目录
1、语言表示
1.1、分布假说
1.2、语言模型
2、词向量表示
2.1、词向量表示之one-hot
2.2、词带模型之 (Bag of Words)
2.3、词的分布式表示
2.3.1 基于矩阵的分布式表示
2.3.2 基于聚类的分布式表示
2.4基于神经网络的分布式表示
2.4.1、NNLM
2.4.2、Word2Vec
2.4.3、fasttext
3、静态词向量表示方法优缺点
1、语言表示
语音中,用音频频谱序列向量所构成的矩阵作为模型的输入;在图像中,用图像的像素构成的矩阵数据作为模型的输入。这些都可以很好表示语音/图像数据。而语言高度抽象,很难刻画词语之间的联系,比如“麦克风”和“话筒”这样的同义词,从字面上也难以看出这两者意思相同,即“语义鸿沟”现象。
1.1、分布假说
上下文相似的词,其语义也相似。
1.2、语言模型
文本学习:词频、词的共现、词的搭配。
语言模型判定一句话是否为自然语言。机器翻译、拼写纠错、音字转换、问答系统、语音识别等应用在得到若干候选之后,然后利用语言模型挑一个尽量靠谱的结果。
n元语言模型:对语料中一段长度为n 的序列wn−i+1,...,wi−1,即长度小于n的上文,n元语言模型需要最大化如下似然:
![]()
wi为语言模型要预测的目标词,序列wn−i+1,...,wi−1为模型的输入,即上下文,输出则为目标词wi的分布。用频率估计估计n元条件概率:
![]()
通常,n越大,越能保留词序信息,但是长序列出现的次数会非常少,导致数据稀疏的问题。一般三元模型较为常用。
2、词向量表示
2.1、词向量表示之one-hot
1、 构建语料库
2、构建id2word的词典
3、词向量表示
例如构建的词典为:
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
则词向量表示为:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- 缺点:维度大;词与词之间是孤立的,无法表示词与词之间的语义信息!
2.2、词带模型之 (Bag of Words)
1)文档的向量表示可以直接将各词的词向量表示加和
John likes to watch movies. Mary likes too. => [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2)计算词权重 TF-IDF
IDF计算需要考虑到所有的文档,计算逆词频数
这种一般也可以统计ngram的tf-idf
2.3、词的分布式表示
分布式表示 主要分为三类:基于矩阵的分布式表示、基于聚类的分布式表示、基于神经网络的分布式表示。这三种方法使用了不同的技术手段,但是它们都是基于分布假说,核心思想也都由两部分组成:一是选择一种方式描述上下文,二是选择一种模型刻画目标词与上下文之间的关系。
2.3.1 基于矩阵的分布式表示
基于矩阵的分布表示主要是构建“词-上下文”矩阵,通过某种技术从该矩阵中获取词的分布表示。矩阵的行表示词,列表示上下文,每个元素表示某个词和上下文共现的次数,这样矩阵的一行就描述了改词的上下文分布。
常见的上下文有:(1)文档,即“词-文档”矩阵;(2)上下文的每个词,即“词-词”矩阵;(3)n-元词组,即“词-n-元组”矩阵。矩阵中的每个元素为词和上下文共现的次数,通常会利用TF-IDF、取对数等技巧进行加权和平滑。另外,矩阵的维度较高并且非常稀疏,可以通过SVD、NMF等手段进行分解降维,变为低维稠密矩阵。
eg:
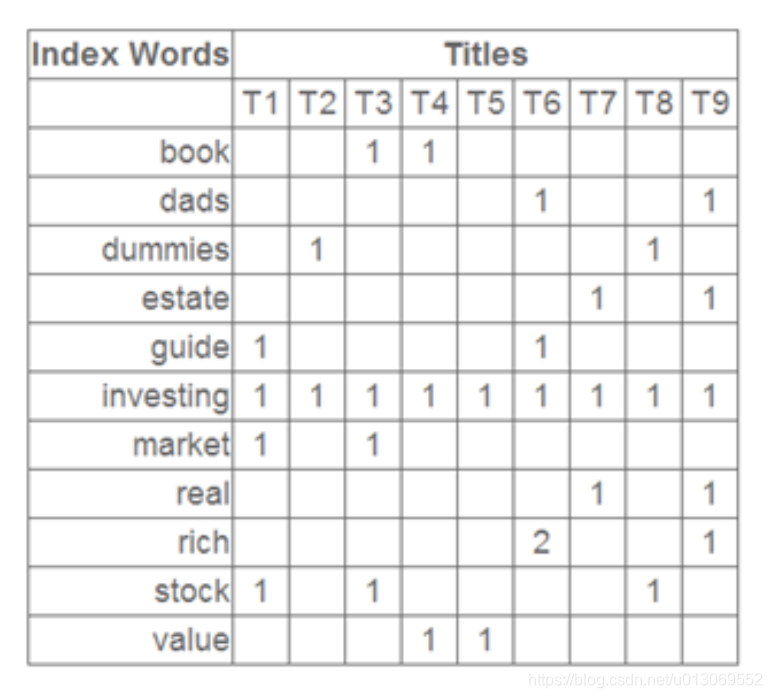
这是一个矩阵,这里的一行表示一个词在哪些title(文档)中出现了(词向量表示),一列表示一个title中有哪些词。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
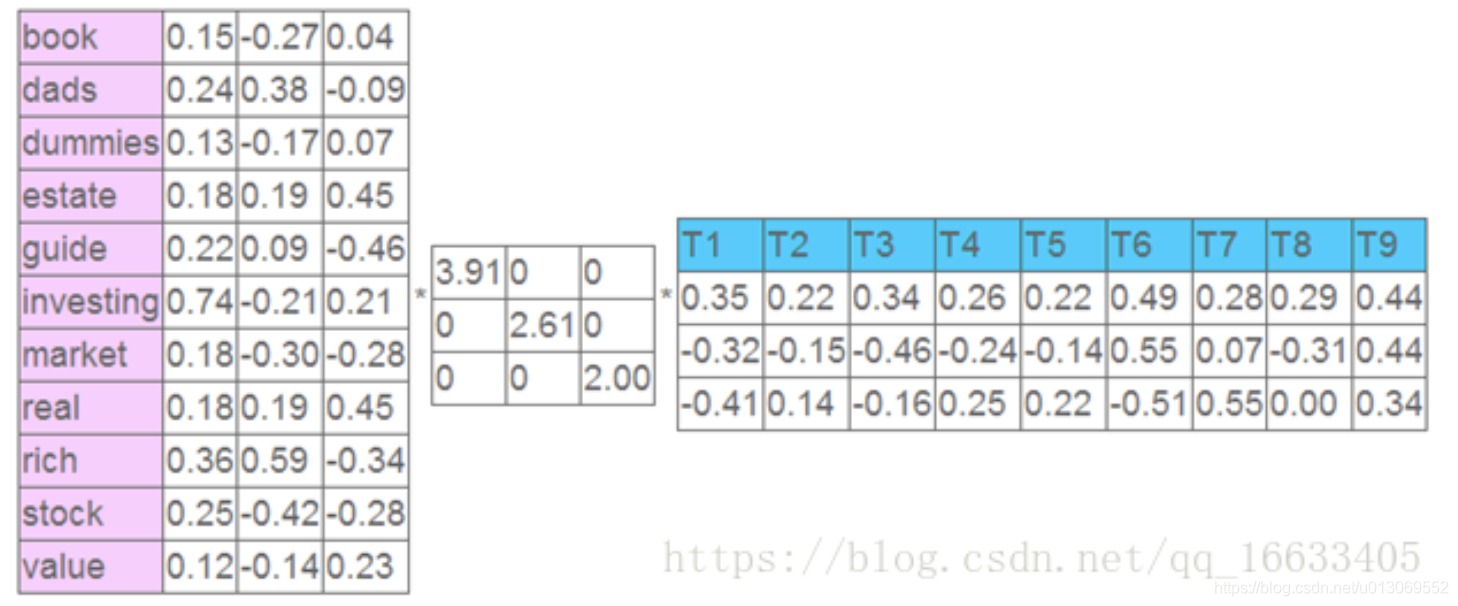
左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到(如果对左奇异向量和右奇异向量单独投影的话也就代表相似的文档和相似的词):
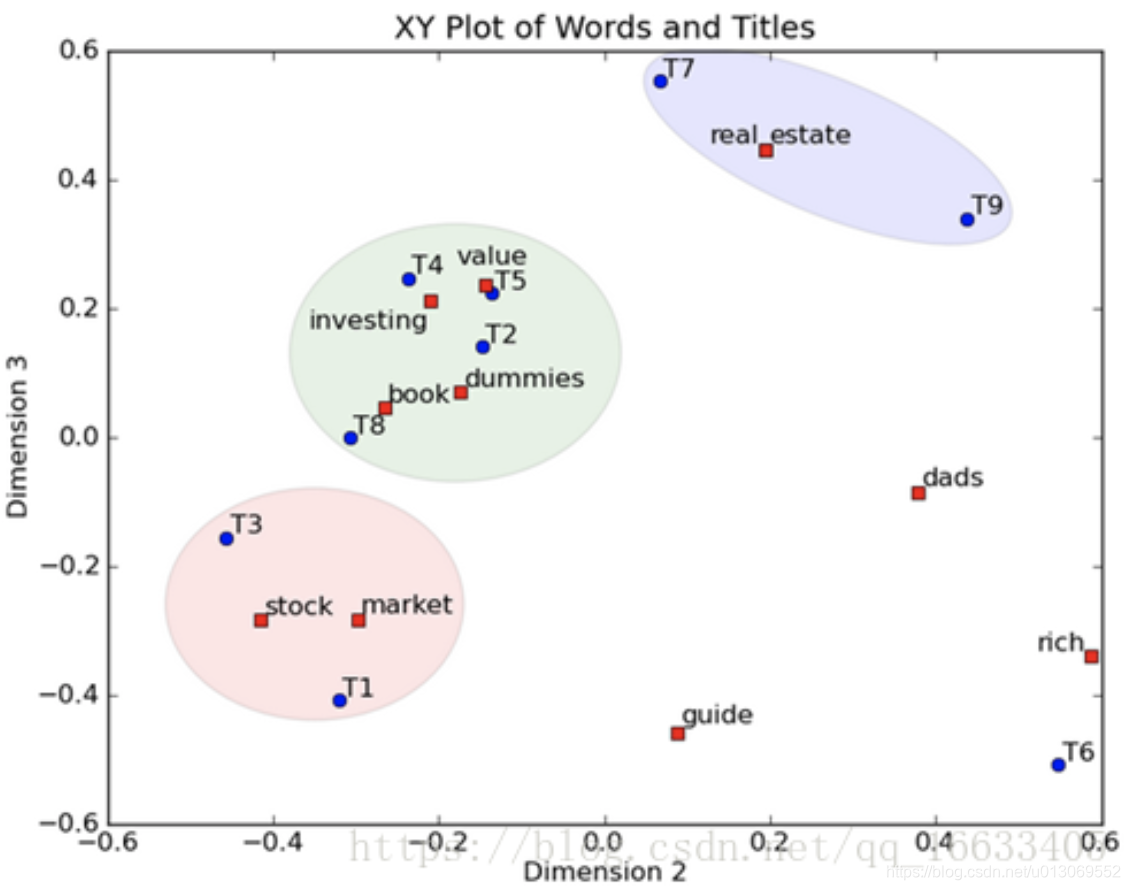
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
详细的LSI算法可以参考这篇博客https://blog.csdn.net/qq_16633405/article/details/80577851
2.3.2 基于聚类的分布式表示
这类方法通过聚类手段构建词与其上下文之间的关系。布朗聚类(Brown clustering);目前看到的是可以将相似的词聚到一个簇里面,具体的词向量表示,本人还没太理解,有待探讨。
布朗聚类原理详细解释可参考:https://zhuanlan.zhihu.com/p/158892642
https://blog.csdn.net/u014516670/article/details/50574147
2.4基于神经网络的分布式表示
2.4.1、NNLM
Bengio 神经网络语言模型(Neural Network Language Model ,NNLM)是对 n 元语言模型进行建模,估算 P(wi|wn−i+1,...,wi−1) 的概率值。与n-gram等模型区别在于:NNLM不用记数的方法来估算 n 元条件概率,而是使用一个三层的神经网络模型(前馈神经网络),根据上下文的表示以及上下文与目标词之间的关系进行建模求解,如下图:
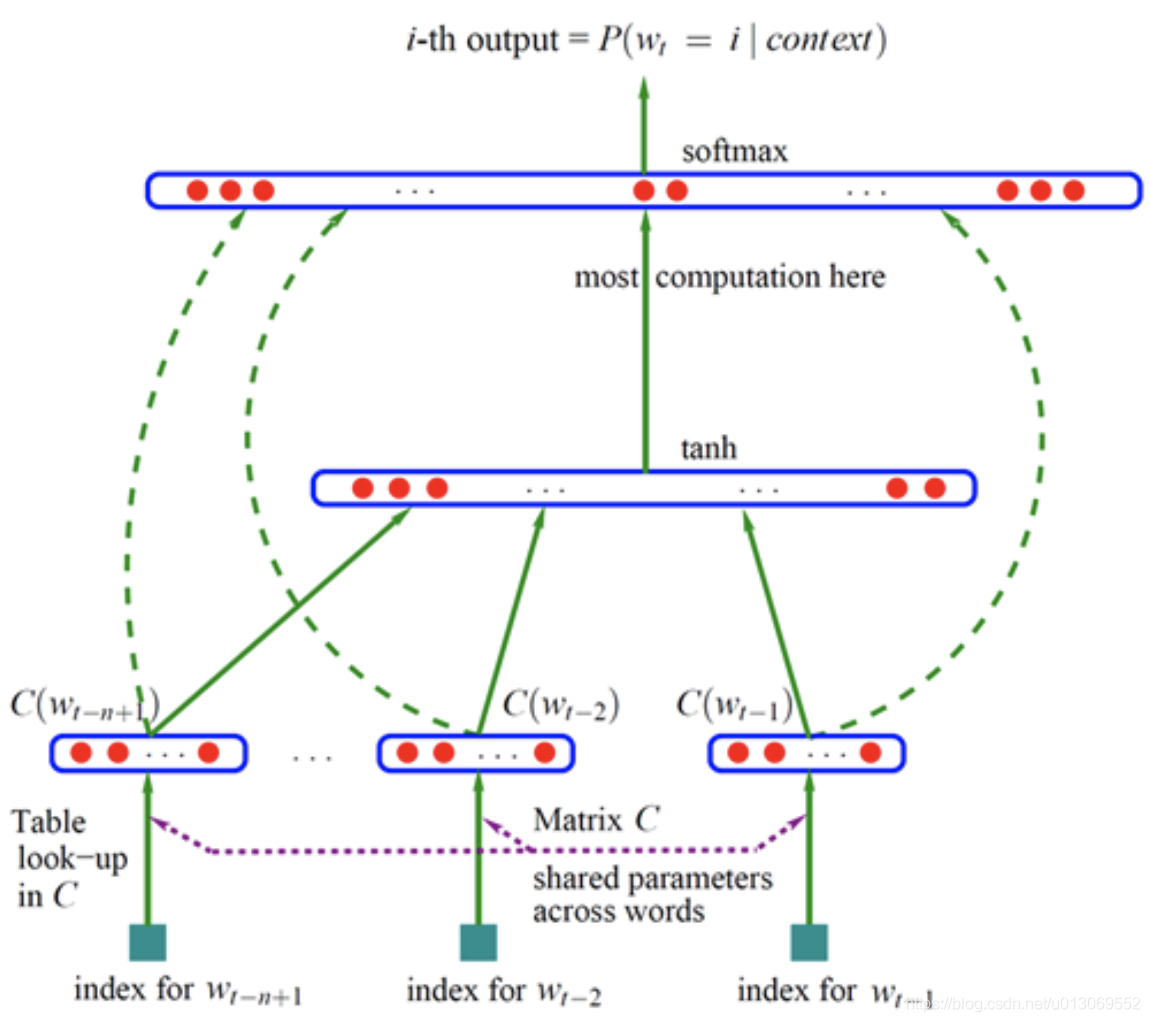
wt−1,...,wt−n+1 为 wt 之前的 n−1 个词,NNLM就是要根据这 n−1 个词预测下一个词 wt。C(w) 表示 w对应的词向量,存储在矩阵 C 中,C(w) 为矩阵 C 中的一列,其中,矩阵 C 的大小为 m∗|V|,|V| 为语料库中总词数,m 为词向量的长度。
输入层 x:将 n−1 个词的对应的词向量 C(wt−n+1),...,C(wt−1) 顺序拼接组成长度为 (n−1)∗m的列向量,用 x 表示,
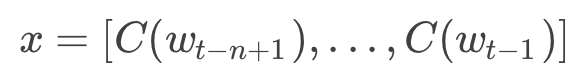
隐含层
h:使用 tanh 作为激励函数,输出
![]()
![]() 为输入层到隐藏层的权重矩阵,d 为偏置项(biases);
为输入层到隐藏层的权重矩阵,d 为偏置项(biases);
输出层
y:一共有 |V| 个节点,分量 y(wt=i) 为上下文为 wt−n+1,...,wt−1 的条件下,下一个词为 wt 的可能性,即上下文序列和目标词之间的关系,而 yi 或者 y(wt) 是未归一化 log 概率(unnormalized log-probabilities),其中,y 的计算为:
![]()
,![]() 为隐藏层到输出层的权重矩阵,b为偏置项,
为隐藏层到输出层的权重矩阵,b为偏置项,![]() 为输入层到输出层直连边的权重矩阵,对输入层到输出层做一线性变换1。由于输出层的各个元素yi之和不等于1,最后使用 softmax 激活函数将输出值 yi 进行归一化,将 y 转化为对应的概率值:
为输入层到输出层直连边的权重矩阵,对输入层到输出层做一线性变换1。由于输出层的各个元素yi之和不等于1,最后使用 softmax 激活函数将输出值 yi 进行归一化,将 y 转化为对应的概率值:
![]()
训练时使用梯度下降优化上述目标,每次训练从语料库中随机选取一段序列wi−n+1,...,wi−1作为输入,利用如下方式进行迭代:
![]()
其中,α为学习速率,θ=(b,d,W,U,H,C)。
该结构的学习中,各层的规模:
输入层:n为上下文词数,一般不超过5,m为词向量维度,10~10^3;
隐含层:n_hidden,用户指定,一般为10^2量级;
输出层:词表大小V,10^4~10^5量级;
同时,也可以发现,该模型的计算主要集中在隐含层到输出层 tanh 的计算以及输出层 softmax 的计算。
参考博客:https://blog.csdn.net/aspirinvagrant/article/details/52928361
2.4.2、Word2Vec
Word2Vec是用来生成词向量的工具,用一个一层的神经网络把one-hot形式的稀疏词向量映射称为一个K维的稠密向量的过程。为了加快模型训练速度,论文中利用了一些技巧,包括Hierarchical softmax,negative sampling, Huffman Tree等。
Word2Vec里面有两个重要的模型CBOW模型(Continuous Bag-of-Words Model)与Skip-gram模型。

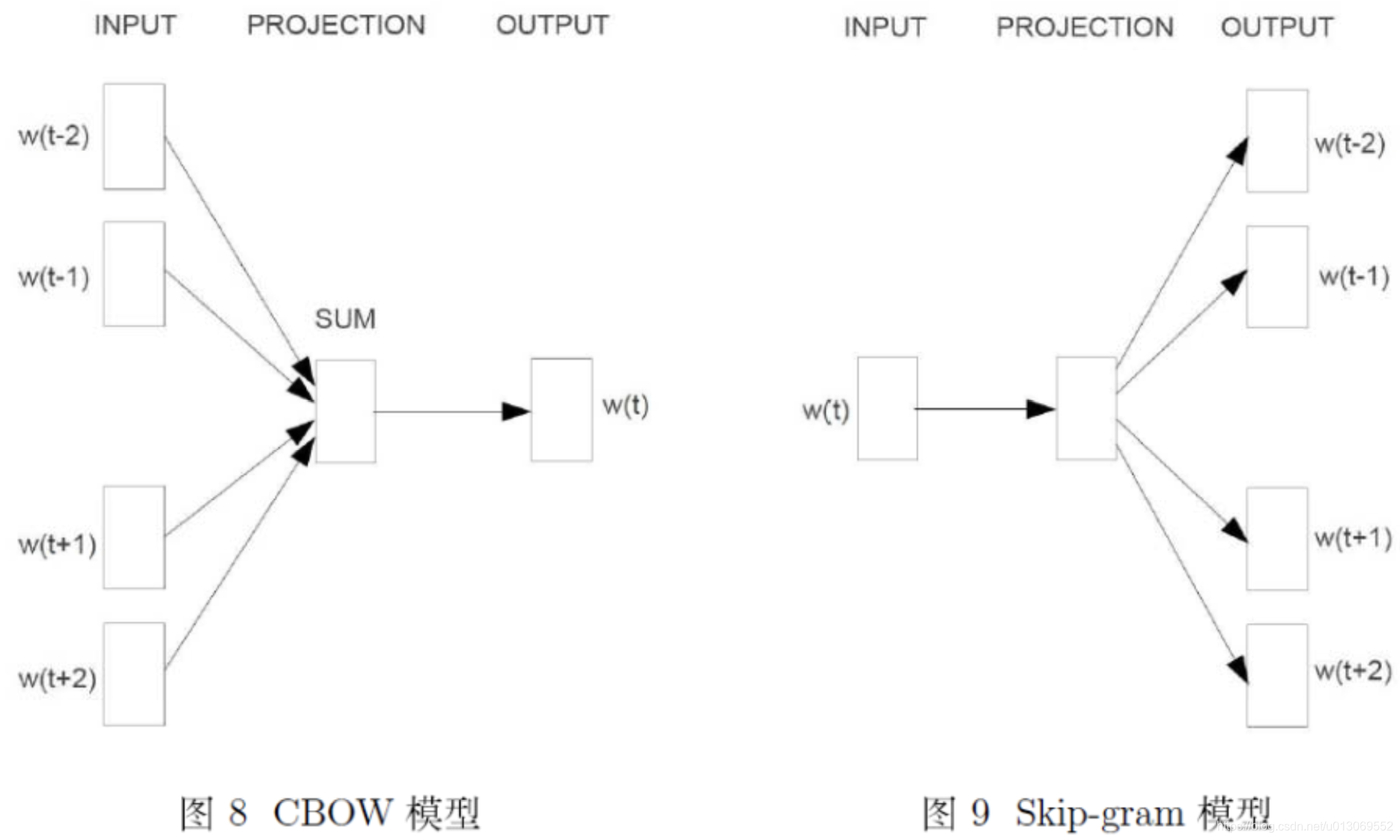
CBOW就是根据某个词前面的C个词和后面的C个连续的词,来计算某个词出现的概率。Skip-Gram是根据某个词,然后分别计算它前后出现某几个词的各个概率。
网络结构分为三层:


word2vec之cbow和skip-gram结构

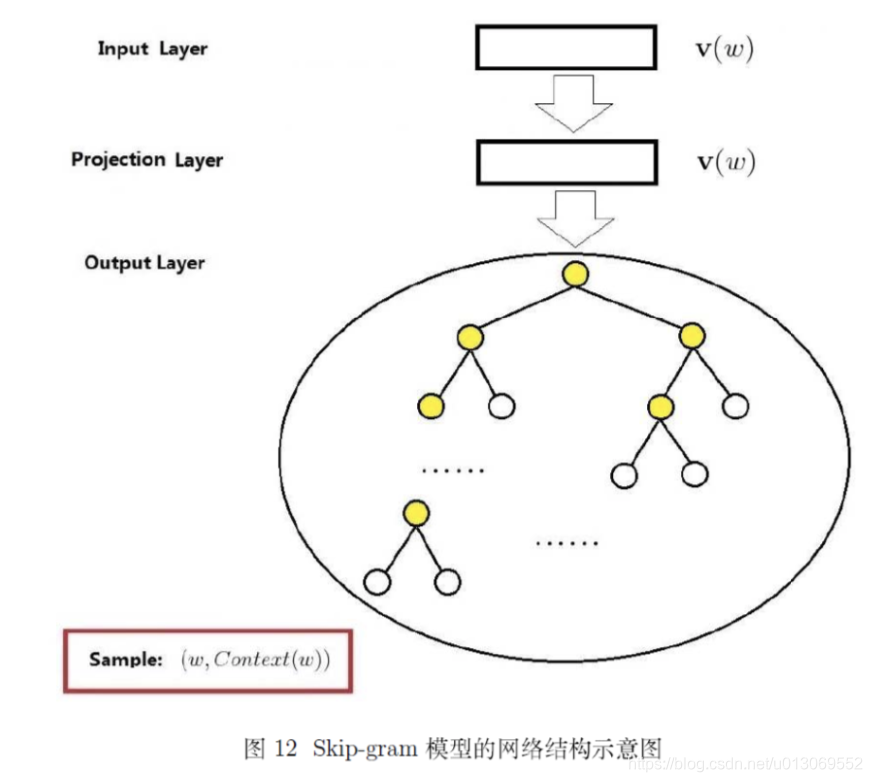
语言模型中目标函数

哈夫曼中的目标函数及梯度计算
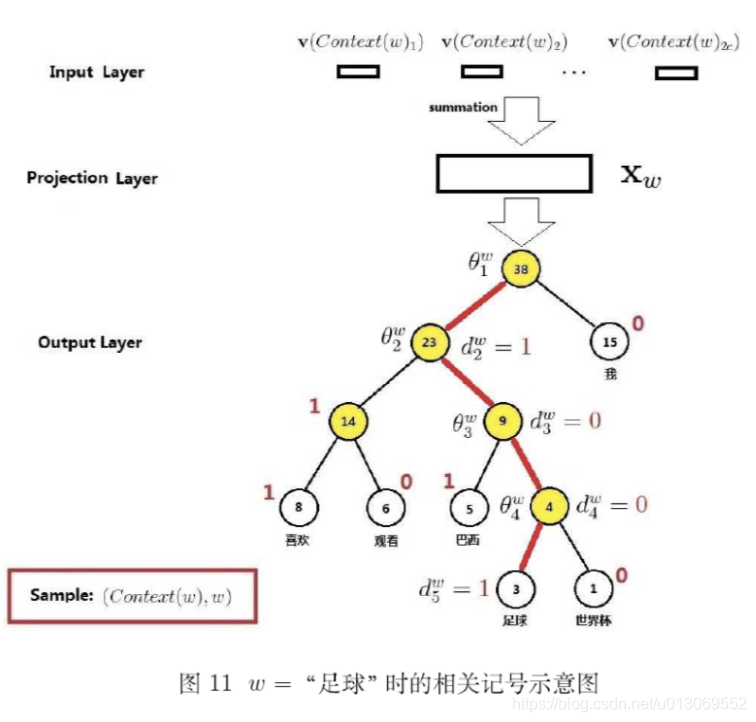

目标函数及梯度求导

负采样
word2vec中的负采样
对于cbow模型,已知上下文Context(w),需预测w;对于给定的Context(w),w就是正样本,其他的为负样本


负采样算法描述

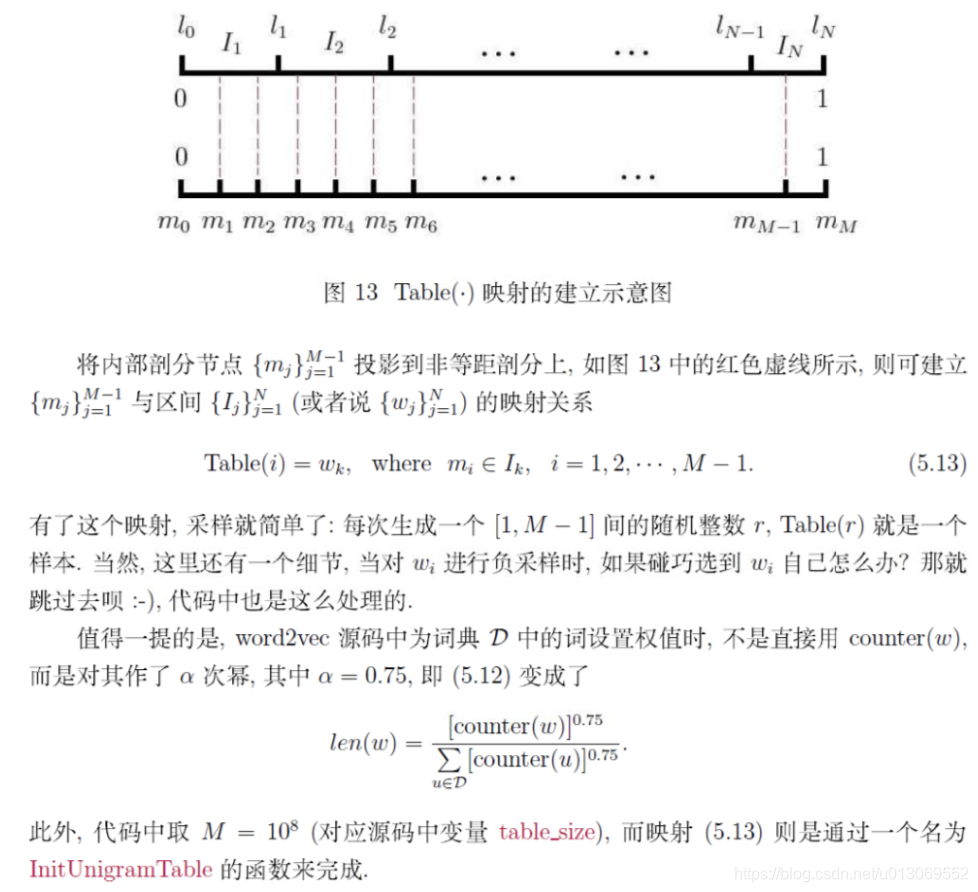
word2vec中提供了两种针对大规模多分类问题的优化手段, negative sampling 和 hierarchical softmax。在优化中,negative sampling 只更新少量负面类,从而减轻了计算量。hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度。
2.4.3、fasttext
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。
提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及n-gram袋表征语句,还有使用子词(subword)信息,并通过隐藏表征在类别间共享信息。我们另外采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。
模型架构
fastText的架构和word2vec中的CBOW的架构类似,因为它们的作者都是Facebook的科学家Tomas Mikolov,而且确实fastText也算是word2vec所衍生出来的。
- CBOW的架构:输入的是w(t)的上下文2d个词,经过隐藏层后,输出的是w(t)。
- fastText模型架构:
其中x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。 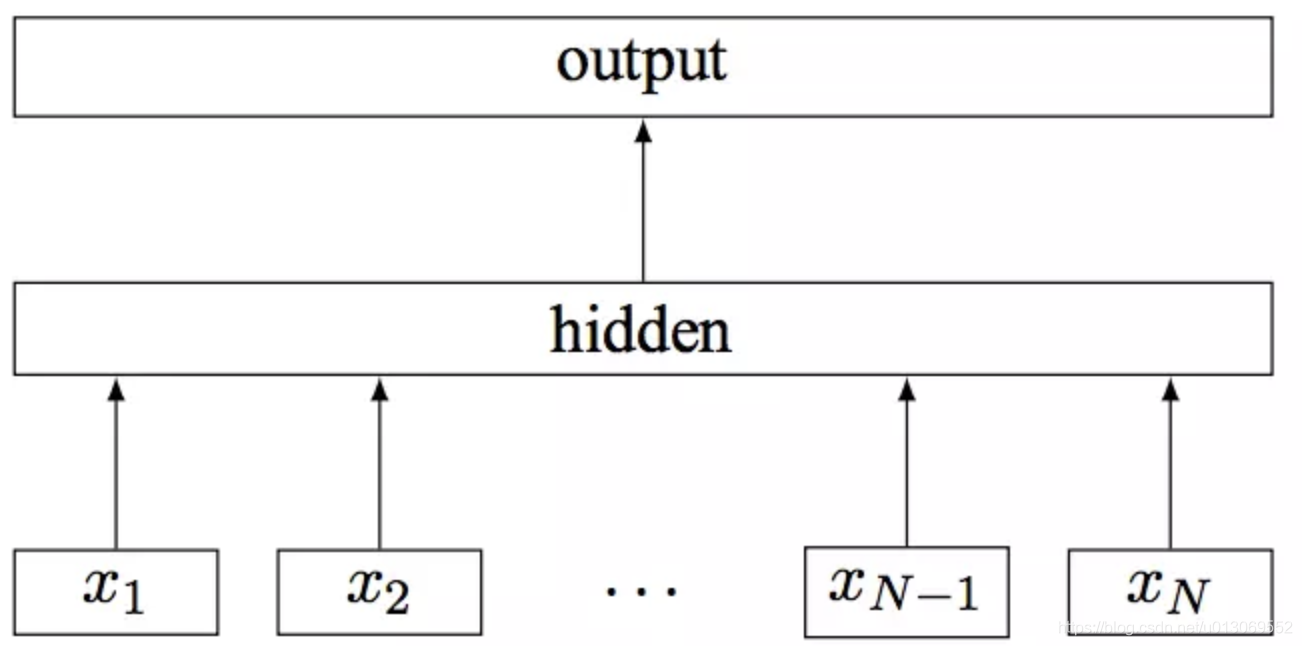
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
N-gram子词特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。在 fasttext 中,每个词被看做是 n-gram字母串包。为了区分前后缀情况,"<", ">"符号被加到了词的前后端。除了词的子串外,词本身也被包含进了 n-gram字母串包。以 where 为例,n=3 的情况下,其子串分别为<wh, whe, her, ere, re>,以及其本身 。
fastText和word2vec的区别
- 相似处:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 不同处:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
- 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
- 两者本质的不同,体现在 h-softmax的使用:
- Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax
也会生成一系列的向量,但最终都被抛弃,不会使用。 - fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
fastText是一个能用浅层网络取得和深度网络相媲美的精度,并且分类速度极快的算法。按照作者的说法“在标准的多核CPU上,能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内”。但是它也有自己的使用条件,它适合类别特别多的分类问题,如果类别比较少,容易过拟合。
3、静态词向量表示方法优缺点
one-hot;tfidf,bow:
优点:解释性强
缺点:维度大;词与词之间是孤立的,无法表示词与词之间的语义信息!
word2vec,fasttext, NNLM模型:
优点:词与词之间存在联系,可表示词与词之间的语义信息
缺点:同一个词在不同的语境下表示的含义相同
参考文献
https://zhuanlan.zhihu.com/p/46026058 (综述)
https://blog.csdn.net/aspirinvagrant/article/details/52928361 (综述 cbow和skip-gram继续看着篇)
https://www.jianshu.com/p/2a1af0497bcc (RNNLM)
https://blog.csdn.net/u014203254/article/details/104428602 (另一篇词向量综述,word2vec解释比较详细)
https://blog.csdn.net/sir_TI/article/details/89199084 (博主基于面试写的关于Word2vec的总结)
https://www.cnblogs.com/huangyc/p/9768872.html (fasttext原理综述)
https://www.infoq.cn/article/PFvZxgGDm27453BbS24W (看到词向量介绍较为详细的文章)









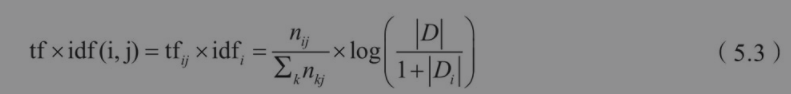

![[转]NLP关键词提取方法总结及实现](https://img-blog.csdnimg.cn/img_convert/93ef9b5a6f6c5a39c46ed8a4e2532df3.png)
