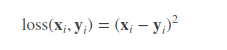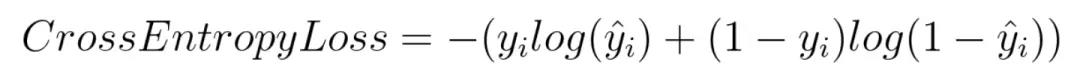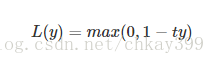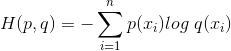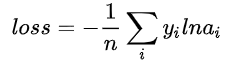1. 概况
损失函数一般分为:0-1 损失函数,HingeLoss,绝对值损失函数,Huber Loss, 平方损失函数,对数损失函数,指数损失。

1. 0-1损失函数(zero-one loss)
0-1损失是指预测值和目标值不相等为1, 否则为0:
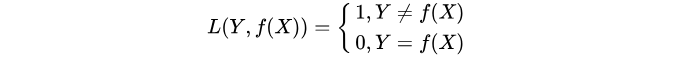
2. 平均绝对值损失函数
平均绝对误差损失,Mean Absolute Error Loss。
J M A E = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ J_{M A E}=\frac{1}{N} \sum_{i=1}^{N}\left|y_{i}-\hat{y}_{i}\right| JMAE=N1i=1∑N∣yi−y^i∣
原理:
假设模型预测与真实值之间的误差服从拉普拉斯分布 Laplace distribution,给定一个 x, 模型输出真实值 y 的概率为:
p ( y i ∣ x i ) = 1 2 exp ( − ∣ y i − y ^ i ∣ ) p\left(y_{i} | x_{i}\right)=\frac{1}{2} \exp \left(-\left|y_{i}-\hat{y}_{i}\right|\right) p(yi∣xi)=21exp(−∣yi−y^i∣)
通过最大似然估计,就可以推导到MAE公式了。
特点:
MAE 损失对于 outlier 更加健壮,即更加不易受到 outlier 影响。
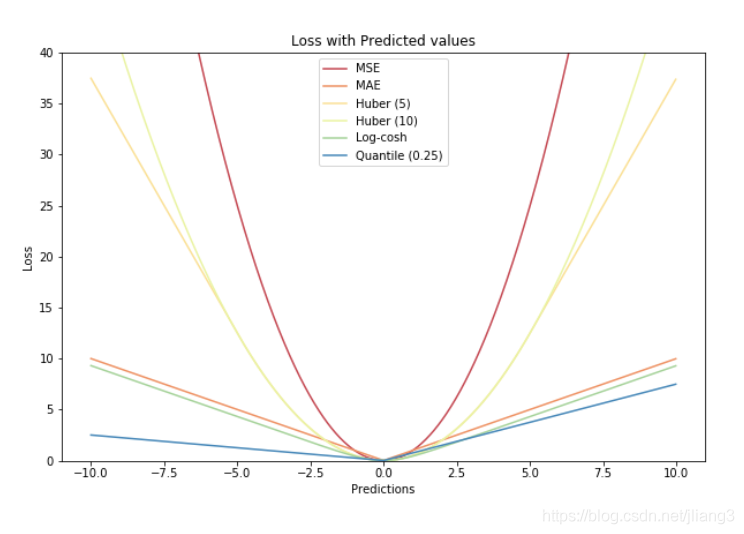
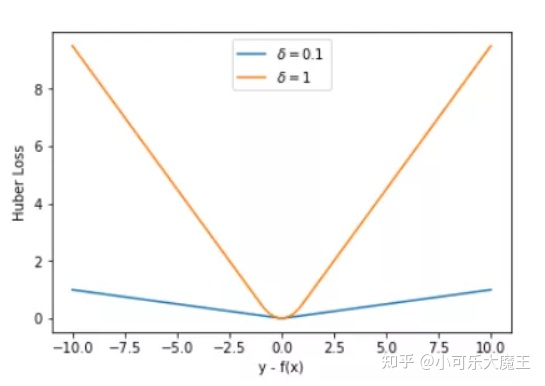
3. Huber Loss
Huber Loss,也称为SmoothL1Loss ,误差在 (-1,1) 上是平方损失,其他情况是 L1 损失,应用于回归。
loss ( x , y ) = 1 n ∑ i z i z i = { 0.5 ( x i − y i ) 2 , if ∣ x i − y i ∣ < 1 ∣ x i − y i ∣ − 0.5 , otherwise \begin{aligned} &\operatorname{loss}(x, y)=\frac{1}{n} \sum_{i} z_{i}\\ &z_{i}=\left\{\begin{array}{ll} 0.5\left(x_{i}-y_{i}\right)^{2}, & \text { if }\left|x_{i}-y_{i}\right|<1 \\ \left|x_{i}-y_{i}\right|-0.5, & \text { otherwise } \end{array}\right. \end{aligned} loss(x,y)=n1i∑zizi={0.5(xi−yi)2,∣xi−yi∣−0.5, if ∣xi−yi∣<1 otherwise
为什么用Huber loss?
平方损失L2的结果是算术均值无偏估计,L1损失函数的结果是中值无偏估计。
但是,平方损失容易被异常点影响。Huber loss 在0点附近是强凸,结合了平方损失和绝对值损失的优点。
4. Hinge Loss:
合页损失,hinge loss, 一种二分类损失函数,适用于 maximum-margin 的分类
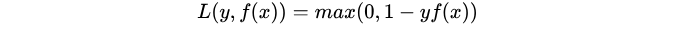
主要用于支持向量机(SVM) 中,用来解 间距最大化 的问题。
J ( w ) = 1 2 ∥ w ∥ 2 + C ∑ i max ( 0 , 1 − y i w T x i ) = 1 2 ∥ w ∥ 2 + C ∑ i max ( 0 , 1 − m i ( w ) ) = 1 2 ∥ w ∥ 2 + C ∑ i L H i n g e ( m i ) \begin{aligned} J(w) &=\frac{1}{2}\|w\|^{2}+C \sum_{i} \max \left(0,1-y_{i} w^{T} x_{i}\right) \\ &=\frac{1}{2}\|w\|^{2}+C \sum_{i} \max \left(0,1-m_{i}(w)\right) \\ &=\frac{1}{2}\|w\|^{2}+C \sum_{i} L_{H i n g e}\left(m_{i}\right) \end{aligned} J(w)=21∥w∥2+Ci∑max(0,1−yiwTxi)=21∥w∥2+Ci∑max(0,1−mi(w))=21∥w∥2+Ci∑LHinge(mi)
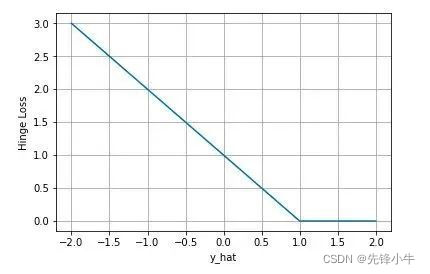
下图是 y(=1) 为正类, 不同输出的合页损失示意图:

当模型输出为正值且在 (0,1) 区间时还会有一个惩罚。即合页损失不仅惩罚预测错的,并且对于预测对了但是置信度不高的也会给一个惩罚,只有置信度高的才会有零损失。
使用合页损失直觉上理解是要找到一个决策边界,使得所有数据点被这个边界正确地、高置信地被分类。
SVM 的损失函数可以看作是 L2-norm 和 Hinge loss 之和。
特点:
(1) 健壮性相对较高,对异常点、噪声不敏感,但它没太好的概率解释。
5. 平方损失函数Squared Loss
常用均方差损失,Mean Squared Error Loss,是回归任务中最常用的一种损失函数。
M S E = 1 n ∑ i = 1 n ( Y ~ i − Y i ) 2 M S E=\frac{1}{n} \sum_{i=1}^{n}\left(\tilde{Y}_{i}-Y_{i}\right)^{2} MSE=n1i=1∑n(Y~i−Yi)2
原理:
假设模型预测与真实值之间的误差服从标准高斯分布,则给定一个 x 模型输出真实值 y 的概率为:
p ( y i ∣ x i ) = 1 2 π exp ( − ( y i − y ^ i ) 2 2 ) p\left(y_{i} | x_{i}\right)=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{\left(y_{i}-\hat{y}_{i}\right)^{2}}{2}\right) p(yi∣xi)=2π1exp(−2(yi−y^i)2)
根据最大似然函数,对数化,就得到MSE公式了。
在模型输出与真实值的误差服从高斯分布的假设下,最小化均方差损失函数与极大似然估计本质上是一致的,因此在这个假设能被满足的场景中(比如回归),均方差损失是一个很好的损失函数选择。
Q:为什么MSE不适合分类问题?
A:首先,分类问题损失并不服从高斯分布;第二点,如果MSE 前面是接sigmoid激活函数,最终求导反向传播是 ( y ^ − y ) ( y ^ ) ( 1 − y ^ ) , y ^ = s i g m o i d ( f ( x ) ) (\hat y-y)(\hat y)(1-\hat y),\hat y= sigmoid(f(x)) (y^−y)(y^)(1−y^),y^=sigmoid(f(x)); 而误差 ( y ^ − y ) (\hat y-y) (y^−y) 比较大时,即 y ^ = s i g m o i d ( f ( x ) ) \hat y= sigmoid(f(x)) y^=sigmoid(f(x))较大或者较小时,梯度都因为 ( y ^ ) ( 1 − y ^ ) (\hat y)(1-\hat y) (y^)(1−y^)而变得很小。
6. log对数损失函数
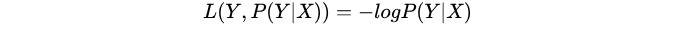
特点:
(1) log对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合。
(2)健壮性不强,相比于hinge loss对噪声更敏感。
(3)逻辑回归的损失函数就是log对数损失函数。
7. 交叉熵损失函数 (Cross-entropy loss function)
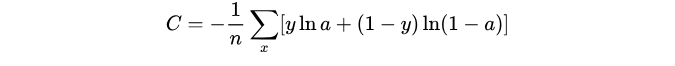
(1)本质上也是一种对数似然函数;
(2)当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数,因为它可以完美解决平方损失函数权重更新过慢的问题,具有 “误差大的时候,权重更新快;误差小的时候,权重更新慢” 的良好性质。
原理:
Q:为什么交叉熵能应用到分类场景中?
A:假设对于样本 x存在一个最优分布 y ∗ y^* y∗ 真实地表明了这个样本属于各个类别的概率.根据KL Loss,可以推导出:
K L ( y i ⋆ , y ^ i ) = ∑ k = 1 K y i ⋆ log ( y i ⋆ ) − ∑ k = 1 K y i ⋆ log ( y ^ i ) K L\left(y_{i}^{\star}, \hat{y}_{i}\right)=\sum_{k=1}^{K} y_{i}^{\star} \log \left(y_{i}^{\star}\right)-\sum_{k=1}^{K} y_{i}^{\star} \log \left(\hat{y}_{i}\right) KL(yi⋆,y^i)=k=1∑Kyi⋆log(yi⋆)−k=1∑Kyi⋆log(y^i)
最后,推导出交叉熵公式。
可以看到,在样本属于每个类别的概率能用分布表示时,通过最小化交叉熵的角度推导出来的结果和使用最大 化似然得到的结果是一致的。
8. Softmax Loss
Softmax Loss可以看做交叉熵应用到多分类场景。假设样本服从伯努利分布(0-1分布),用于逻辑斯谛回归模型。
J C E = − ∑ i = 1 N y i c i log ( y i c ^ i ) J_{C E}=-\sum_{i=1}^{N} y_{i}^{c_{i}} \log \left(y_{i}^{\hat{c}_{i}}\right) JCE=−i=1∑Nyicilog(yic^i)
8. 指数损失函数(exponential loss)
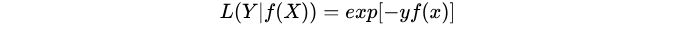
特点:
(1)对离群点、噪声非常敏感。经常用在AdaBoost算法中。
参考:
- 机器学习中的损失函数 (着重比较:hinge loss vs softmax loss);
- 常见的损失函数(loss function)总结;
- (推荐)机器学习常用损失函数小结;
- 二元分类为什么不能用MSE做为损失函数?;