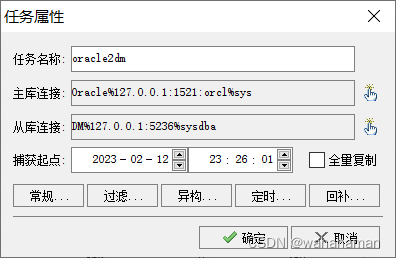
Otter工作原理
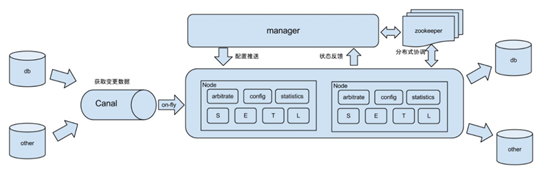
原理描述:
- 基于Canal开源产品,获取数据库增量日志数据。
- 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上 - 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
4.db : 数据源以及需要同步到的库
Otter能解决什么问题?
- 1、异构库同步
Otter支持从Mysql同步到Mysql/oracle,我们可以把mysql同步到oracle
2、单机房同步
可以作为一主多从同步方案,对于单机房内网来说效率非常高,还可以做为数据库版本升级,数据表迁移,二级索引等这类功能
3、异地机房同步
异地机房同步可以说是Otter最大的亮点之一,可以解决国际化问题把数据从国内同步到国外来提供用户使用,在国内场景可以做到数据多机房容灾
4、双向同步
双向同步是在数据同步中最难搞的一种场景,Otter可以很好的应对这种场景,Otter有避免回环算法和数据一致性算法两种特性,保证双A机房模式下,数据保证最终一致性
5、文件同步
站点镜像,进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片
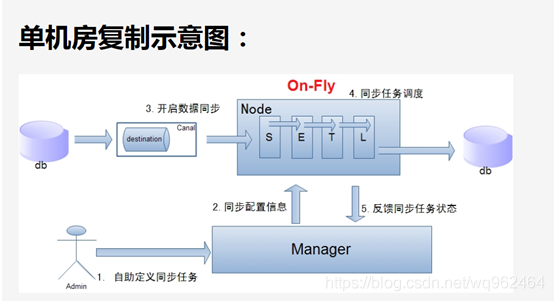
说明:
a. 数据on-Fly,尽可能不落地,更快的进行数据同步. (开启node loadBalancer算法,如果Node节点S+ETL落在不同的Node上,数据会有个网络传输过程)
b. node节点可以有failover / loadBalancer.
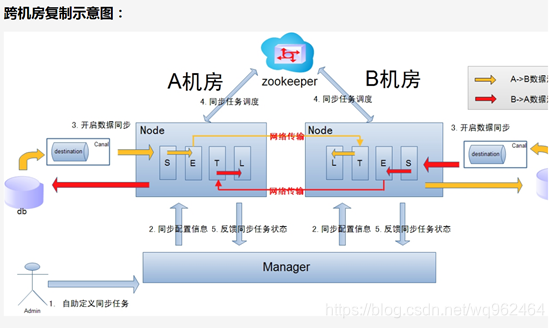
说明:
a. 数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node)
b. node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)
二、Manager安装配置
下载地址https://github.com/alibaba/otter
2.1环境初始化
推荐使用oneinstack进行环境配置(默认更新gcc,cmake等减少出现的依赖问题)
1. wget http://mirrors.linuxeye.com
![django mysql数据同步_[django自动同步数据库]Django数据库同步操作技巧详解](https://img-blog.csdnimg.cn/img_convert/91b2c85c7c570533194813c938c932ec.png)