1.JDK 1.7
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成
Segment 继承自 ReentrantLock,是一种可重入锁;其中,HashEntry 是用于真正存储数据的地方
static final class Segment<K,V> extends ReentrantLock implements Serializable {// 真正存放数据的地方transient volatile HashEntry<K,V>[] table;// 键值对数量transient int count;// 阈值transient int threshold;// 负载因子final float loadFactor;Segment(float lf, int threshold, HashEntry<K,V>[] tab) {this.loadFactor = lf;this.threshold = threshold;this.table = tab;}
}
其实这里的 HashEntry 和 HashMap 中的 HashEntry 是一样的,每个 HashEntry 是一个链表结构的元素,其成员变量包含 key、value、hash 值以及下一个节点:
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;
}
一个 ConcurrentHashMap 包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,当对某个 HashEntry 数组中的元素进行修改时,必须首先获得该元素所属 HashEntry 数组对应的 Segment 锁。
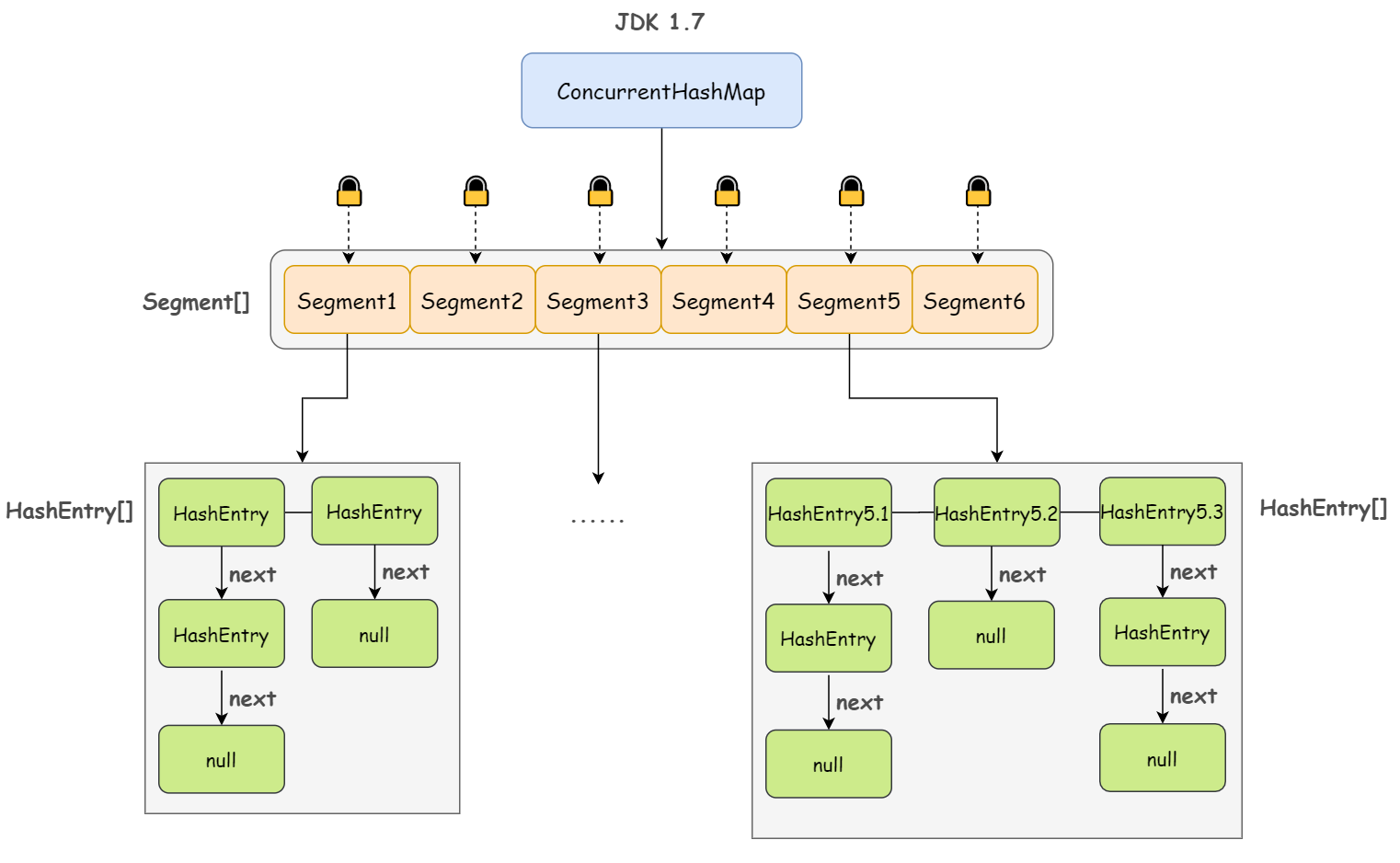
如此,JDK 1.7 版本下的 ConcurrentHashMap 的线程安全性其实已经跃然纸上了,简单来说:
ConcurrentHashMap 采用分段锁(Segment 数组,一个 Segment 就是一个锁)技术,每当一个线程访问 HashEntry 中存储的数据从而占用一个 Segment 锁时,并不会影响到其他的 Segment,也就是说,如果 Segment 数组中有 10 个 元素,那理论上是可以允许 10 个线程同时执行的。
put
来看它的 put 操作
首先,既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过 Hash 算法定位到 Segment:
然后在对应的 Segment 中进行真正的 put:
1)尝试获取锁,如果获取失败则利用 scanAndLockForPut() 进行自旋
2)遍历该 HashEntry 数组:
如果当前遍历到的 HashEntry 不为空则判断传入的 key 和当前遍历到的 key 是否相等,相等则覆盖旧的 value
为空则新建一个 HashEntry 并加入到 Segment 中(先判断是否需要对 Segment 数组进行扩容)
简单总结一下,put 方法首先定位到 Segment,尝试获取锁,如果失败则自旋。然后在 Segment 里进行插入操作,插入操作需要经历两个步骤,第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置,然后将其放在 HashEntry 数组里。
get
get 就更简单了,效率也非常高,因为整个过程都不需要加锁:
1)将 Key 通过 Hash 定位到具体的 Segment
2)再通过一次 Hash 定位到具体的元素上
小结
总结下 JDK 1.7 版本下的 ConcurrentHashMap,其实就是数组(Segment 数组) + 链表(每个 HashEntry 是链表结构),存在的问题也很明显,和 HashMap 一样,那就是 get 的时候都需要遍历链表,效率实在太低。
JDK 1.8
不同于 JDK 1.7 版本的 Segment 数组 + HashEntry 链表,JDK 1.8 版本中的 ConcurrentHashMap 直接抛弃了 Segment 锁,一个 ConcurrentHashMap 包含一个 Node 数组(和 HashEntry 实现差不多),每个 Node 是一个链表结构,并且在链表长度大于一定值时会转换为红黑树结构(TreeBin)。
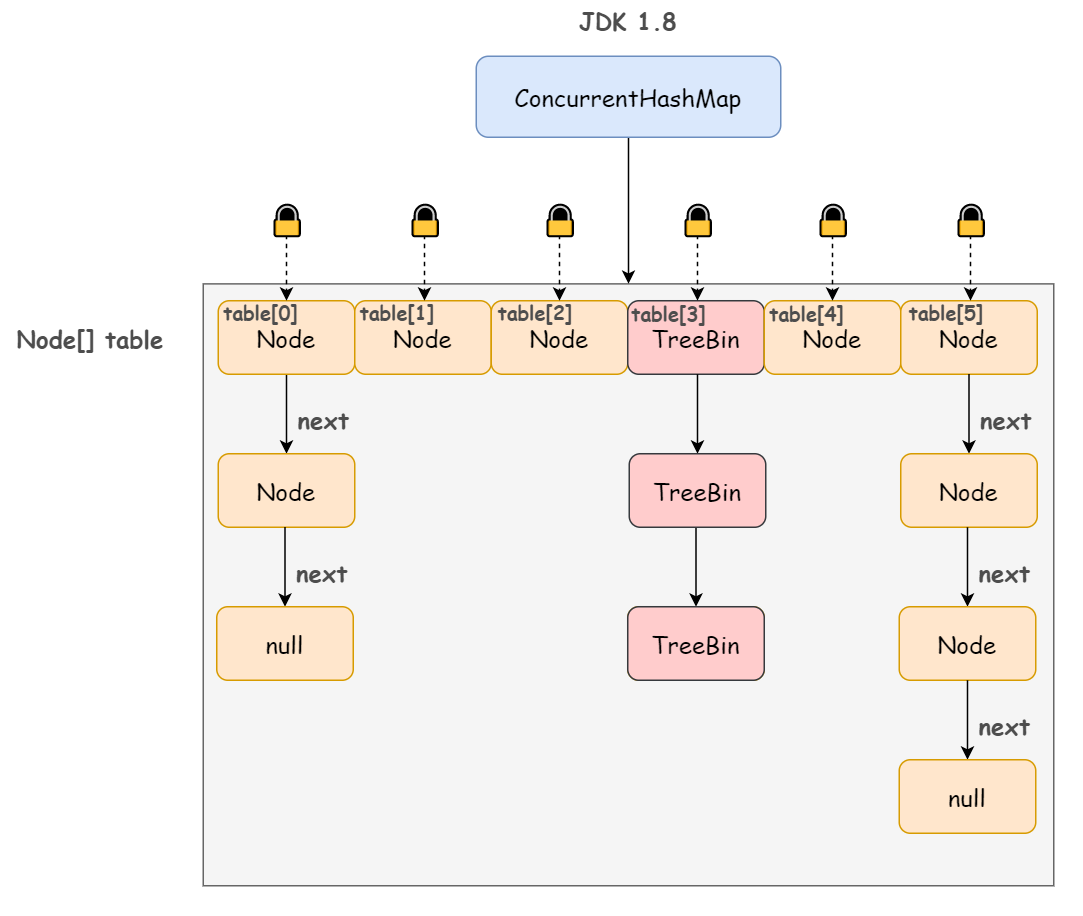
既然没有使用分段锁,如何保证并发安全性的呢?
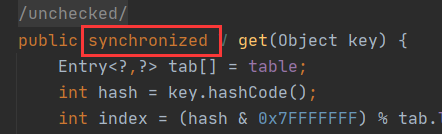
synchronized + CAS!
简单来说,Node 数组其实就是一个哈希桶数组,每个 Node 头节点及其所有的 next 节点组成的链表就是一个桶,只要锁住这个桶的头结点,就不会影响其他哈希桶数组元素的读写。桶级别的粒度显然比 1.7 版本的 Segment 段要细。
put 方法:
1)根据要 put 数据的 key 计算出 hashcode
2)遍历 table 数组,根据 hashcode 定位 Node:
如果 Node 为空表示当前位置可以写入数据,利用 CAS 尝试写入(失败则自旋)
如果当前位置的 hashcode == MOVED == -1,则需要对 Node 数组进行扩容
如果 Node 不为空并且也不需要进行扩容,则利用 synchronized 锁写入数据
get方法:
1)根据 key 对应 hashcode 找到对应的桶,如果正好是桶的头节点,则直接返回值
2)如果不是桶的头节点,并且是红黑树结构,那就按照树的方式去查找值
3)如果既不是桶的头节点,也不是红黑树结构,那就按照链表的方式去查找值(也就是遍历)