1、全库同步与部分同步
之前提到,我们目前配置的主从同步是针对全库配置的,而实际环境中,一般并 不需要针对全库做备份,而只需要对一些特别重要的库或者表来进行同步。那如何 针对库和表做同步配置呢?
首先在Master端:
在my.cnf中,可以通过以下这些属性指定需要针对哪些库或者哪 些表记录binlog
#需要同步的二进制数据库名
binlog-do-db=testdemo
#只保留7天的二进制日志,以防磁盘被日志占满(可选)
expire-logs-days = 7
#不备份的数据库
binlog-ignore-db=information_schema
binlog-ignore-db=performation_schema
binlog-ignore-db=sys
然后在Slave端:在my.cnf中,需要配置备份库与主服务的库的对应关系。
#如果salve库名称与master库名相同,使用本配置
replicate-do-db = testdemo
#如果master库名[testdemo]与salve库名[testdemo01]不同,使用以下配置[需要做映射]
#replicate-rewrite-db = testdemo -> testdemo01
#如果不是要全部同步[默认全部同步],则指定需要同步的表
#replicate-wild-do-table=testdemo.user
#replicate-wild-do-table=testdemo.demotable
配置完成了之后,在show master status指令中,就可以看到Binlog_Do_DB和 Binlog_Ignore_DB两个参数的作用了
重启服务后,再次查看主库

可以看到我们配置的主库需要同步的数据库以及忽略的数据库
再查看从库的状态
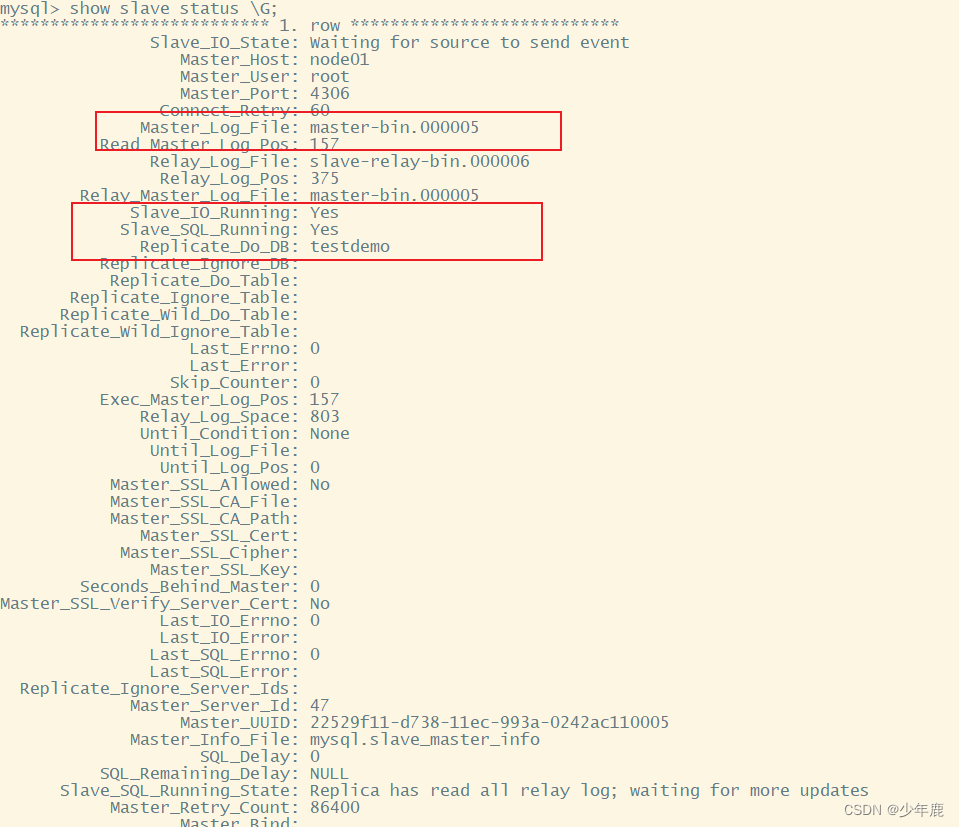
另外需要注意一点的是:目前我们的这个MySQL主从集群是单向的,也就是只能从主服务同
步到从服务,而从服务的数据表更是无法同步到主服务的。 所以,在这种架构下,为了保证数据一致,通常会需要保证数据只在主服务上 写,而从服务只进行数据读取。这个功能,就是大名鼎鼎的读写分离。但是这里要 注意下,mysql主从本身是无法提供读写分离的服务的,需要由业务自己来实现。 这也是我们后面要学的ShardingSphere的一个重要功能。
到这里可以看到,在MySQL主从架构中,是需要严格限制从服务的数据 写入的,一旦从服务有数据写入,就会造成数据不一致。并且从服务在 执行事务期间还很容易造成数据同步失败。如果需要限制用户写数据,我们可以在从服务中将read_only参数的值设 为1( set global read_only=1 ; )。这样就可以限制用户写入数据。但是这个属性有两个需要注意的地方:1、read_only=1设置的只读模式,不会影响slave同步复制的功能。 所 以在MySQL slave库中设定了read_only=1后,通过 "show slave status\G" 命令查看salve状态,可以看到salve仍然会读取master上的日 志,并且在slave库中应用日志,保证主从数据库同步一致;2、read_only=1设置的只读模式, 限定的是普通用户进行数据修改的操 作,但不会限定具有super权限的用户的数据修改操作。 在MySQL中设 置read_only=1后,普通的应用用户进行insert、update、delete等会 产生数据变化的DML操作时,都会报出数据库处于只读模式不能发生数 据变化的错误,但具有super权限的用户,例如在本地或远程通过root用 户登录到数据库,还是可以进行数据变化的DML操作; 如果需要限定 super权限的用户写数据,可以设置super_read_only=0。另外 如果要 想连super权限用户的写操作也禁止,就使用"flush tables with read lock;",这样设置也会阻止主从同步复制!
ok,我们接着测试下上面指定同步数据库的操作,我们在主库上再创建一个数据库,看看从库是否同步主库的数据,另外在从库上再创建一个数据库,查看从库是否会同步新建的数据库。
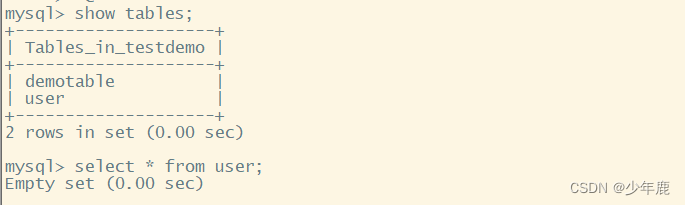
主库在testdemo数据库新建一个表user,查看从库是否会同步表
mysql> create table user(id int not null, userName varchar(200));
Query OK, 0 rows affected (0.04 sec)

现在查看从库testdemo库的表数据
现在继续在主节点上创建一个新的数据库orders
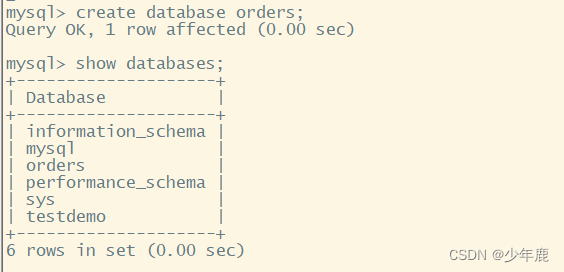
查看从库是否通不了新建的数据库orders

可以看到主节点新建的orders库是没有同步到从库的。
其他集群方式
我们到这里搭建出了一个一主一从的MySQL主从同步集群,具有了数据同步的基 础功能。而在生产环境中,通常会以此为基础,根据业务情况以及负载情况,搭建 更大更复杂的集群。
例如为了进一步提高整个集群的读能力,可以扩展出一主多从。而为了减轻主节 点进行数据同步的压力,可以继续扩展出多级从的主从集群。 为了提高整个集群的高可用能力,可以扩展出多主的集群。 我们也可以扩展出互为主从的互主集群甚至是环形的主从集群,实现MySQL多活
部署。 搭建互主集群只需要按照上面的方式,在主服务上打开一个slave进程,并且指向
slave节点的binlog当前文件地址和位置。
GTID同步集群
上面我们搭建的集群方式,是基于Binlog日志记录点的方式来搭建的,这也是最 为传统的MySQL集群搭建方式。可以看到有一个 Executed_Grid_Set列,暂时还没有用上。实际上,这就是另外一种搭建主从同步的 方式,即GTID搭建方式。这种模式是从MySQL5.6版本引入的。
GTID是对一个已经提交事务的编号,并且是全局唯一的。GTID是由UUID和TID组成的。UUID是MySQL实例的唯一标识,TID代表该实例上已经提交的事务数量,随着事务提交数量递增。举个例子:3E11FA47-71CA-11E1-9E33-C80AA9429562:23,冒号前面是UUID,后面是TID。
GTID 工作原理:
- 主库 master 提交一个事务时会产生 GTID,并且记录在 binlog 日志中
- 从库 salve I/O 线程读取 master 的 binlog 日志文件,并存储在 slave 的 relay log 中。slave 将 master 的 GTID 这个值,设置到 gtid_next 中,即下一个要读取的 GTID 值。
- slave 读取这个 gtid_next,然后对比 slave 自己的 binlog 日志中是否有这个 GTID
- 如果有这个记录,说明这个 GTID 的事务已经执行过了,可以忽略掉
- 如果没有这个记录,slave 就会执行该 GTID 事务,并记录到 slave 自己的 binlog 日志中。在读取执行事务前会先检查其他 session 持有该 GTID,确保不被重复执行。
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
GTID的本质也是基于Binlog来实现主从同步,只是他会基于一个全局的事务ID来 标识同步进度。GTID即全局事务ID,全局唯一并且趋势递增,他可以保证为每一个 在主节点上提交的事务在复制集群中可以生成一个唯一的ID 。 在基于GTID的复制中,首先从服务器会告诉主服务器已经在从服务器执行完了哪 些事务的GTID值,然后主库会有把所有没有在从库上执行的事务,发送到从库上进 行执行,并且使用GTID的复制可以保证同一个事务只在指定的从库上执行一次,这 样可以避免由于偏移量的问题造成数据不一致。 他的搭建方式跟我们上面的主从架构整体搭建方式差不多。只是需要在my.cnf中 修改一些配
在主节点上:
#开启gtid模式gtid_mode=on#强制gtid一致性,开启后对于特定create table不被支持enforce_gtid_consistency=onlog_bin=onlog-slave-updates=truebinlog_format=rowserver_id= 单独设置一个#relay log
skip_slave_start=1
在从节点上:
gtid_mode=onenforce_gtid_consistency=onlog-bin=slave-binloglog-slave-updates=trueserver_id= 单独设置一个#强烈建议,其他格式可能造成数据不一致binlog_format=row#relay log
skip_slave_start=1
然后分别重启主服务和从服务,就可以开启GTID同步复制方式。
检查GTID是否开启:
show variables like '%gtid%';slave连接到master:
CHANGE MASTER TO
MASTER_HOST='master的IP',
MASTER_USER='用户名',
MASTER_PASSWORD='密码',
MASTER_PORT=端口号,
# 1 代表采用GTID协议复制
# 0 代表采用老的binlog复制
MASTER_AUTO_POSITION = 1;