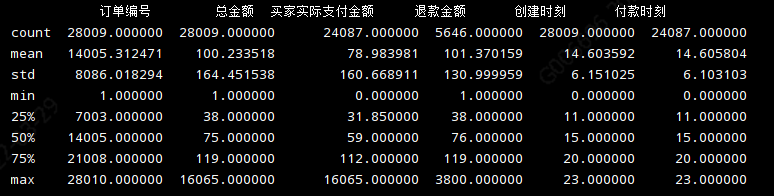
初步了解一下数据:
- 订单情况:共记录28009条订单,其中买家实际支付订单24807条(86.0%),买家有退款行为的订单5646条(占实际支付23.4%)
- 订单总金额:平均每单订单100.2元,金额最小1元,金额最大16065元
- 实际支付金额:实际支付订单平均每单79元,金额最小0元,金额最大16065元
- 退款金额:退款订单平均每单退101.4元,金额最小1元,金额最大3800元
总体销售情况
print(np.sum(data_desc['买家实际支付金额'])) 1902487.15 总销售额
GMV_day = data_desc[data_desc['付款时间'] != 'NaT'].groupby('付款时间').sum()
order_day = data_desc[data_desc['付款时间'] != 'NaT'].groupby('付款时间').count()
with pd.ExcelWriter('C:/Users/G006696/Desktop/a.xlsx') as writer:GMV_day.to_excel(writer, sheet_name='销售额')order_day.to_excel(writer, sheet_name='销售量')
绘制2020年2月销售额走势图
trace1 = go.Scatter(x=GMV_day.index, y=GMV_day['买家实际支付金额'], mode='lines', marker=dict(color='orange'), name='销售额')
trace2 = go.Bar(x=order_day.index, y=order_day['订单编号'], name='订单数', marker=dict(color='steelblue'), yaxis='y2',opacity=0.7)
layout = go.Layout(title='2020年2月销售额走势', xaxis=dict(tickangle=45, dtick=1), yaxis=dict(title='销售额(元)', zeroline=False),yaxis_tickformat='auto', yaxis2=dict(title='订单数', overlaying='y', side='right', showgrid=False),annotations=[dict(x=0.1, xref='paper', y=0.95, yref='paper', text='二月份总销售额为190.25万', bgcolor='gainsboro',font={'size': 13}, showarrow=False)],legend=dict(x=0.1, y=0.85))
trace = [trace1, trace2]
fig = go.Figure(trace, layout)
fig.show()
从上图可以得知以下消息:
- 二月份总销售额190.25万元
- 2月16日前销售额很少,仅2月4日和2月9日达到两个小高峰,22000左右
- 2月10日-2月16日销售额仅有0-1000元
- 2月17日销量逐渐增长,2月25日达到最高峰(22.8万)
- 3月1日的销售额突然骤减,仅有298元
问题分析:
- 2月初销量低可能因为春节假期导致,2020的春节放假为1月24日至2月2日,当时正至疫情开始,复工复产时间推迟至不早于2月9日24时,2月10日-2月16日正好是销售量最低迷的时间,应该是因为消费者正开始复工复产,无暇消费
- 3月1日销售额突降是因为改日订单只记录了在2月29日创建但在3月1日支付的,并不是3月1日所有的交易数据,可以忽略3月1日
建议:
- 2020年初疫情突发,导致本应在2月初春节结束恢复的销售,推迟至月中,甚至出现了日销量为0的情况。目前疫情已经常态化,应该准备多个应急方案,保证在突发事件发生时能及时举措,减少突发状况对销售的影响,如果竞争对手没有及时反应我司甚至能拔得头筹获得佳绩
周趋势、日趋势分析
绘制周销售趋势图
trace_week1 = go.Scatter(x=week_order, y=data_week_mean, name='平均销售额', marker=dict(color='orange'))
trace_week2 = go.Bar(x=week_order, y=data_week_count, name='平均订单数', opacity=0.7, yaxis='y2',marker=dict(color='steelblue'))
trace_week = [trace_week1, trace_week2]
layout1 = go.Layout(title='周趋势分析', yaxis=dict(title='销售额(元)'), yaxis2=dict(title='订单数', overlaying='y', side='right'),legend=dict(x=0.9, y=1.4), width=550, height=350)
fig1 = go.Figure(trace_week, layout1) 
绘制日销售趋势图
data_hour_count = data_desc.groupby('付款时刻').count()
data_hour_mean = data_desc.groupby('付款时刻').sum()
trace_hour1 = go.Scatter(x=data_hour_mean.index, y=data_hour_mean['买家实际支付金额'], name='销售额', marker=dict(color='orange'))
trace_hour2 = go.Bar(x=data_hour_count.index, y=data_hour_count['订单编号'], name='订单数', opacity=0.7,marker=dict(color='steelblue'), yaxis='y2')
trace_hour = [trace_hour1, trace_hour2]
layout2 = go.Layout(title='日趋势分析', yaxis=dict(title='销售额(元)'), yaxis2=dict(title='订单数', overlaying='y', side='right'),legend=dict(x=0.9, y=1.4), width=550, height=350)
fig2 = go.Figure(trace_hour, layout2)
fig2.show()
从上图我们可以得到以下消息:
- 每周销售最好的是周五,其次是周二,最差的是周一
- 周末并非预想中最好的时间,甚至比大部分工作日差
- 凌晨销量最低,从6点开始销量稳定提升,中午开始趋于稳定略有波动,在10时 15时 21时分别有一个高峰,22点后销量开始下滑
建议:
- 促销活动安排在周五开始,既可以提高原本的高销量,又可以拉到周末的消费
- 促销信息、产品推广广告的推送时间最好安排在晚上9点,此时消费人数最多,信息的曝光量最大,能带来最大的收益
- 如果有条件多次推送信息,10点、15点、21点时较好的选择
产品价格分析
因为数据集中即没有包含产品名称,也没有包含产品价格,我们姑且将订单总金额当成产品的价格,分析什么价格的产品更受消费者欢迎
绘制'总金额'直方图
sns.histplot(data_desc['总金额'])
plt.show()
总金额500以上的数据虽然很少但刻度很大,包含进来严重拉伸了图形,不利于分析
筛选总金额500以内的数据,绘制直方图查看分布
plt.figure(figsize=(20, 8), dpi=80)
sns.histplot(data_desc[data_desc['总金额'] < 500]['总金额'])
plt.xticks(np.arange(0, 525, 25), fontsize=20)
plt.yticks(fontsize=20)
plt.xlabel('订单金额', fontsize=20)
plt.ylabel('订单数', fontsize=20, rotation=0, labelpad=40)
plt.title('订单金额分布情况', fontsize=25)
plt.show()
可以看到大部分订单金额在200元以下,20-125居多
根据上图的分布,对订单总金额进行分组
price_max = data_desc['总金额'].max()
bins = [0, 20, 40, 60, 80, 100, 125, 150, 175, 200, 250, 300, 500, price_max]
price_label = ['0-20', '20-40', '40-60', '60-80', '80-100', '100-125', '125-150', '150-175', '175-200', '200-250','250-300', '300-500', '500以上']
price_cut = [pd.cut(data_desc['总金额'], bins=bins, labels=price_label).value_counts()[i] for i in price_label]
plt.figure(figsize=(20, 8), dpi=80)
sns.barplot(x=price_label, y=price_cut, palette='Blues_r')
x = [i for i in range(len(price_label))]
for i, j in zip(x, price_cut):plt.text(i, j + 60, j, horizontalalignment='center', fontdict=dict(color='steelblue', fontsize=14))plt.text(i, j - 270, '{:.1%}'.format(j / data_desc.shape[0]), horizontalalignment='center',fontdict=dict(color='darkturquoise', fontsize=14))
plt.xticks(ticks=x, labels=price_label)
plt.tick_params(pad=10)
plt.xlabel('订单金额', fontsize=12)
plt.ylabel('订单数', rotation=0, labelpad=25, fontsize=12)
plt.title('订单金额分布情况', fontsize=15)
plt.show()
- 从上图我们可以获得以下信息:
- 大部分订单订单金额在200元以下,尤其是20-125元
- 其中20-40元的订单量最大,占了总订单量的1/4
- 20元以下和175元以上的订单很少,加起来仅占总订单量的11%
- 即20-175元的订单占了订单总量的90%
建议:
- 产品推广以价格20-175元的产品为主,尤其着重推广20-40元的产品,这个价格区间的产品是消费者最喜欢消费的
地区分析
绘制条形图
data_area = data_desc.groupby('收货地址').sum()['买家实际支付金额'].sort_values(ascending=False).reset_index()
plt.figure(figsize=(20, 8), dpi=80)
sns.barplot(x='收货地址', y='买家实际支付金额', data=data_area, palette='Blues_r')
plt.ylabel('销售额', fontsize=15)
plt.title('各省市销售额情况', fontsize=20)
plt.show() 
绘制地图(html)
from pyecharts.charts import Map
from pyecharts import options as optsdata_area_list = [list(i) for i in zip(data_area['收货地址'], np.round(data_area['买家实际支付金额']))]
map = Map()
map.add('销售额', data_area_list, maptype='china', is_map_symbol_show=True) # is_map_symbol_show 是否显示标记红点
map.set_global_opts(title_opts=opts.TitleOpts(title='各省市销售额', pos_left='center'),visualmap_opts=opts.VisualMapOpts(min_=0, max_=data_desc['总金额'].max() * 10,range_color=['#D7E3EF', '#006699']),legend_opts=opts.LegendOpts(is_show=False))
map.render('map1.html')
从上面两张图我们可以知道以下信息:
- 销售额最高的省市是上海,北京、江苏、广东、浙江为第二梯队
- 销售额高的省市主要集中在东部和南部沿海,以及四川省
- 销售额最少的省市为西藏、青海、湖北、新疆、宁夏, 主要为西部地区
分析:
- 湖北此时处于疫情中心,销售额低属于情理之中
- 订单量主要分布在东部沿海较发达地区,而内陆偏远地区,即俗称的不包邮区的订单量相对较少,这与我国经济发展分布是有较大关系
建议:
- 保持优势省市的订单量
- 西南、中部以及东北地区有很大的发展潜力,建议先从这些地区开始开展促销提高销量
转化率分析
本项目中,用户行为路径为:创建订单 -> 订单付款 -> 订单成交 -> 订单全额成交
# 计算各个阶段订单数
data_create = data.shape[0]
data_pay = data_desc[data_desc['订单付款时间'].notnull()].shape[0]
data_pay_part = data_desc[data_desc['买家实际支付金额'] > 0].shape[0]
data_pay_all = data_desc[data_desc['买家实际支付金额'] == data_desc['总金额']].shape[0]
# 计算转化率
data_funnel = pd.DataFrame()
data_funnel['环节'] = ['下单', '付款', '成交', '全额成交']
data_funnel['订单量'] = [data_create, data_pay, data_pay_part, data_pay_all]
data_funnel['总体转化率%'] = np.round(data_funnel['订单量'] / data_funnel['订单量'][0], 3) * 100
data_funnel['付款订单转化率%'] = np.round(data_funnel['订单量'] / data_funnel['订单量'][1], 3) * 100
data_funnel.loc[0, '付款订单转化率%'] = np.nan
print(data_funnel) 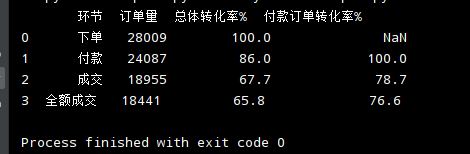
绘制总转化率漏斗
from pyecharts.charts import Funnelfunnel1 = Funnel(init_opts=opts.InitOpts(width="600px", height="400px"))
funnel1.add(series_name="转化率", data_pair=list(zip(data_funnel['环节'], data_funnel['总体转化率%'])), gap=2,label_opts=opts.LabelOpts(position='inside', formatter='{b}:{c}%'),tooltip_opts=opts.TooltipOpts(formatter='{a} <br/>{b} : {c}%'))
funnel1.set_colors(colors=['#B0CDDD', '#5C96BB', '#3470A3', '#163A69'])
funnel1.set_global_opts(title_opts=opts.TitleOpts(title='总体转化率', subtitle='相比总下单数', pos_left='center'),legend_opts=opts.LegendOpts(is_show=False))
funnel1.render('funnel1.html')
绘制付款订单转化率漏斗图
funnel2 = Funnel(init_opts=opts.InitOpts(width="600px", height="400px"))
funnel2.add(series_name="转化率", data_pair=list(zip(data_funnel['环节'][1:], data_funnel['付款订单转化率%'][1:])), sort_='none',gap=2, label_opts=opts.LabelOpts(position='inside', formatter='{b}:{c}%'),tooltip_opts=opts.TooltipOpts(formatter='{a} <br/>{b} : {c}%'))
funnel2.set_colors(colors=['#ffd460', '#ffaa64', '#ff8264'])
funnel2.set_global_opts(title_opts=opts.TitleOpts(title='付款订单转化率', subtitle='相比付款订单数', pos_left='center'),legend_opts=opts.LegendOpts(is_show=False))
funnel2.render('funnel2.html')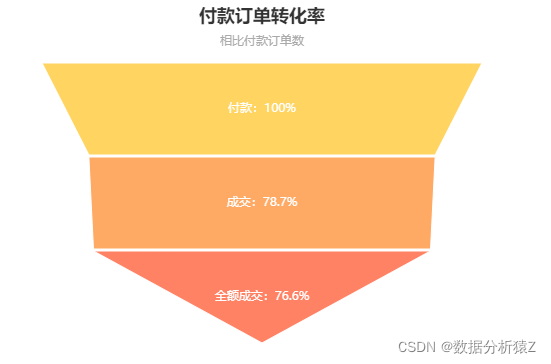
从上面的漏斗图我们可以知道:
- 下单订单的付款率为86%
- 付款订单里78.7%的订单成交
- 付款订单里76.6%的订单为全额成交,即有23.4%的订单存在退款行为
- 分析: 付款订单里23.4%的订单存在退款行为,虽然价格不高,但是商品质量或其他方面存在令人不满意的地方,加大力度整改
建议:
- 23.4%的退款率说明商品存在的问题比较严重,应尽快找出问题所在(质量不达标、实物与图片不符、尺寸与标注不符、包装不好导致商品破损、快递运输过慢、发货出错、价格高于其他店铺...)
总结
- 2月总销售额为190.25万元,由于过年快递停运和疫情原因,销售量不是很乐观
- 尽快分析高退款率的原因,针对性优化
- 促销活动可以安排在周五
- 促销信息、产品推广广告的推送时间最好安排21点,其次是10点、15点
- 产品推广以价格20-125元或20-175元的产品为主,尤其着重推广20-40元的产品
- 保持优势省市的订单量,大力发展西南、中部以及东北地区的销量