目录
一、选题意义与背景介绍 3
1.1背景介绍 3
1.2选题意义 3
二、相关方法介绍 4
2.1纹理建模 4
2.2图像重建 4
2.3图像风格迁移 4
2.3.1基于在线图像优化的慢速图像风格化迁移算法 4
2.3.2基于离线模型优化的快速图像风格化迁移算法 5
2.4图像风格迁移效果评估 6
三、具体方法介绍 7
3.1基于卷积神经网络的图片风格迁移 7
3.1.1内容图像表示 8
3.1.2风格图像表示 9
3.1.3风格转移 11
3.2基于 AdaIN 层的实时任意风格迁移 11
3.2.1背景知识介绍 12
3.2.2AdaIN 介绍 13
3.2.3网络结构 13
3.2.4 训练 14
3.2.5 灵活性 15
四、实验结果 16
4.1基于卷积神经网络的图片风格迁移 16
4.1.1相同图片不同比值 16
4.1.2相同比值不同图片 17
4.2基于 AdaIN 层的实时任意风格迁移 18
4.2.1相同图片不同比值 18
4.2.2相同比值不同图片 19
五、总结分析 20
5.1 速度 20
5.2多样性 20
5.3转换效果 21
5.3.1EC 指标 21
5.3.2评估结果 23
六、参考文献 25
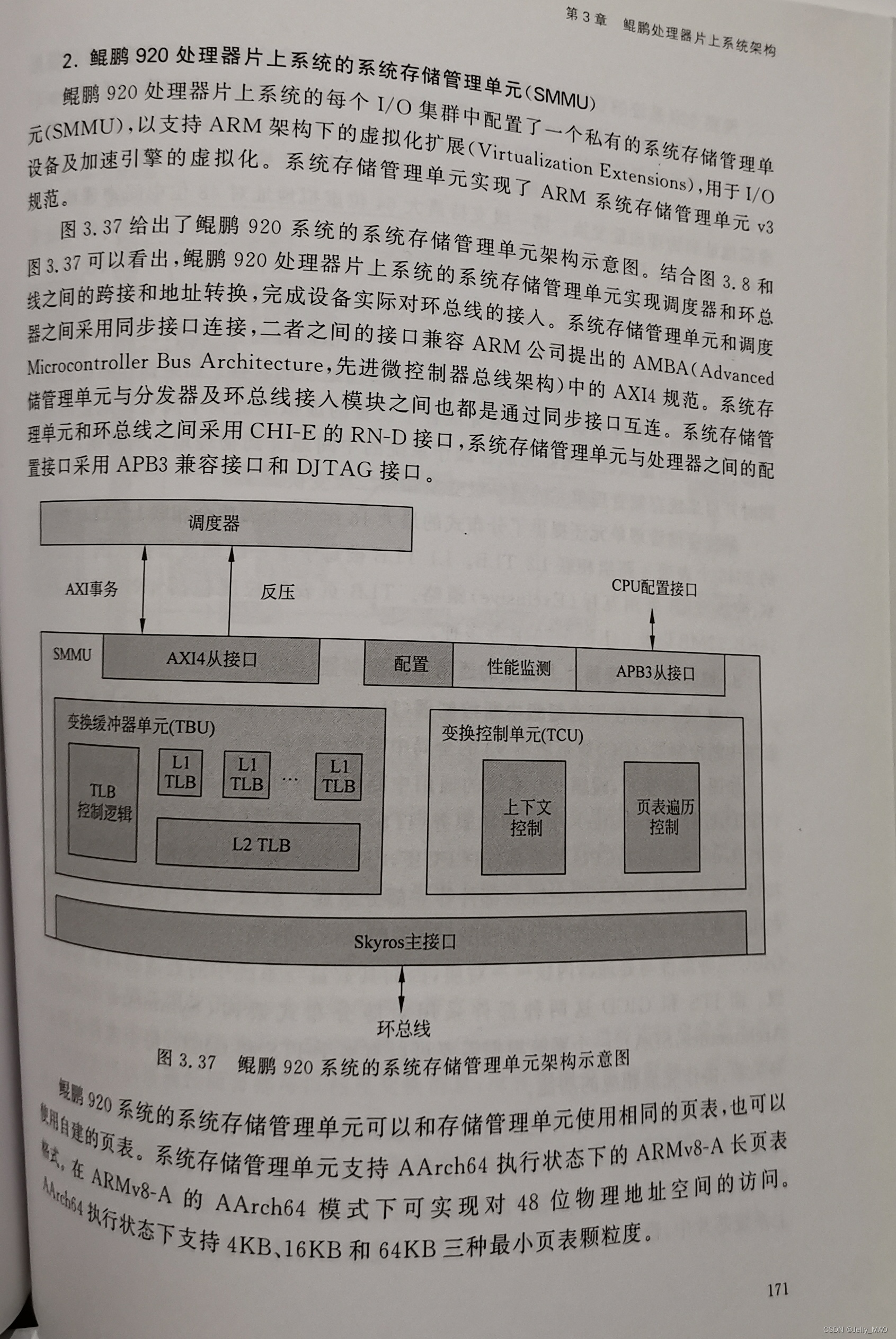
二、相关方法介绍
2.1纹理建模
纹理建模主要研究如何表示一种纹理,常用方法可以分为两大类:基于统计分布的 参数化纹理建模方法、基于 MRF 的非参数化纹理建模方法。
基于统计分布的参数化纹理建模方法主要将纹理建模为 N 阶统计量,基于 MRF 的非参数化纹理建模方法主要是用 patch 相似度匹配进行逐点合成。纹理建模解决了图片风格迁移中“如何对风格图中的风格特征进行建模和提取”的问题。
2.2图像重建
图像重建的输入是特征表达,输出是特征表达对应的图像;即把某个特征逆向重建 为原来的图像。通过重建预训练的分类网络中的高层特征,可以发现重建结果中能保留 高层语义信息,而摒弃了低层的颜色等信息。因此,我们将图像重建用于“与内容混合 然后还原成一个相应的风格化结果”。图像重建方法可以分为两类:基于在线图像优化的慢速图像重建方法、基于离线模型优化的快速图像重建方法。
基于在线图像优化的慢速图像重建方法是在图像像素空间做梯度下降来最小化目标函数,可以看作:由随机噪声作为起始图,本文转载自http://www.biyezuopin.vip/onews.asp?id=16766然后不断迭代改变图片的所有像素值来寻找一个目标结果图,这个目标结果图的特征表达和作为重建目标的目标特征表达相似。 但是由于每个重建结果都需要在像素空间进行迭代优化很多次,这个方法十分耗时。
基于离线模型优化的快速图像重建方法,这个方法就是因为第一个方法太慢了,为 了加速重建,大家希望能设计一个前向网络,提前用很多训练数据进行训练,训练过程 将一个特征表达作为输入,重建结果图像作为输出。这个训练好的网络只需要一次前向 就能输出一个结果图。
#! /usr/bin/env python3
# -*-coding=utf-8-*-import time
from scipy.misc import imsave
from scipy.optimize import fmin_l_bfgs_b
from keras import backend as K
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.models import Model
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import GlobalAveragePooling2D
from keras.layers import Input
from keras.applications.imagenet_utils import preprocess_input
from keras.engine.topology import get_source_inputs
from keras.applications.vgg19 import VGG19
import matplotlib.pyplot as plt#使用tensorflow环境编程
os=K.os
np=K.np#定义目标图像长宽将长宽同时缩小为原来图形的两倍,则矩阵缩小为原来的1/4
img_rows=400
img_columns=300
kl_array=[]
ssim_array=[]
#读入图片文件,以数组形式展开成三阶张量,后用numpy扩展为四阶张量
#最后使用对图片进行预处理:(1)去均值,(2)三基色RGB->BGR(3)调换维度
def read_img(filename):img=load_img(filename,target_size=(img_columns,img_rows))img=img_to_array(img)img=np.expand_dims(img,axis=0)img=preprocess_input(img)return img#写入/存储图片在results的文件夹中,将输出数组转换为三维张量,量化高度层BGR,并将BGR->RGB
#经灰度大小截断在(0,255)
def write_img(x,name):x=x.reshape((img_columns,img_rows,3))x[:,:,0]+=103.939x[:,:,1]+=116.779x[:,:,2]+=123.68x=x[:,:,::-1]x=np.clip(x,0,255).astype('uint8')result_file=('./result--4/%s' %name)+'.png'if not os.path.exists('./result--4'):os.mkdir('./result--4')imsave(result_file,x)
# =============================================================================
# start_time=time.time()
# kl_array.append(calc_kl(base_model,style,result_file,7777))
# ssim_array.append(calc_ssim(content,result_file))
# end_time=time.time()
# print("-Used %ds" %(end_time-start_time))
# =============================================================================print(result_file)#建立vgg19模型,本来卷基层+全连接层+输入层=19层,由于不是用于分类,没有用到全连接层,使用了no top模型
#no top模型权重大小为80.1M远远小于include top的权重574,7M
def vgg19_model(input_tensor):img_input=Input(tensor=input_tensor,shape=(300,400,3))#Blocks 1x=Conv2D(64,(3,3),activation='relu',padding='same',name='block1_conv1')(img_input)x=Conv2D(64,(3,3),activation='relu',padding='same',name='block1_conv2')(x)x=MaxPooling2D((2,2),strides=(2,2),name='block1_pooling')(x)#Block 2x=Conv2D(128,(3,3),activation='relu',padding='same',name='block2_conv1')(x)x=Conv2D(128,(3,3),activation='relu',padding='same',name='block2_conv2')(x)x=MaxPooling2D((2,2),strides=(2,2),name='block2_pooling')(x)#Block3x=Conv2D(256,(3,3),activation='relu',padding='same',name='block3_conv1')(x)x=Conv2D(256,(3,3),activation='relu',padding='same',name='block3_conv2')(x)x=Conv2D(256,(3,3),activation='relu',padding='same',name='block3_conv3')(x)x=Conv2D(256,(3,3),activation='relu',padding='same',name='block3_conv4')(x)x=MaxPooling2D((2,2),strides=(2,2),name='block3_pooling')(x)#Block 4x=Conv2D(512,(3,3),activation='relu',padding='same',name='block4_conv1')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block4_conv2')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block4_conv3')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block4_conv4')(x)x=MaxPooling2D((2,2),strides=(2,2),name='block4_pooling')(x)#Block 5x=Conv2D(512,(3,3),activation='relu',padding='same',name='block5_conv1')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block5_conv2')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block5_conv3')(x)x=Conv2D(512,(3,3),activation='relu',padding='same',name='block5_conv4')(x)x=MaxPooling2D((2,2),strides=(2,2),name='block5_pooling')(x)x=GlobalAveragePooling2D()(x)inputs=get_source_inputs(input_tensor)model=Model(inputs,x,name='vgg19')weights_path='vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5'model.load_weights(weights_path)return model#生成输入的张量,将内容,风格和迁移图像(中间量)一起输入到vgg模型中,返回三合一张量,和中间
#张量输入到VGG模型时要用到input tensor,中间计算要用到迁移图像的tensor,所以只输出这两个值
#待迁移图像初始化为一个待优化图片的占位符,初始输入为随机噪声图像,然后是一直优化的图像
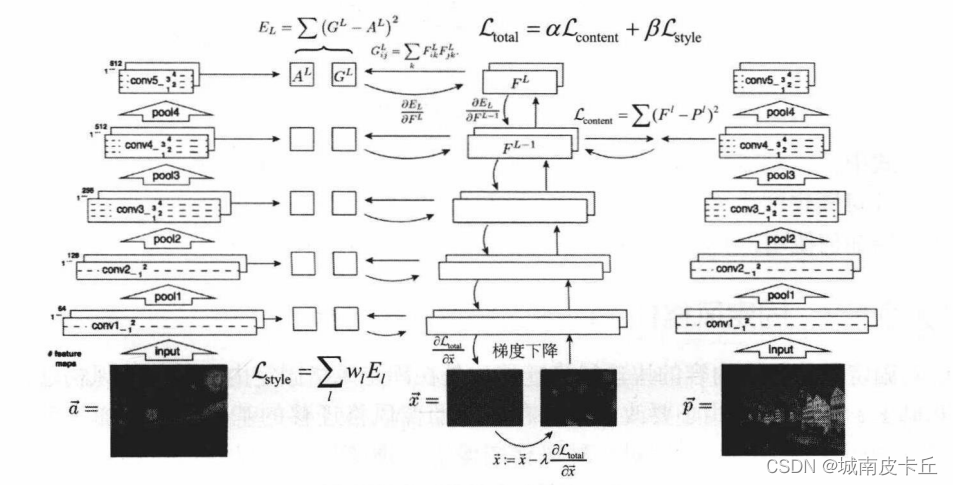
def create_tensor(content_path,style_path):content_tensor=K.variable(read_img(content_path))style_tensor=K.variable(read_img(style_path))transfer_tensor=K.placeholder((1,img_columns,img_rows,3))input_tensor=K.concatenate([content_tensor,style_tensor,transfer_tensor],axis=0)return input_tensor,transfer_tensor#设置Gram_matrix矩阵的计算图,输入为某一层的representation,Gram 矩阵表示向量组的相关性,用于求解
#迁移图像关于风格图像的loss
def gram_matrix(x):features=K.batch_flatten(K.permute_dimensions(x,(2,0,1)))gram=K.dot(features,K.transpose(features))return gram#计算风格的loss,以风格图像和迁移图像的representation为输入,分别计算gram矩阵,再求解两个Gram矩阵的
#二范数,除以归一化值
def style_loss(style_img_representation,transfer_img_representation):style=style_img_representationtransfer=transfer_img_representationA=gram_matrix(style)G=gram_matrix(transfer)channels=3size=img_rows*img_columnsloss=K.sum(K.square(A-G))/(4.*(channels**2)*(size**2))return loss#计算内容loss,输入为内容和迁移图片的presentation,输出为其reprensentation差的二范数
def content_loss(content_img_representation,transfer_img_representation):content=content_img_representationtransfer=transfer_img_representationloss=K.sum(K.square(transfer-content))return loss #变量loss,一段迷一样的表达式×-×,施加全局差正则表达式,全局差正则用于使生成的图片更加平滑自然
def total_variation_loss(x):a=K.square(x[:,:img_columns-1,:img_rows-1,:]-x[:,1:,:img_rows-1,:])b=K.square(x[:,:img_columns-1,:img_rows-1,:]-x[:,:img_columns-1,1:,:])loss=K.sum(K.pow(a+b,1.25))return loss#建立层名称到层输出张量映射的dict,便于取得各层输出feature map,分别求解style loss和content loss
#风格loss和内容loss按照10:1结合为全变量差约束
def total_loss(model,loss_weights,transfer_tensor):loss=K.variable(0.)layer_features_dict=dict([(layer.name,layer.output) for layer in model.layers])layer_features=layer_features_dict['block4_conv2']#layer_features=layer_features_dict['block2_conv2']content_img_features=layer_features[0,:,:,:]transfer_img_features=layer_features[2,:,:,:]loss+=loss_weights['content']*content_loss(content_img_features,transfer_img_features)feature_layers=['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']for layer_name in feature_layers:layer_features=layer_features_dict[layer_name]style_img_features=layer_features[1,:,:,:]transfer_img_features=layer_features[2,:,:,:]#loss+=(loss_weights['style']/len(feature_layers))*(style_loss(style_img_features,transfer_img_features))loss+=loss_weights['style']*0.2*(style_loss(style_img_features,transfer_img_features))loss+=loss_weights['total']*total_variation_loss(transfer_tensor)return loss#通过K.gradient获取反向梯度,同时得到梯度和损失,
def create_outputs(total_loss,transfer_tensor):gradients=K.gradients(total_loss,transfer_tensor)outputs=[total_loss]if isinstance(gradients,(list,tuple)):outputs+=gradientselse:outputs.append(gradients)return outputs#计算输入图像的关于损失函数的梯度值和对应损失值
def eval_loss_and_grads(x):x=x.reshape((1,img_columns,img_rows,3))outs=outputs_func([x])loss_value=outs[0]if len(outs[1:])==1:grads_value=outs[1].flatten().astype('float64')else:grads_value=np.array(outs[1:]).flatten().astype('float64')return loss_value,grads_value#获取评价程序,将获取计算loss和gradients的函数
class Evaluator(object):def __init__(self):self.loss_value=Noneself.grads_value=Nonedef loss(self,x):loss_value,grads_value= eval_loss_and_grads(x)self.loss_value=loss_valueself.grads_value=grads_valuereturn self.loss_valuedef grads(self,x):grads_value=np.copy(self.grads_value)self.loss_value=Noneself.grads_value=Nonereturn grads_value#main函数
if __name__=='__main__':print('Welcom to Our Style-transfer!')#base_model = VGG19(include_top=False,weights='imagenet')#输入图片路径path={'content':'./image/content-img/content-2.jpg','style':'./image/style-img/style-5.jpg'}#path={'content':'./image/content-img/content-1.jpg','style':'./image/style-img/style-2.jpg'}input_tensor,transfer_tensor=create_tensor(path['content'],path['style'])#用来计算总loss的系数#loss_weights={'style':1.0,'content':0.0001,'total':1.0}#loss_weights={'style':1.0,'content':0.001,'total':1.0}#loss_weights={'style':1.0,'content':0.01,'total':1.0}#loss_weights={'style':1.0,'content':0.5,'total':1.0}loss_weights={'style':0.001,'content':0.0005,'total':1e-4}model=vgg19_model(input_tensor)#生成总的反向特征缺失totalloss=total_loss(model,loss_weights,transfer_tensor)#生成正向输出outputs=create_outputs(totalloss,transfer_tensor)#获取计算图(反向输入图)outputs_func=K.function([transfer_tensor],outputs)#生成处理器evaluator=Evaluator()#生成噪声x=np.random.uniform(0,225,(1,img_columns,img_rows,3))-128#x=img_to_array(load_img(path['content'],target_size=(img_columns,img_rows)))#x=img_to_array(load_img(path['style'],target_size=(img_columns,img_rows)))#迭代训练15次for ordering in range(150):print('Start:',ordering+1)start_time=time.time()x,min_val,info=fmin_l_bfgs_b(evaluator.loss,x.flatten(),fprime=evaluator.grads,maxfun=20)print('Current_Loss:',min_val)img=np.copy(x)name=path['content'][-5]+'and'+path['style'][-5]+'-'+str(ordering+1).zfill(2)#write_img(img,name,path['content'],path['style'],base_model)write_img(img,name)end_time=time.time()print("%s" %name,"-Used %ds" %(end_time-start_time))# =============================================================================
# x=np.array(range(200))
# y1=np.array(kl_array)
# y2=np.array(ssim_array)
# plt.plot(x,y1)
# plt.plot(x,y2)
# plt.show()
# =============================================================================