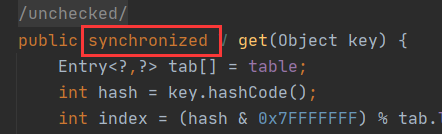
ConcurrentHashMap融合了hashtable和hashmap二者的优势。
hashtable是做了同步的,hashmap未考虑同步。所以hashmap在单线程情况下效率较高。hashtable在的多线程情况下,同步操作能保证程序执行的正确性。
但是hashtable每次同步执行的时候都要锁住整个结构。看下图:

图左侧清晰的标注出来,lock每次都要锁住整个结构。
ConcurrentHashMap正是为了解决这个问题而诞生的。
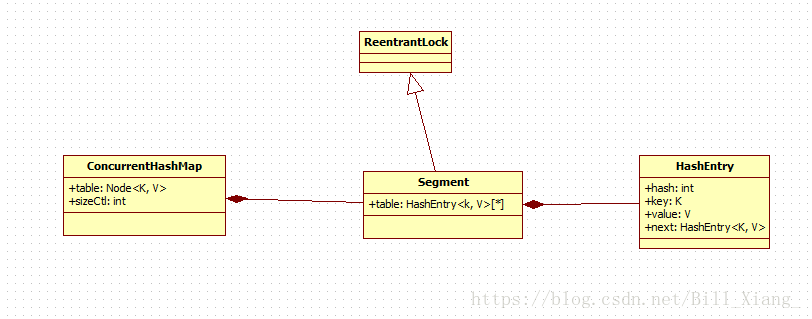
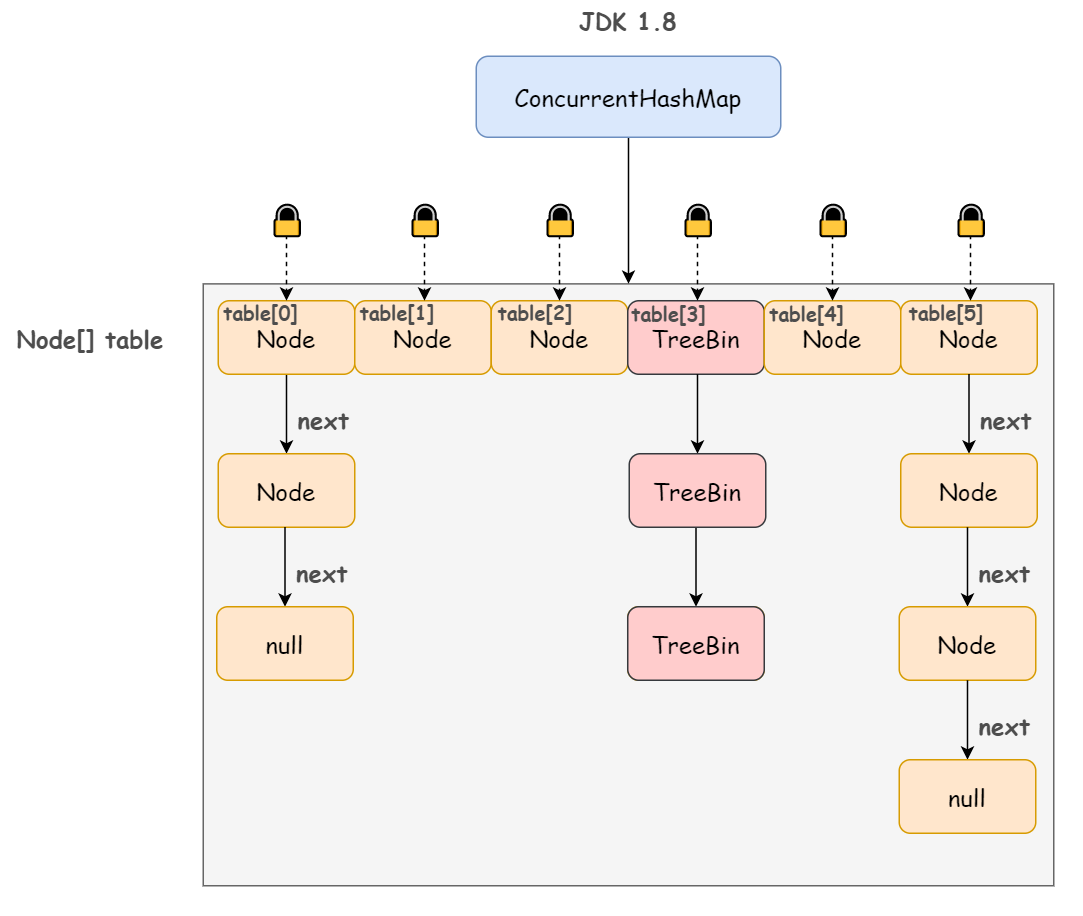
ConcurrentHashMap锁的方式是稍微细粒度的。 ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。
试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。
而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出 ConcurrentModificationEx
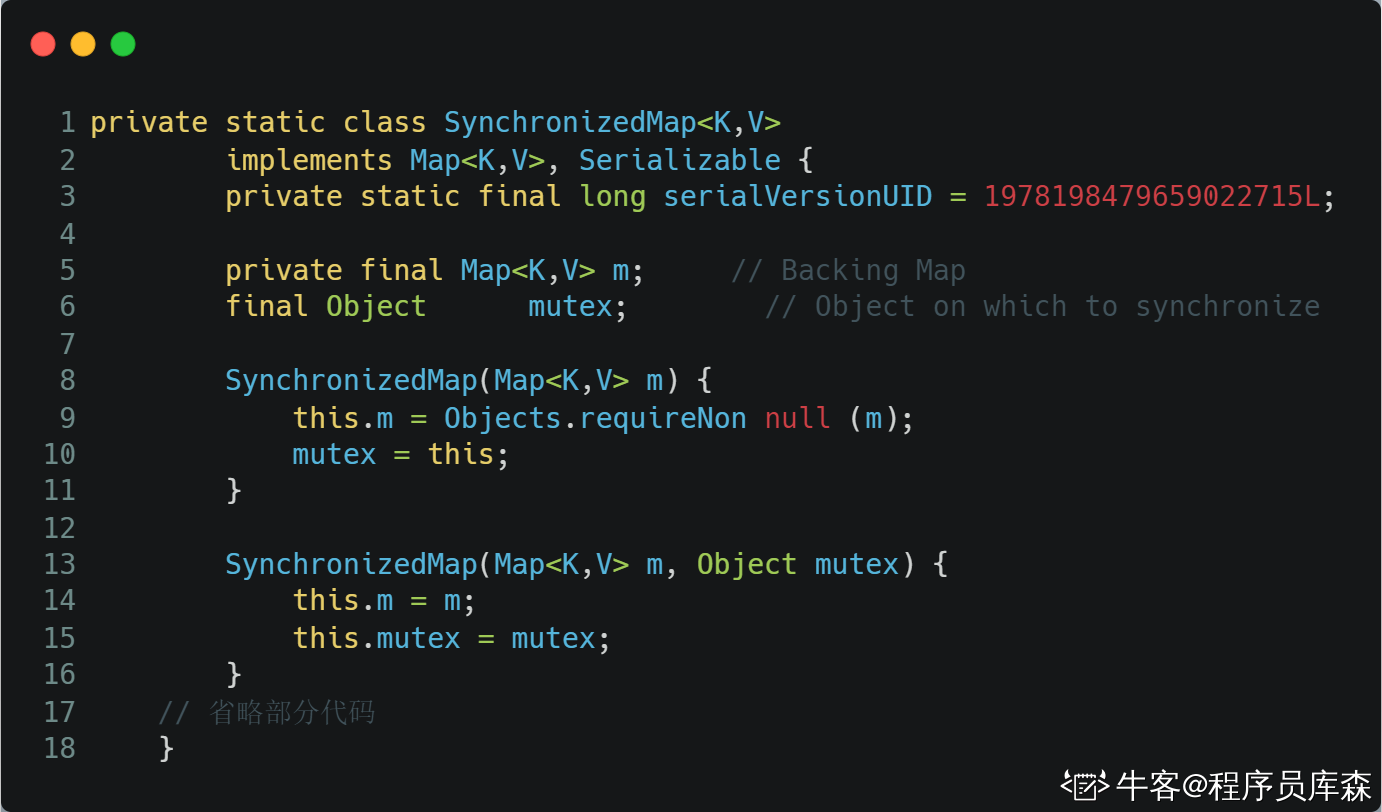
下面分析ConcurrentHashMap的源码。主要是分析其中的Segment。因为操作基本上都是在Segment上的。先看Segment内部数据的定义。

从上图可以看出,很重要的一个是table变量。是一个HashEntry的数组。Segment就是把数据存放在这个数组中的。除了这个量,还有诸如loadfactor、modcount等变量。
看segment的get 函数的实现:

加上hashentry的代码:

可以看出,hashentry是一个链表型的数据结构。
在segment的get函数中,通过getFirst函数得到第一个值,然后就是通过这个值的next,一路找到想要的那个对象。如果不空,则返回。如果为空,则可能是其他线程正在修改节点。比如上面说的弱一致迭代器在将指针更改为新值的过程。而之前的 get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确值。readValueUnderLock中就是用了lock()进行加锁。
put操作已开始就锁住了整个segment。这是因为修改操作时不能并发的。

同样,remove操作也是如此(类似put,一开始就锁住真个segment)。

但要注意一点区别,中间那个for循环是做什么用的呢?(截图未完全,可以自己找找代码查看一下)。从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他 所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关。