学习随笔,仅记录值得留意的点。
协同过滤的适用领域
PS:适用协同过滤的场景并不一定完全符合下述要求,只是如果下述条件符合会更适合使用CF
数据要求
1、item数量足够多
2、每个item有足够多的评分
3、每个用户对较多数量的item给出了评分。如果一个用户只对一个item进行了评分,那我们就无法获得item之间相关联的信息。
4、用户评分的数量要比item数量大得多。例如当用户评论稀疏时,我们就需要更多用户来弥补这一缺陷;再举个实际例子,谷歌搜索所索引了的网页数量比全球人口还要多,因此用户无法对item(此处为网页)给出足够的评分。当用户数量不足时,推荐系统的推荐置信度就会降低。
用户评分具有长尾特点,即大部分评分都集中到部分item,很多item是缺少评分的。文中提到了这一现象,但没有给出解决方案
潜在假设
1、社区中每个用户都有相似口味的用户
2、item的评价指标是偏个性化的。虽然有时候在个性化推荐时考虑一些客观的评价指标也会有帮助,但是如果可以仅仅使用某种客观的评价指标来评估item,例如搜索引擎,CF并不是很适合。
3、用户对item的兴趣并不会快速发生变化,例如对于书籍、电影和电子产品。一个反面例子是衣服,使用一个用户五年前的数据大概率不能反应他现在的兴趣
对比协同过滤(CF)与基于内容的过滤(CBF)
1、Collaborative filtering 的假设:口味相似的用户会对相同的item有相近的评分;
2、Content-based Filtering 的假设:同一个用户对于具有相似内容的item会给出相近的评分;
3、两者可以互补。协同过滤需要评分数据,因此对新的item无能为力,而基于内容的过滤则可以解决这一问题;然而,有些场景下,item的内容很难获得或者表示出来,例如电影或者音乐。
博主注:现在深度推荐模型中利用side info来解决冷启动的思路其实就类似于基于内容的过滤
4、人们普遍认为,CF对比于CBF更能给出具有多样性、让用户意外但符合用户的潜在需求的item
协同过滤的分类
非概率模型
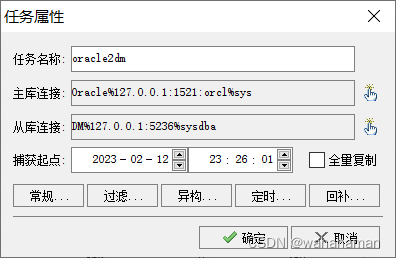
给定一个user-item的二维评分表,我们需要利用已有的评分数据来预测其中缺失的评分。例如下图中的X(用户3对于Speed的评分)即为需要预测的评分。

1、基于用户的CF:通过评分数据计算用户的相似度,然后使用其他用户对于该item的评分的加权和作为预测,权重即为目标用户与其他用户的相似度。例如上面的例子中,需要使用其他用户对于Speed的评分(分别是4、5、3)来加权求和。
2、基于item的CF:通过评分数据计算item的相似度,然后使用该用户对于其他item的评分的加权和作为预测,权重即为目标item与其他item的相似度。例如上面的例子中,需要使用用户3对于其他item的评分(对《The Matrix》评分为3,对《Sideways》评分为4),即3和4来做加权求和。
PS:基于用户的CF和基于item的CF在定义相似度时都有一些变种,但是这两类方法都已经不是主流,此处不再详细介绍。
但个人感觉值得一提的一个比较有意思的设计思路:
不同用户的评分偏好不同,即有些用户更偏向于给低分,而另外一些用户偏向于给高分。举个例子,平时偏好打低分的用户这次给一部电影打了中等偏上的分数,可能是等价于一个偏好打高分的用户给该电影打了近乎满分的。为了缓和这一现象,计算评分时使用评分减去该用户的平均评分
3、基于关联规则的CF。过时方法,不介绍。
4、基于矩阵分解的CF。值得了解的方法,但不在此处介绍,见其他博文。
概率模型
决策树
一些设计细节
显式评分与隐式评分
显式评分即用户直接给出的打分,例如从1到5的评分。隐式评分指的是能够间接反应用户对于该item的兴趣程度的值,例如用户在浏览一件物品时停留的时间。显示评分更加精确地反映用户的兴趣,但获取成本更高,隐式评分更容易获取,但这些数据的不确定性更大,会导致推荐系统的置信度更低
评分尺度
评分尺度需要适宜,过小的尺度会导致区分度不够大,从而损失部分信息;而过大的尺度(例如从1到100)会导致更大的不确定性,例如你在隔天再问一次,用户可能会给出不一样的数值。
冷启动问题
用户冷启动的解决思路:
1、给用户推荐热门的item而非个性化的item,或者询问偏好(例如喜欢的音乐风格、电影类别),然后推荐该类别的热门item
2、根据用户的基本信息,推荐与其相似的用户喜欢的item
商品冷启动的解决思路:主要是使用基于非协同过滤的方法,例如基于item的内容或者元数据的相似性来进行推荐。
阅读感受
挺旧的一篇文章,大部分东西都过时了,但其中一些思想倒是一直在沿用,例如基于内容来解决冷启动问题。学习经典方法的意义在于领会其中的设计思想,在推荐领域尤其如此。








![django mysql数据同步_[django自动同步数据库]Django数据库同步操作技巧详解](https://img-blog.csdnimg.cn/img_convert/91b2c85c7c570533194813c938c932ec.png)