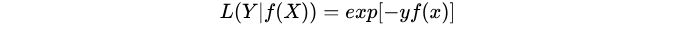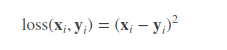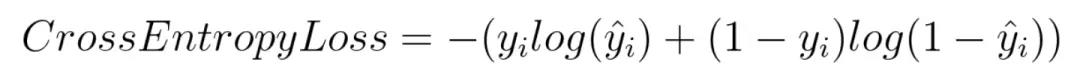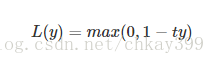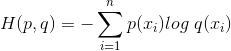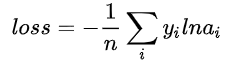损失函数
机器学习模型关于单个样本的预测值与真实值的差称为损失。损失越小,模型越好,如果预测值与真实值相等,就是没有损失。
损失函数(Loss function)是用来估量模型的预测值 f(x) 与真实值 Y 的不一致程度,它是一个非负实值函数,通常用 L(Y,f(x)) 来表示。损失函数越小,模型的鲁棒性就越好。
虽然损失函数可以让我们看到模型的优劣,并且为我们提供了优化的方向,但是我们必须知道没有任何一种损失函数适用于所有的模型。损失函数的选取依赖于参数的数量、异常值、机器学习算法、梯度下降的效率、导数求取的难易和预测的置信度等若干方面。
由于机器学习的任务不同,损失函数一般分为分类和回归两类,回归会预测出一个数值结果,分类则会给出一个标签。
分类损失函数
1.0-1损失函数
0-1损失是指,预测值和目标值不相等为1,否则为0:
感知机就是用的这种损失函数。但是由于相等这个条件太过严格,因此我们可以放宽条件,即满足 |Y−f(X)|<T时认为相等。
2.对数损失函数
逻辑回归的损失函数就是对数损失函数,在逻辑回归的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。逻辑回归并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了对数损失函数。
损失函数的标准形式:
在极大似然估计中,通常都是先取对数再求导,再找极值点,这样做是方便计算极大似然估计。损失函数L(Y,P(Y|X))是指样本X在分类Y的情况下,使概率P(Y|X)达到最大值(利用已知的样本分布,找到最大概率导致这种分布的参数值)
3.平方损失函数
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。最小二乘法的基本原则是:最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧几里得距离进行距离的度量。平方损失的损失函数为:
4. 指数损失函数
AdaBoost就是以指数损失函数为损失函数的。
指数损失函数的标准形式:
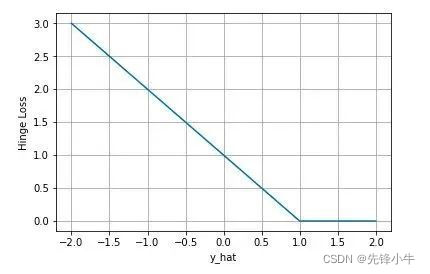
5. Hinge损失函数
Hinge损失函数用于最大间隔(maximum-margin)分类,其中最有代表性的就是支持向量机SVM。
Hinge函数的标准形式:
其中,t为目标值(-1或+1),y是分类器输出的预测值,并不直接是类标签。其含义为,当t和y的符号相同时(表示y预测正确)并且|y|≥1时,hinge loss为0;当t和y的符号相反时,Hinge损失函数随着y的增大线性增大。
在支持向量机中,最初的SVM优化的函数如下:
将约束项进行变形,则为:
则损失函数可以进一步写为:
因此,SVM的损失函数可以看做是L2正则化与Hinge loss之和。
回归损失函数
1.L1损失函数:
平均绝对误差(MAE)是一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向(注:平均偏差误差MBE则是考虑的方向的误差,是残差的和),范围是0到∞,其公式如下所示:
MAE损失(y轴)与预测(x轴)
2.L2损失函数:
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和,其公式如下所示:
下图是均方根误差值的曲线分布,其中最小值为预测值为目标值的位置。我们可以看到随着误差的增加损失函数增加的更为迅猛。
MSE损失(y轴)与预测(x轴)
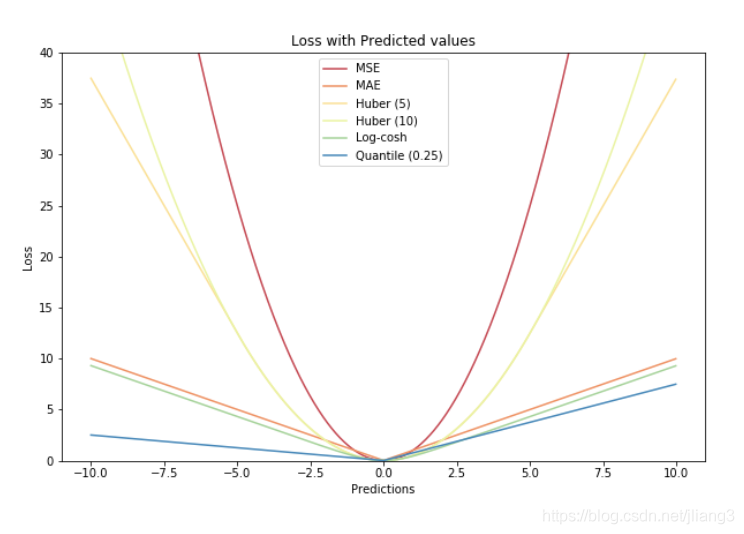
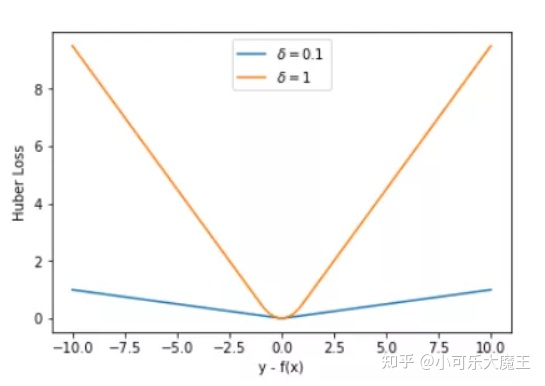
3.Huber损失函数
Huber损失相比于平方损失来说对于异常值不敏感,但它同样保持了可微的特性。它基于绝对误差但在误差很小的时候变成了平方误差。我们可以使用超参数δ来调节这一误差的阈值。当δ趋向于0时它就退化成了MAE,而当δ趋向于无穷时则退化为了MSE,其表达式如下,是一个连续可微的分段函数:
Huber损失(y轴)与预测(x轴)
对于Huber损失来说,δ的选择十分重要,它决定了模型处理异常值的行为。当残差大于δ时使用L1损失,很小时则使用更为合适的L2损失来进行优化。
Huber损失函数克服了MAE和MSE的缺点,不仅可以保持损失函数具有连续的导数,同时可以利用MSE梯度随误差减小的特性来得到更精确的最小值,也对异常值具有更好的鲁棒性。而Huber损失函数的良好表现得益于精心训练的超参数δ。
4.Log-Cosh损失函数
Log-Cosh损失函数是一种比L2更为平滑的损失函数,利用双曲余弦来计算预测误差:
Log-Cosh损失(y轴)与预测(x轴)
它的优点在于对于很小的误差来说log(cosh(x))与(x**2)/2很相近,而对于很大的误差则与abs(x)-log2很相近。这意味着log cosh损失函数可以在拥有MSE优点的同时也不会受到异常值的太多影响。它拥有Huber的所有优点,并且在每一个点都是二次可导的。二次可导在很多机器学习模型中是十分必要的,例如使用牛顿法的XGBoost优化模型(Hessian矩阵)。
5.分位数损失函数
在大多数真实世界的预测问题中,我们常常希望看到我们预测结果的不确定性。通过预测出一个取值区间而不是一个个具体的取值点,这对于具体业务流程中的决策至关重要。
分位数损失函数在我们需要预测结果的取值区间时是一个特别有用的工具。通常情况下我们利用最小二乘回归来预测取值区间主要基于这样的假设:取值残差的方差是常数。但很多时候对于线性模型是不满足的。这时候就需要分位数损失函数和分位数回归来拯救回归模型了。它对于预测的区间十分敏感,即使在非均匀分布的残差下也能保持良好的性能。下面让我们用两个例子看看分位数损失在异方差数据下的回归表现。
左:线性关系b / w X1和Y.具有恒定的残差方差。右:线性关系b / w X2和Y,但Y的方差随着X2增加。
上图是两种不同的数据分布,其中左图是残差的方差为常数的情况,而右图则是残差的方差变化的情况。我们利用正常的最小二乘对上述两种情况进行了估计,其中橙色线为建模的结果。但是我们却无法得到取值的区间范围,这时候就需要分位数损失函数来提供。
上图中上下两条虚线基于0.05和0.95的分位数损失得到的取值区间,从图中可以清晰地看到建模后预测值得取值范围。
分位数回归的目标在于估计给定预测值的条件分位数。实际上分位数回归就是平均绝对误差的一种拓展。分位数值得选择在于我们是否希望让正的或者负的误差发挥更大的价值。损失函数会基于分位数γ对过拟合和欠拟合的施加不同的惩罚。例如选取γ为0.25时意味着将要惩罚更多的过拟合而尽量保持稍小于中值的预测值。
γ的取值通常在0-1之间,图中描述了不同分位数下的损失函数情况,明显可以看到对于正负误差不平衡的状态。
分位数损失(Y轴)与预测(X轴)
转载:https://www.jianshu.com/p/5c036b636d5b
参考文章:
https://www.jianshu.com/p/b715888f079b
http://baijiahao.baidu.com/s?id=1603857666277651546&wfr=spider&for=pc
https://blog.csdn.net/weixin_37933986/article/details/68488339