引言
学习ConcurrentHashMap,合理的问题顺序应该如下:
- ConcurrentHashMap是什么(WHAT)
- 为什么要有ConcurrentHashMap(WHY)
- ConcurrentHashMap的实现原理(HOW)
- ConcurrentHashMap如何使用(HOW TO USE)
ConcurrentHashMap是什么(WHAT)
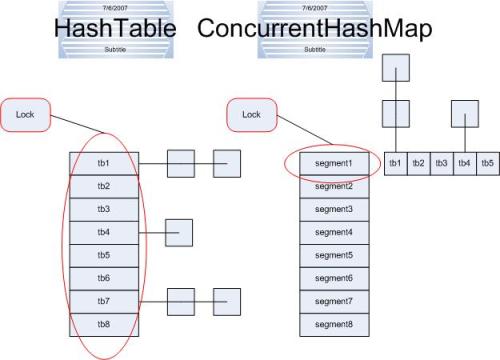
ConcurrentHashMap从JDK1.5开始随java.util.concurrent包一起引入JDK中,主要为了解决HashMap线程不安全和HashTable效率不高的问题。
Hashing是什么
散列法(Hashing)是一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法。由于通过更短的哈希值比用原始值进行数据库搜索更快,这种方法一般用来在数据库中建立索引并进行搜索
HashMap是什么
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。HashMap储存的是键值对,HashMap很快。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
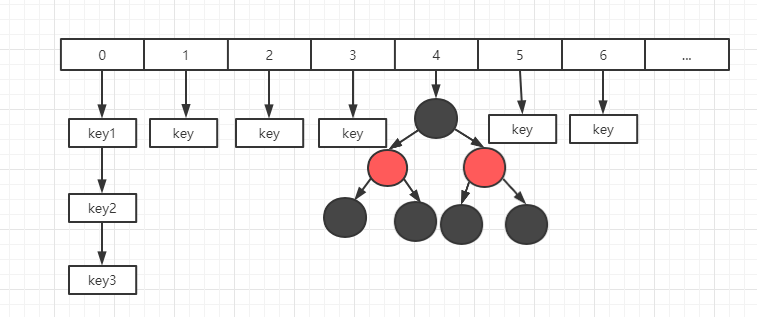
HashMap 内部结构:可以看作是数组和链表结合组成的复合结构,数组被分为一个个桶(bucket),每个桶存储有一个或多个Entry对象(每个Entry对象包含三部分key、value,next),通过哈希值决定了Entry对象(键值对)在这个数组的寻址;哈希值相同的Entry对象(键值对),则以链表形式存储。**如果链表大小超过树形转换的阈值(TREEIFY_THRESHOLD= 8),链表就会被改造为树形结构。
数组:存储区间连续,占用内存严重,寻址容易,插入删除困难;
链表:存储区间离散,占用内存比较宽松,寻址困难,插入删除容易;
HashMap综合应用了这两种数据结构,实现了寻址容易,插入删除也容易。
HashTable是什么
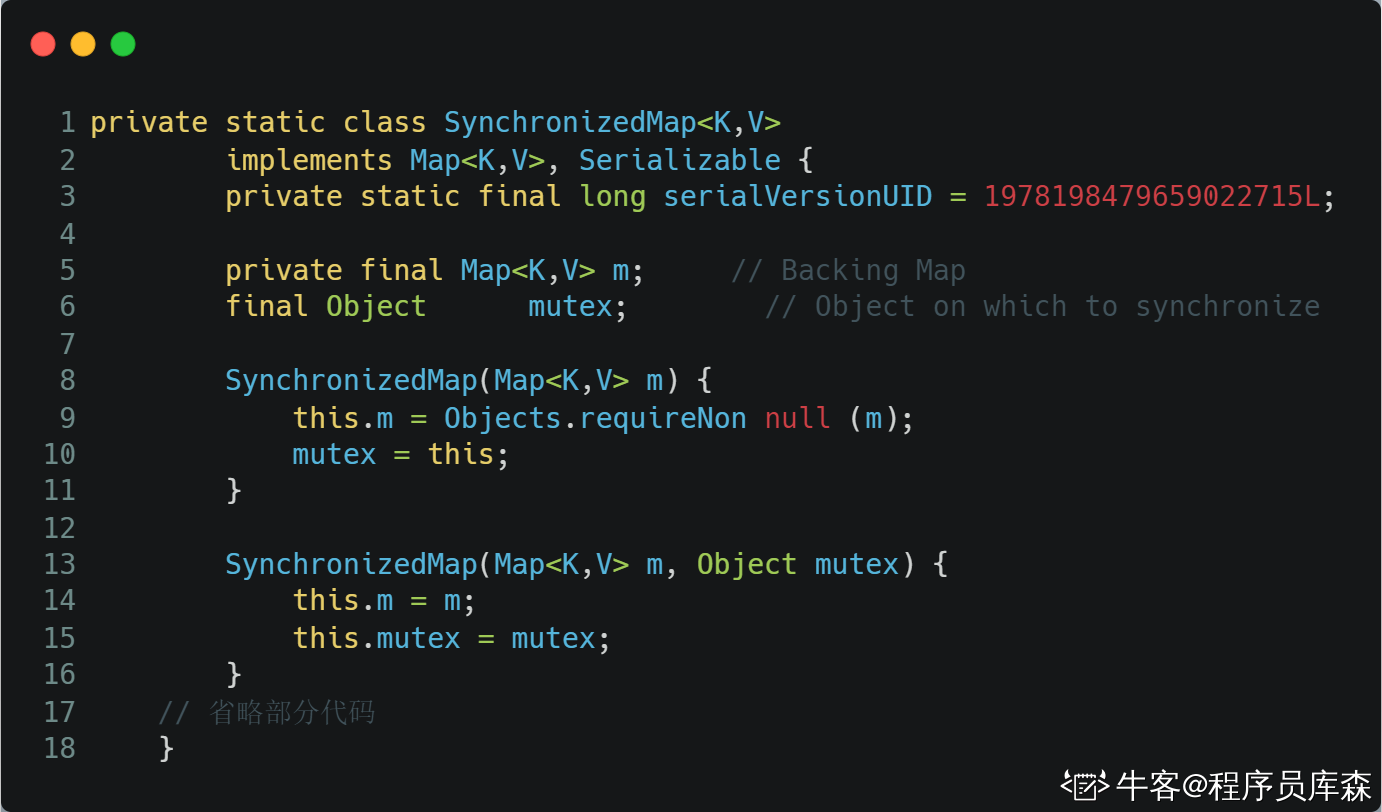
HashTable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
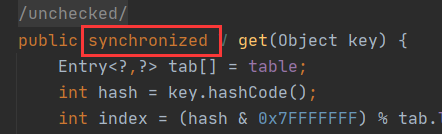
HashTable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。通过JAVA关键字synchronized实现。
synchronized是什么
Synchronized是Java中解决并发问题的一种最常用的方法,也是最简单的一种方法。Synchronized的作用主要有三个:
(1)确保线程互斥的访问同步代码
(2)保证共享变量的修改能够及时可见
(3)有效解决重排序问题。
在JVM中,对象在内存中的布局分为三块区域:对象头、实例变量和填充数据。
对象头:Hotspot虚拟机的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。其中Klass Point是是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据,它是实现轻量级锁和偏向锁的关键。
Monior:我们可以把它理解为一个同步工具,也可以描述为一种同步机制,它通常被描述为一个对象。与一切皆对象一样,所有的Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质,因为在Java的设计中 ,每一个Java对象自打娘胎里出来就带了一把看不见的锁,它叫做内部锁或者Monitor锁。Monitor 是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联(对象头的MarkWord中的LockWord指向monitor的起始地址),同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
为什么要有ConcurrentHashMap(WHY)
java.util.concurrent包是Java并发包,ConcurrentHashMap是Java自带的支持并发操作的HashMap。
HashMap线程不安全
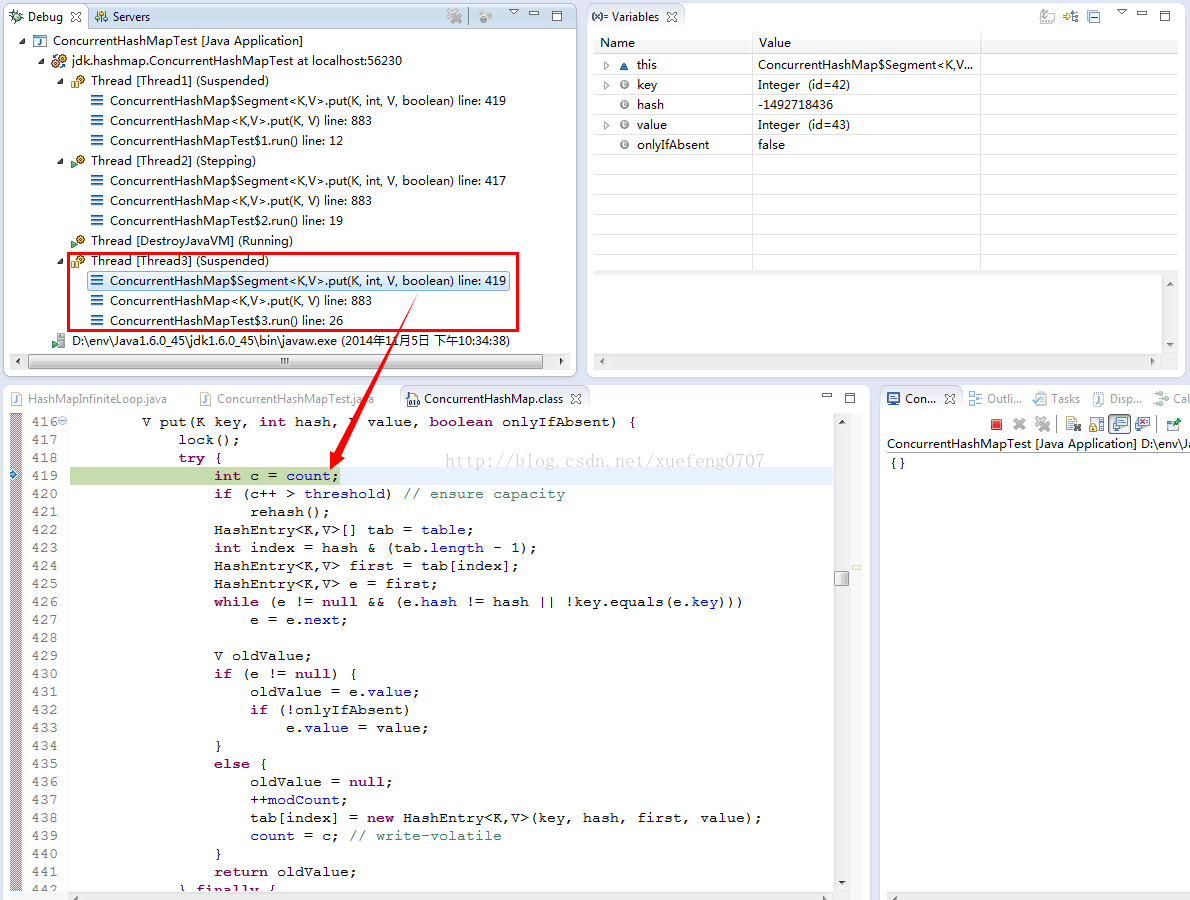
HashMap的扩容机制就是重新申请一个容量是当前的2倍的桶数组,然后将原先的记录逐个重新映射到新的桶里面,然后将原先的桶逐个置为null使得引用失效。如果多线程进行扩容操作,就会导致数据丢失。
HashTable效率不高
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对get,put,remove等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
ConcurrentHashMap的实现原理(HOW)
ConcurrentHashMap的实现——JDK5-JDK7版本
分段锁机制
ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,即每个分段则类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
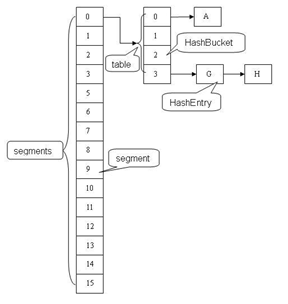
结构
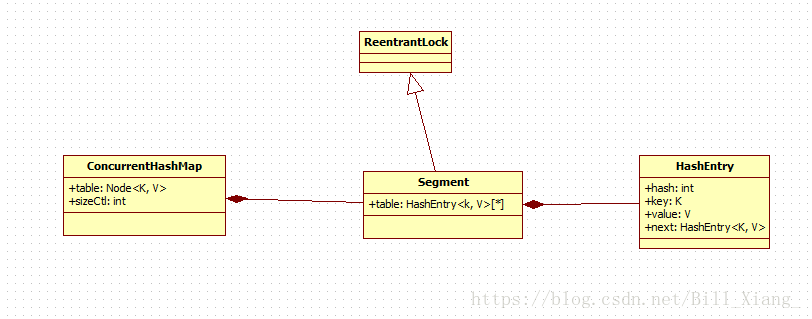
ConcurrentHashMap(1.7及之前)中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点)。
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
static final class Segment<K,V> extends ReentrantLock implements Serializable { transient volatile int count; transient int modCount; transient int threshold; transient volatile HashEntry<K,V>[] table; final float loadFactor;
}
static final class HashEntry<K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; }
结构图如下所示:
如何分段(HOW)
初始化ConcurrentHashMap
初始化ConcurrentHashMap即是初始化segments数组、segmentShift段偏移量和segmentMask段掩码等。
以下代码中,initialCapacity若不传默认为16,loadFactor若不传默认为0.75,concurrencyLevel若不传默认为16。
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching argumentsint sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = MIN_SEGMENT_TABLE_CAPACITY;while (cap < c)cap <<= 1;// create segments and segments[0]Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss;
}
在初始化时创建了两个中间变量ssize和sshift,它们都是通过concurrencyLevel计算得到的。其中ssize表示了segments数组的长度,为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方,所以在初始化时通过循环计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为数组的长度;而sshift表示了计算ssize时进行移位操作的次数。
初始化Segment
在初始化Segment时,也定义了一个中间变量cap,其等于initialCapacity除以size的倍数c,如果c大于1,则取大于等于c的2的N次方,cap表示Segment中HashEntry数组的长度;loadFactor表示了Segment的加载因子,通过cap*loadFactor获得每个Segment的阈值threshold。
如何将元素定位到Segment(HOW TO USE)
private int hash(Object k) {int h = hashSeed;if ((0 != h) && (k instanceof String)) {return sun.misc.Hashing.stringHash32((String) k);}// 默认从Object继承来的hashCode是基于对象的ID实现的h ^= k.hashCode();// Spread bits to regularize both segment and index locations,// using variant of single-word Wang/Jenkins hash.h += (h << 15) ^ 0xffffcd7d;h ^= (h >>> 10);h += (h << 3);h ^= (h >>> 6);h += (h << 2) + (h << 14);return h ^ (h >>> 16);
}
private Segment<K,V> segmentForHash(int h) {long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
}
通过hash()函数可知,首先通过计算一个随机的hashSeed减少String类型的key值的hash冲突;然后利用Wang/Jenkins hash算法对key的hash值进行再hash计算。通过这两种方式都是为了减少散列冲突,从而提高效率。
SIZE
ConcurrentHashMap的size操作的实现方法也非常巧妙,一开始并不对Segment加锁,而是直接尝试将所有的Segment元素中的count相加,这样执行两次,然后将两次的结果对比,如果两次结果相等则直接返回;而如果两次结果不同,则再将所有Segment加锁,然后再执行统计得到对应的size值。
缺点
ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。
ConcurrentHashMap的实现——JDK8版本
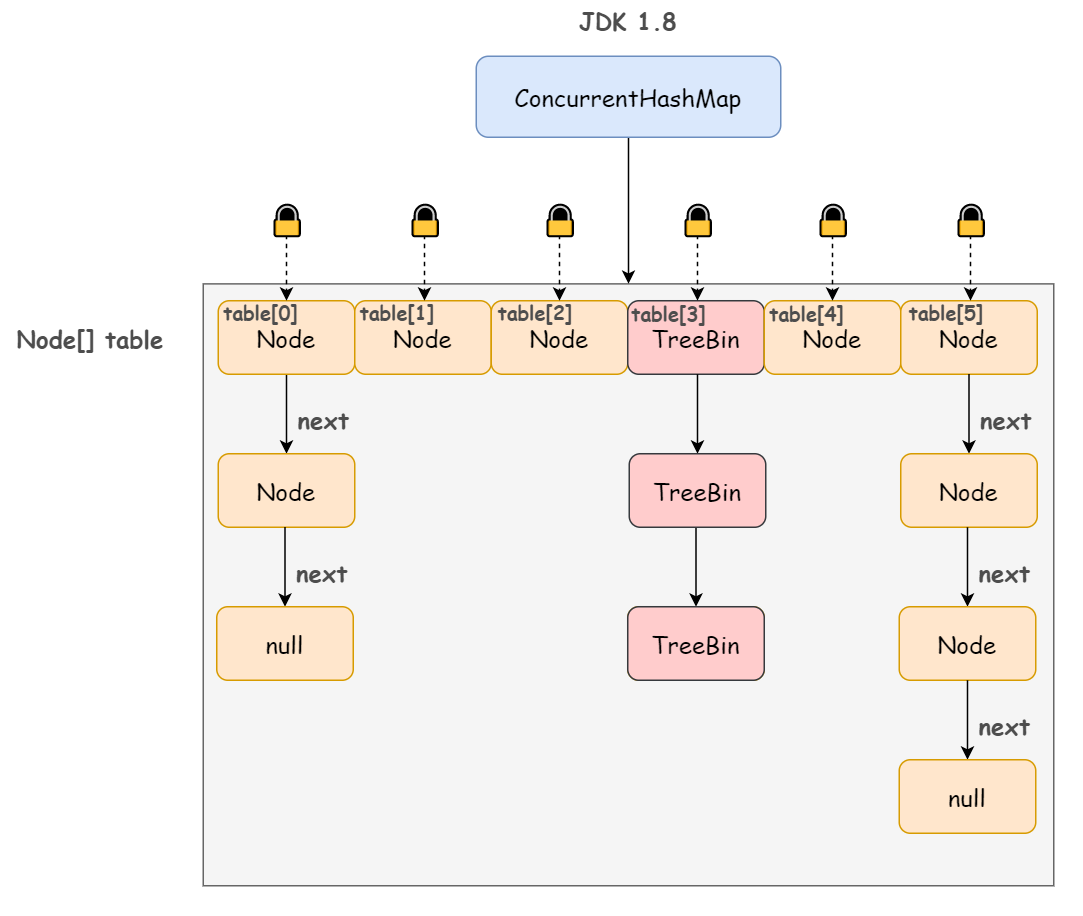
在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
CAS(Compare And Swap)原理
CAS有三个操作数,内存值V、预期值A、要修改的新值B,当且仅当A和V相等时才会将V修改为B,否则什么都不做。
结构
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable {volatile Node<K,V>[] table;// 扩容时新生成的数组,其大小为原数组的两倍volatile Node<K,V>[] nextTable;volatile long baseCount;// 用于table数组初始化及扩容控制volatile int sizeCtl;// 用于与CAS配合实现排他性,CAS从0改为1代表获取锁// 用于保护初始化CounterCell、初始化CounterCell数组以及对CounterCell数组进行扩容时的安全volatile int cellsBusy;// 初始大小为2,每次扩容翻倍,存储CounterCell对象,该对象有个value变量,用来存储个数// 该数组的大小上限与当前机器的CPU数量有关,它不会被主动初始化,只有在调用fullAddCount()函数时才会进行初始化private transient volatile CounterCell[] counterCells;...
}
Node:普通结点类型
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;...}
ForwardingNode 扩容时存放的结点类型,并发扩容的实现关键之一 ,是一个标记,代表此处是否已完成扩容。扩容期间,hash值为MOVED(值为-1)。当table[ i ] 是个ForwardingNode节点时,代表该位置节点已经移至新数组。
static final class ForwardingNode<K,V> extends Node<K,V> {final Node<K,V>[] nextTable;ForwardingNode(Node<K,V>[] tab) {super(MOVED, null, null, null);this.nextTable = tab;}...
}
TreeBin 用于包装红黑树结构的结点类型 ,它继承了Node,代表它也是个节点,hash值为-2。
static final class TreeBin<K,V> extends Node<K,V> {TreeNode<K,V> root;volatile TreeNode<K,V> first;volatile int lockState;...
}
ConcurrentHashMap实现原理
JDK1.8中的ConcurrentHashMap中还包含一个重要属性sizeCtl,其是一个控制标识符,不同的值代表不同的意思:其为0时,表示hash表还未初始化,而为正数时这个数值表示初始化或下一次扩容的大小,相当于一个阈值;即如果hash表的实际大小>=sizeCtl,则进行扩容,默认情况下其是当前ConcurrentHashMap容量的0.75倍;而如果sizeCtl为-1,表示正在进行初始化操作;而为-N时,则表示有N-1个线程正在进行扩容。
PUT操作
// onlyIfAbsent为true:相当于putIfAbsent,即key存在就不更换value
final V putVal(K key, V value, boolean onlyIfAbsent) {// key与value都不能为nullif (key == null || value == null) throw new NullPointerException();// 保证了hash >= 0int hash = spread(key.hashCode());int binCount = 0;// 循环CASfor (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}// 这个方法一共做了两件事,增加个数,扩容addCount(1L, binCount);return null;}
put操作大致可分为以下几个步骤:
- 计算key的hash值,即调用speed()方法计算hash值;
- 获取hash值对应的Node节点位置,此时通过一个循环实现。有以下几种情况:
2.1. 如果table表为空,则首先进行初始化操作,初始化之后再次进入循环获取Node节点的位置;
2.2.如果table不为空,但没有找到key对应的Node节点,则直接调用casTabAt()方法插入一个新节点,此时不用加锁;
2.3.如果table不为空,且key对应的Node节点也不为空,但Node头结点的hash值为MOVED(-1),则表示需要扩容,此时调用helpTransfer()方法进行扩容;
2.4.其他情况下,则直接向Node中插入一个新Node节点,此时需要对这个Node链表或红黑树通过synchronized加锁。 - 插入元素后,判断对应的Node结构是否需要改变结构,如果需要则调用treeifyBin()方法将Node链表升级为红黑树结构;
- 调用addCount()方法记录table中元素的数量。
关于插入的线程安全:插入位置为空则利用CAS来将新Node赋给table[ i ],否则synchronized锁住头节点对象,后序对该位置链/树的更改由锁保护。
SIZE操作
JDK1.8的ConcurrentHashMap中保存元素的个数的记录方法也有不同,首先在添加和删除元素时,会通过CAS操作更新ConcurrentHashMap的baseCount属性值来统计元素个数。但是CAS操作可能会失败,因此,ConcurrentHashMap又定义了一个CounterCell数组来记录CAS操作失败时的元素个数。所以:元素总数 = baseCount + sum(CounterCell)
ConcurrentHashMap如何使用(HOW TO USE)
使用场景
多线程对内存中的同一个MAP进行大量存取操作
使用须知
- public V get(Object key)不涉及到锁,也就是说获得对象时没有使用锁。ConcurrentHashMap不保证操作顺序,只保证每次取到的对象都是内存最新的对象(通过关键字volatile)。
- 对ConcurrentHashMap边遍历边删除或者增加操作不会产生异常,因为其内部已经做了维护,遍历的时候都能获得最新的值。即便是多个线程一起删除、添加元素也没问题。(HashMap或者ArrayList边遍历边删除数据会报java.util.ConcurrentModificationException异常,需要通过遍历器进行删除操作才行)
- put、remove方法要使用锁,但并不一定有锁争用。
使用示例
public static final Map<Long, String> conMap = new ConcurrentHashMap<Long, String>(1024);