ConcurrentHashMap
1.ConcurrentHashMap的出现
我们最常用的集合框架一定包括HashMap,但是都知道它不是线程安全的。在并发插入元素的时候,有可能出现带环链表,让下一次读操作出现死循环。
而想要次避免HashMap的线程安全问题有很多办法,比如改用HashTable或者Collections.synchronizedMap。但是,这两者有着共同的问题:性能。无论读操作还是写操作,它们都会给整个集合加锁,导致同一时间的其他操作为之阻塞。
因此,ConcurrentHashMap应运而生。
2.ConcurrentHashMap底层结构
2.1.JDK1.7之前
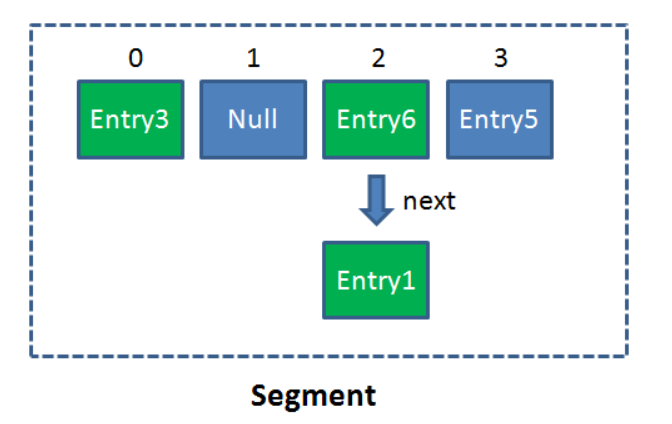
在了解ConcurrentHashMap之前,首先要了解一个概念Segment。Segment本身就相当于一个HashMap对象。
Segment事实上是一个可重入锁,它继承了Reentrantlock.
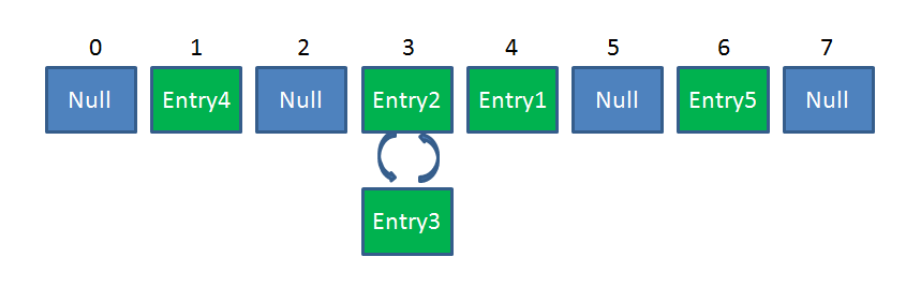
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头结点。
单一的Segment结构如下:
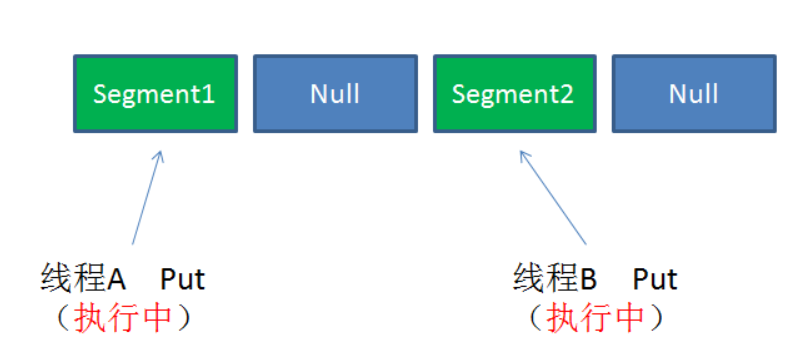
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。

因此整个ConcurrentHashMap的结构如下:

可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个自哈希表。
使用这样锁分段技术,每一个Segment就好比一个自治区,读写操作高度自治,Segment之间互不影响。
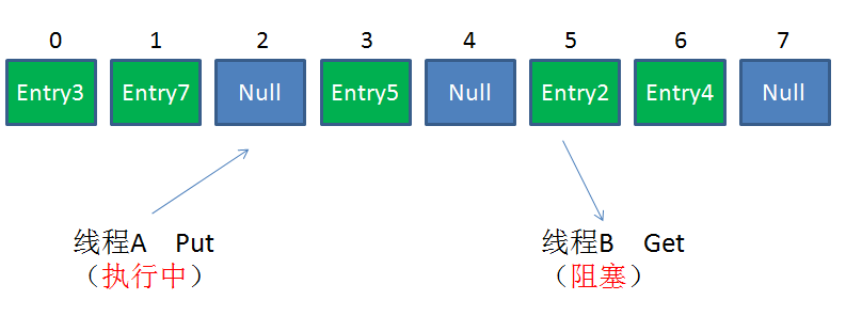
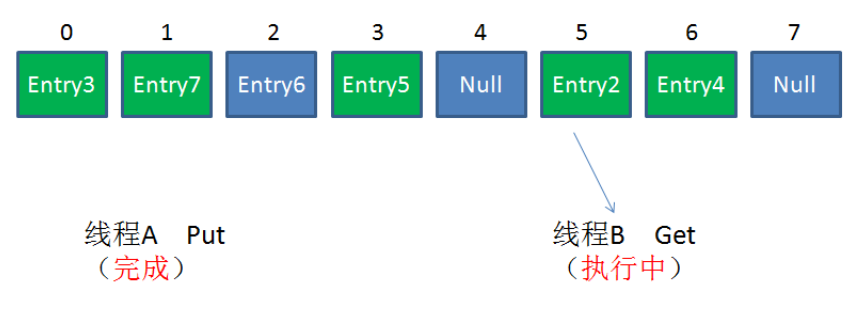
情况1:不同Segment的并发写入
不同Segment的写入是可以并发执行的。
情况2:同一Segment的一写一读
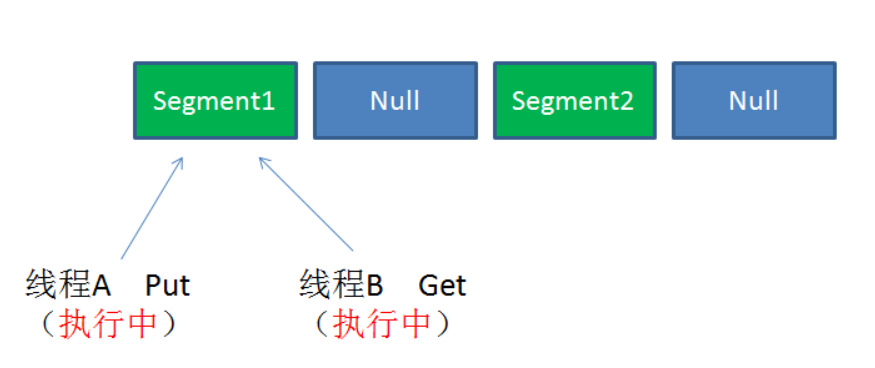
同一Segment的写和读是可以并发执行的。
情况3:同一Segment的并发写入
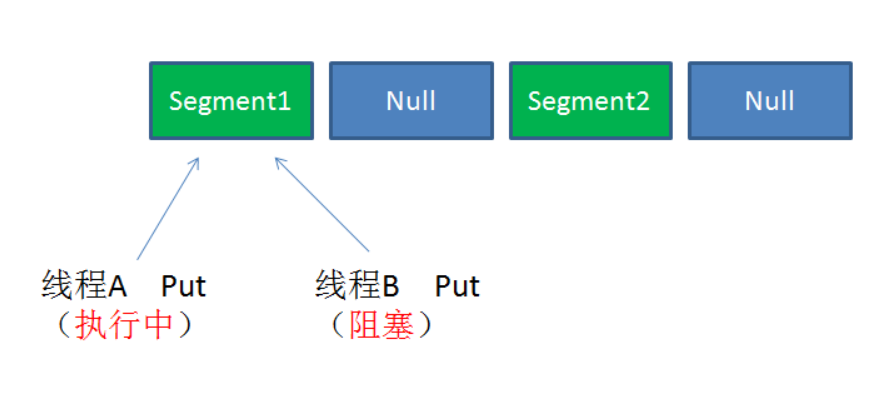
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
我们可以看一下ConcurrentHashMap的读写过程:
Get方法
- 为输入的Key做hash运算,得到hash值。
- 通过hash值,定位到对应的segment对象。
- 再次通过hash值,定位到segment当中的数组的具体位置。
Put方法
- 为输入的key做hash运算,得到hash值。
- 通过hash值,定位到对应的segment对象。
- 获取可重入锁。
- 再次通过hash值,定位到segment当中数组的具体位置。
- 插入或覆盖hashEntry对象。
- 释放锁。
可以看出ConcurrentHashMap在读写时都需要二次定位。首先定位到segment,之后定位到segment内的具体数组下标。
在调用size方法的时候,如何解决一致性的问题?
size方法的目的是统计ConcurrentHashMap的总元素数量,自然需要把各个segment内部的元素数量汇总起来。
但是,如果在统计segment元素数量的过程中,已统计过的segment瞬间插入新的元素,这时候该怎么办呢?

ConcurrentHashMap的size方法是一个嵌套循环,大体逻辑如下:
- 遍历所有的segment。
- 把segment的元素数量累加起来。
- 把segment的修改次数累加起来。
- 判断所有segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
- 如果尝试次数超过阈值,则对每一个segment加锁,再重新统计。
- 再次判断所有segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
- 释放锁,统计结束。
可以看看源码:
public int size() {// Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.final Segment<K,V>[] segments = this.segments;int size;boolean overflow; // true if size overflows 32 bitslong sum; // sum of modCountslong last = 0L; // previous sumint retries = -1; // first iteration isn't retrytry {for (;;) {if (retries++ == RETRIES_BEFORE_LOCK) { // 如果超过阈值,则进行加锁计算for (int j = 0; j < segments.length; ++j)ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {sum += seg.modCount; // 修改次数int c = seg.count; // 元素个数if (c < 0 || (size += c) < 0)overflow = true;}}if (sum == last) // 如果等于上次,跳出循环break;last = sum; // 记录这次修改次数,用作下次比较}} finally {if (retries > RETRIES_BEFORE_LOCK) { // 释放锁for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}return overflow ? Integer.MAX_VALUE : size;
}
(注:containsValue()和size()原理类似,按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。)
为什么这样设计呢?这种思想和乐观锁悲观锁的思想如出一辙。
为了尽量不锁住所有Segment,首先乐观地假设size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有segment保证强一致性。
那它是如何扩容的?
concurrentHashMap采用的是端内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测是否需要扩容,避免无效扩容。
2.2.1.7和1.8的区别
①整体结构
1.7:Segment + HashEntry + Unsafe
1.8:移除Segment,使锁的粒度更小,Synchronized + CAS + Node + Unsafe
②put()
1.7:先定位Segment,再定位桶,put全程加锁,没有获取锁的线程提前找桶的位置,并最多自旋64次获取锁,超过则挂起,改为阻塞锁。
1.8:由于移除了Segment,类似HashMap,可以直接定位到桶,拿到first节点后进行判断:①为空则CAS插入;②为-1则说明在扩容,则跟着一起扩容;③else 则加锁put(类似1.7)
③get()
基本类似,由于value声明为volatile,保证了修改的可见性,因此不需要加锁。
④resize()
1.7:跟HashMap步骤一样,只不过搬到单线程执行,避免了HashMap在1.7扩容时死循环的问题,保证线程安全。
1.8:支持并发扩容,HashMap扩容时在1.8中由头插改为尾插(为了避免死循环),ConcurrentHashMap也是,迁移也是从尾部开始,扩容前在桶的头部放置一个hash值为-1的节点,这样别的线程访问时就能判断是否该桶已经被其他线程处理过了。
⑤size()
1.7:很经典的思路:计算两次,如果不变则返回计算结果,若不一致,则锁住所有的segment求和。
1.8:用baseCount来存储当前的节点个数,这涉及到baseCount并发环境下修改的问题。
具体的实现方式比较复杂,如下:
size()方法
先利用sumCount()计算,然后如果值超过int的最大值,就返回int的最大值。但是有时size就会超过最大值,这时最好用mappingCount方法。
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);}
public long mappingCount() {long n = sumCount();return (n < 0L) ? 0L : n; // ignore transient negative values
}
sumCount有两个重要的属性baseCount和countCells,如果counterCells不为空,那么总共的大小就是baseCount与遍历CounterCells的value值累加获得的。
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;}
而baseCount是从哪里来的?
// 当没有线程争用时,使用这个变量计数
private transient volatile long baseCount;
一个volatile变量,在addCount方法会使用它,而addCount方法在put结束后会调用
addCount(1L, binCount);
if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
从上可知,在put操作结束后,会调用addCount,更新计数。
在并发情况下,如果CAS修改baseCount失败后,就会使用到CounterCell类,会创建一个对象,通常对象的volatile的value属性是1.
// 一种用于分配计数的填充单元。
@sun.misc.Contended
static final class CounterCell {volatile long value;CounterCell(long x) { value = x; }
}
并发时,利用CAS修改baseCount失败后,会利用CAS操作修改CountCell的值。
if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {fullAddCount(x, uncontended);return;
}
如果上面CAS操作也失败了,在fullAddCount方法中,会继续死循环操作,直到成功。
for (;;) {CounterCell[] as; CounterCell a; int n; long v;if ((as = counterCells) != null && (n = as.length) > 0) {if ((a = as[(n - 1) & h]) == null) {if (cellsBusy == 0) { // Try to attach new CellCounterCell r = new CounterCell(x); // Optimistic createif (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;if ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;}if (created)break;continue; // Slot is now non-empty}}collide = false;}
3.其他的线程安全的集合框架
3.1.Collections.synchronizedMap
首先,看看Collections.synchonizedMap是如何实现线程安全的。
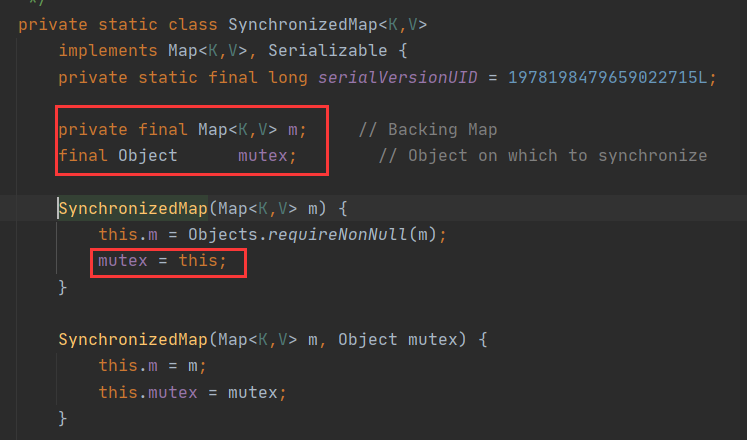
在SynchronizedMap内部维护了一个普通对象Map,还有排斥锁mutex。
Collections.synchronizedMap(new HashMap<>(16));
我们在调用这个方法的时候就需要传入一个Map,可以看到有两个构造器,如果传入了mutex参数,则将对象排斥锁赋值为传入的对象。
如果没有,则将对象排斥锁赋值为this,即调用synchronizedMap的对象,就是上面的对象。
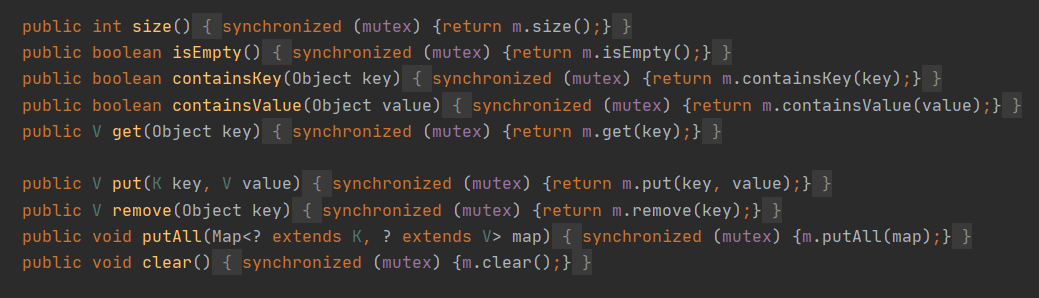
创建出synchronizedMap之后,再操作map的时候,就会对方法上锁,如图:
3.2.HashTable
跟HashMap相比Hashtable是线程安全的,适合在多线程的情况下使用,但是效率不太乐观。
因为它在对数据操作的时候都会上锁,所以效率比较低。
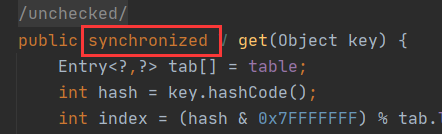
3.2.1.HashTable和HashMap不同点
①HashTable是不允许键或值为null的,HashMap的键值都可以为null。
HashTable在put空值的时候会直接抛空指针异常,但是HashMap却做了特殊处理。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
原因是HashTable使用的是安全失败机制(fail-safe),这种机制会使此次读到的数据不一定是最新的数据。
如果使用null值,就会使得其无法判断对应的key是不存在还是为空,因为无法再调用一次contain(key)来对key是否存在进行判断,ConcurrentHashMap同理。
②
- 实现方式不同:HashTable继承了Dictionary类,而HashMap继承的是AbstractMap类。Dictionary是JDK1.0添加的。
- 初始化容量不同:HashMap的初始容量为:16,HashTable初始容量为:11,两者的负载因子默认都是:0.75;
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap扩容规则为当前容量翻倍,HashTable扩容规则为当前容量翻倍+1.
- 迭代器不同:HashMap中的Iterator迭代器是fail-fast的,而HashTable的Enumerator不是fail-fast的。
所以,当其他线程改变了HashMap的结构,如:增加、删除元素,将会抛出ConcurrentModificationException异常,而hashTable则不会。
3.3.快速失败(fail-fast)
**快速失败(fail-fast)**是java集合中的一种机制,在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hasNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedModCount值,是的话就返回遍历;否则抛出异常,终止遍历。
注意:这里异常的抛出条件是检测到modCount != expectedModCount这个条件。如果集合发生变化时修改modCount值刚好又设置了expectedModCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)
3.4.安全失败(fail-safe)
安全失败(fail-safe):采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception.
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。