本篇内容包括:ConcurrentHashMap 概述、ConcurrentHashMap 底层数据结构、ConcurrentHashMap 的使用以及相关知识点。
一、ConcurrentHashMap 概述
ConcurrentHashMap 是 HashMap 的线程安全版本,其内部和 HashMap 一样,也是采用了数组 + 链表 + 红黑树的方式来实现。
如何实现线程的安全性?加锁。但是这个锁应该怎么加呢?在 HashTable 中,是直接在 put 和 get 方法上加上了 synchronized,理论上来说 ConcurrentHashMap 也可以这么做,但是这么做锁的粒度太大,会非常影响并发性能,所以在 ConcurrentHashMap 中并没有采用这么直接简单粗暴的方法,其内部采用了非常精妙的设计,大大减少了锁的竞争,提升了并发性能。
ConcurrentHashMap 主要就是为了应对 HashMap 在并发环境下不安全而诞生的,ConcurrentHashMap 大量的利用了 volatile,final,CAS 等 lock-free 技术来减少锁竞争对于性能的影响。
ConcurrentHashMap 避免了对全局加锁改成了局部加锁操作,这样就极大地提高了并发环境下的操作速度
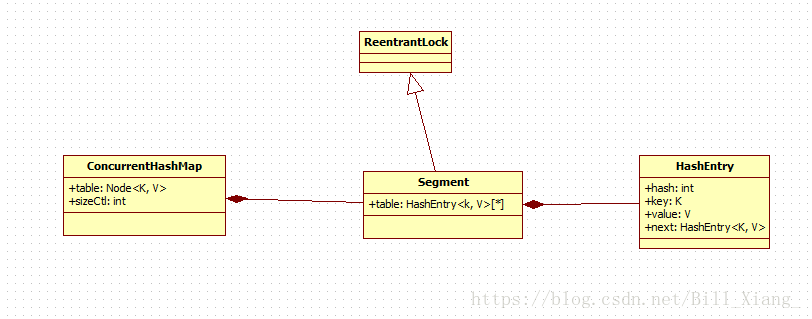
在 Jdk1.7 中 ConcurrentHashMap 采用了 数组+Segment+分段锁 的方式实现。ConcurrentHashMap 中的分段锁称为 Segment,它即类似于 HashMap 的结构,就是内部拥有一个 Entry 数组,数组中的每个元素又是一个链表,同时呢 Segment 还继承了 ReentrantLock。
ConcurrentHashMap 使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。ConcurrentHashMap 定位一个元素的过程需要进行两次 Hash 操作。第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部。
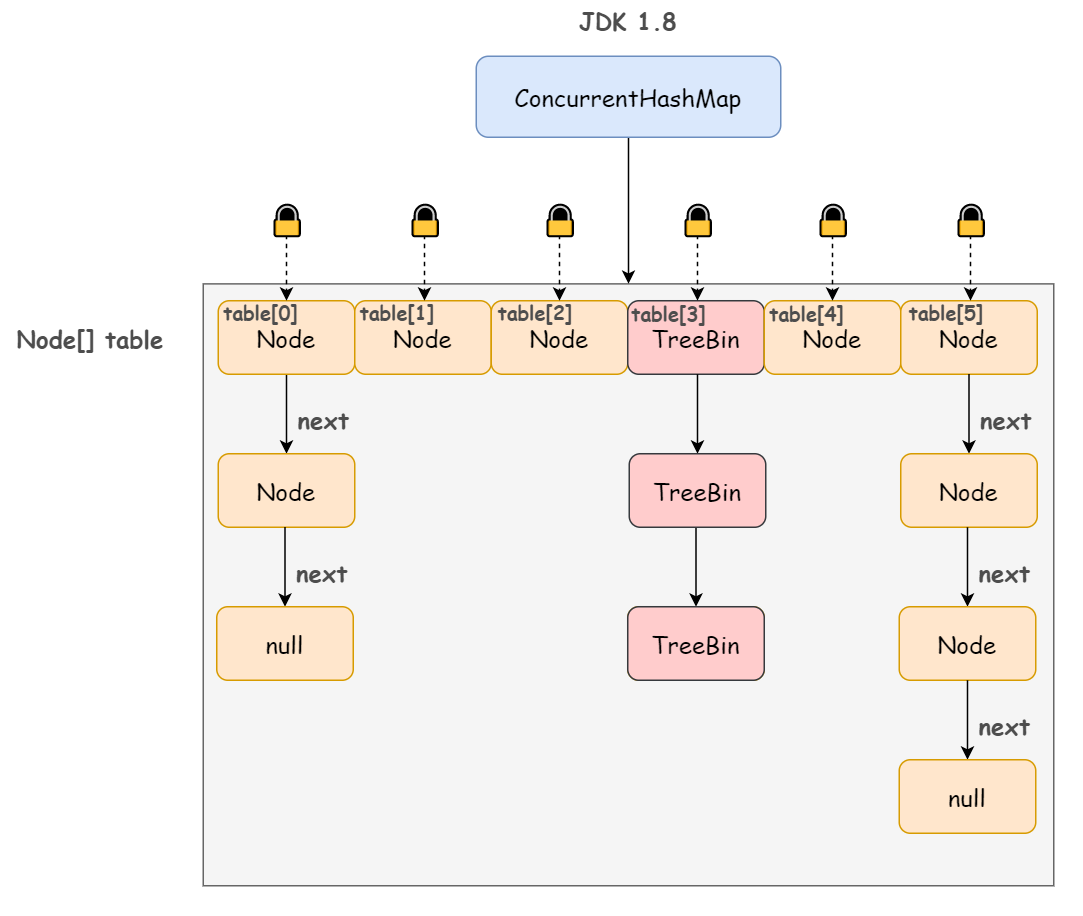
在 Jdk1.8 中 ConcurrentHashMap 参考了Jdk1.8 HashMap 的实现,采用了 数组+链表+红黑树 的实现方式来设计,采用 CAS+Synchronized 保证线程安全。Jdk1.8 中彻底放弃了 Segment 转而采用的是 Node,其设计思想也不再是 JDK1.7 中的分段锁思想。
Node:保存 key,value 及 key 的 hash 值的数据结构。其中 value 和 next 都用 volatile 修饰,保证并发的可见性。
二、ConcurrentHashMap 底层数据结构
JDk1.7 和 JDK1.8 中,ConcurrentHashMap 的结构有着很大的变化
1、JDK1.8 中结构
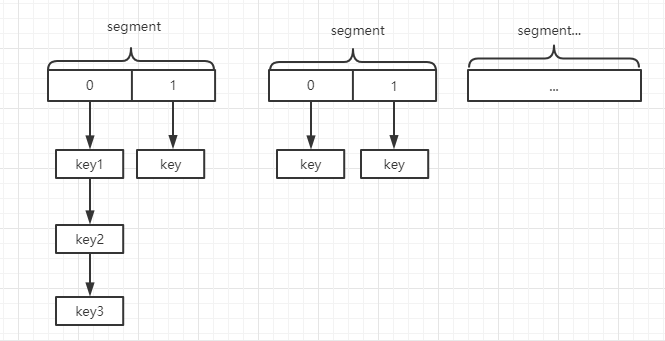
在 JDk1.7 中,ConcurrentHashMap 是由 Segment 数据结构和 HashEntry 数组结构构成。采取分段锁来保证安全性。
Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap 中扮演锁的角色;HashEntry 则用于存储键值对数据。
一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,Segment 的结构和 HashMap 类似,是一个数组和链表结构。
2、JDK1.8 中结构
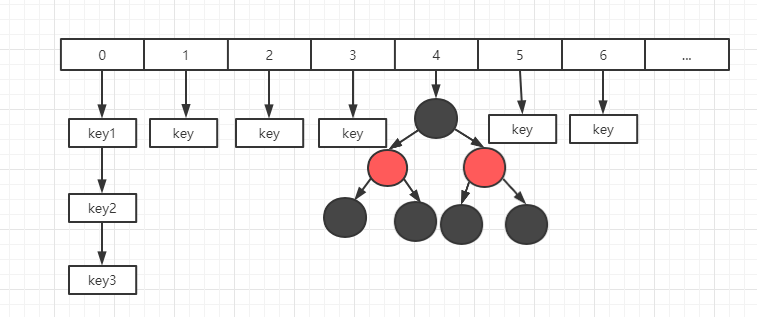
JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
3、ConcurrentHashMap 在 Jdk1.7 和 Jdk1.8 中的区别
- 数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7 采用 segment 的分段锁机制实现线程安全,其中 segment 继承自 ReentrantLock。JDK1.8采用 CAS+Synchronized 保证线程安全。
- 锁的粒度:原来是对需要进行数据操作的 Segment 加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的 hash 算法简化会带来弊端,Hash 冲突加剧,因此在链表节点数量大于 8 时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从原来的遍历链表 O(n),变成遍历红黑树 O(logN)
三、ConcurrentHashMap 的使用
1、构造方法
| 方法名 | 方法说明 | 方法名 | 方法说明 |
|---|---|---|---|
public ConcurrentHashMap() | 无参构造 | public ConcurrentHashMap(int initialCapacity) | 指定初始容量 |
public ConcurrentHashMap(Map<? extends K, ? extends V> m) | 使用Map初始化 | public ConcurrentHashMap(int initialCapacity, float loadFactor) | 初始化初始容量和加载因子 |
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) | 初始化初始容量和加载因子以及concurrencyLevel |
2、常用方法
void clear():从该映射中移除所有映射关系boolean containsKey(Object key):测试指定对象是否为此表中的键。boolean containsValue(Object value):如果此映射将一个或多个键映射到指定值,则返回 true。Enumeration elements():返回此表中值的枚举。Set<Map.Entry<K,V>> entrySet():返回此映射所包含的映射关系的 Set 视图。V get(Object key):返回指定键所映射到的值,如果此映射不包含该键的映射关系,则返回 null。boolean isEmpty():如果此映射不包含键-值映射关系,则返回 true。Enumeration keys():返回此表中键的枚举。Set keySet():返回此映射中包含的键的 Set 视图。V put(K key, V value):将指定键映射到此表中的指定值。void putAll(Map<? extends K,? extends V> m):将指定映射中所有映射关系复制到此映射中。V putIfAbsent(K key, V value):如果指定键已经不再与某个值相关联,则将它与给定值关联。V remove(Object key):从此映射中移除键(及其相应的值)。boolean remove(Object key, Object value):只有目前将键的条目映射到给定值时,才移除该键的条目。V replace(K key, V value):只有目前将键的条目映射到某一值时,才替换该键的条目。boolean replace(K key, V oldValue, V newValue):只有目前将键的条目映射到给定值时,才替换该键的条目。int size():返回此映射中的键-值映射关系数。Collection values():返回此映射中包含的值的 Collection 视图。
四、相关知识点
1、 JDK 1.8 中为什么要摒弃分段锁
很多人不明白为什么Doug Lea在JDK1.8为什么要做这么大变动,使用重级锁synchronized,性能反而更高,原因如下:
- jdk1.8中锁的粒度更细了。jdk1.7中ConcurrentHashMap 的concurrentLevel(并发数)基本上是固定的。jdk1.8中的concurrentLevel是和数组大小保持一致的,每次扩容,并发度扩大一倍.
- 红黑树的引入,对链表的优化使得 hash 冲突时的 put 和 get 效率更高
- 获得JVM的支持 ,ReentrantLock 毕竟是 API 这个级别的,后续的性能优化空间很小。 synchronized 则是 JVM 直接支持的, JVM 能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就
2、为什么 key 和 value 不允许为 null
在 HashMap 中,key 和 value 都是可以为 null 的,但是在 ConcurrentHashMap 中却不允许,这是为什么呢?
作者 Doug Lea 本身对这个问题有过回答,在并发编程中,null 值容易引来歧义, 假如先调用 get(key) 返回的结果是 null,那么我们无法确认是因为当时这个 key 对应的 value 本身放的就是 null,还是说这个 key 值根本不存在,这会引起歧义,如果在非并发编程中,可以进一步通过调用 containsKey 方法来进行判断,但是并发编程中无法保证两个方法之间没有其他线程来修改 key 值,所以就直接禁止了 null 值的存在。
而且作者 Doug Lea 本身也认为,假如允许在集合,如 map 和 set 等存在 null 值的话,即使在非并发集合中也有一种公开允许程序中存在错误的意思,这也是 Doug Lea 和 Josh Bloch(HashMap作者之一) 在设计问题上少数不同意见之一,而 ConcurrentHashMap 是 Doug Lea 一个人开发的,所以就直接禁止了 null 值的存在。