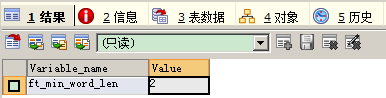
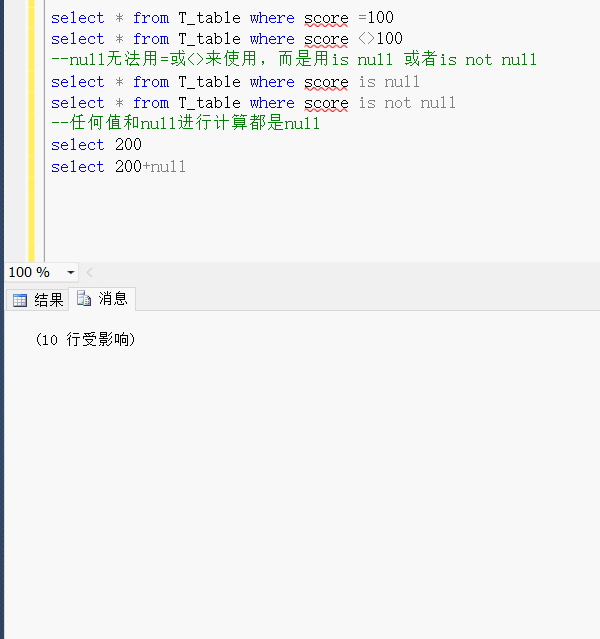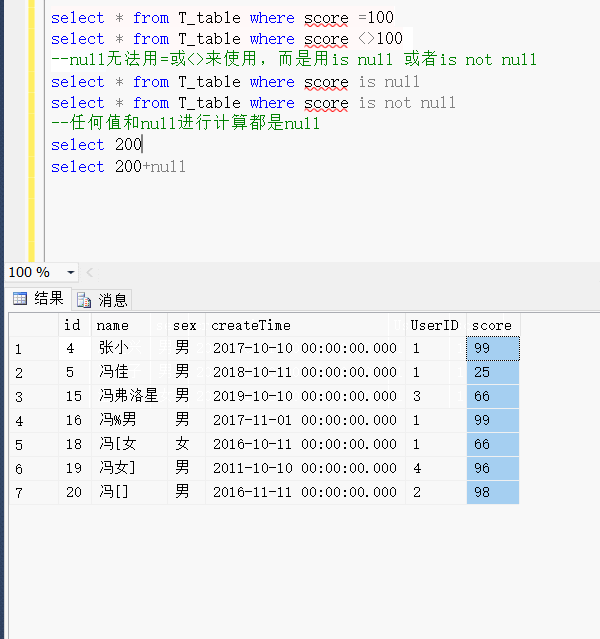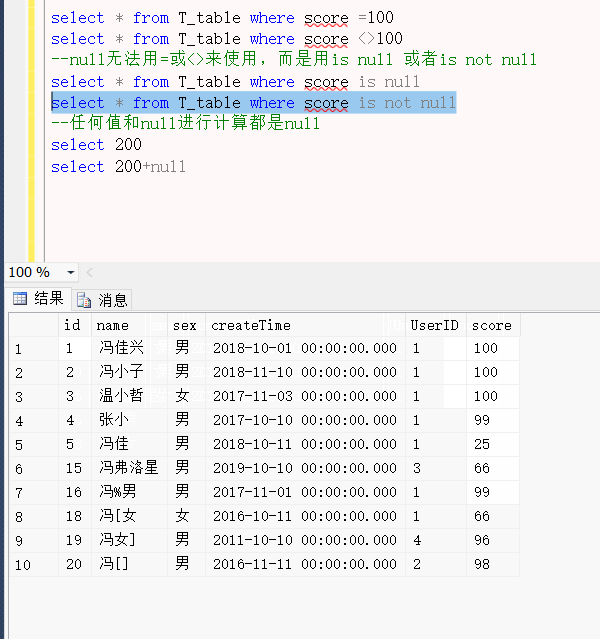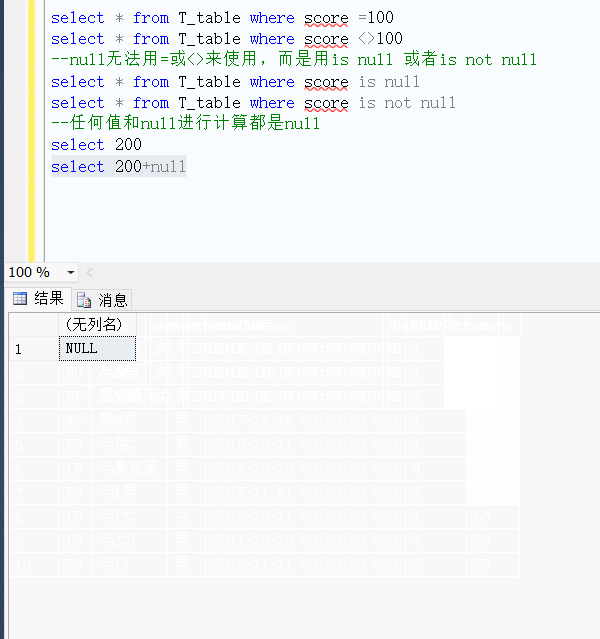
多数数据库,使用 B 树(Balance Tree)的结构来保存索引。
B 树,
最上层节点:根节点
最下层节点:叶子节点
两者之间的节点:中间节点
B 树,显著特征:从根节点,到各个叶子节点的距离都是相等的。如此,检索任何值时,都经过相同数目的节点。
- CREATE INDEX idx_lname_pinyin ON employee(lname_pinyin);
- SHOW INDEX FROM employee\G
- DROP INDEX idx_lname_pinyin ON employee;
伴随主键的定义而创建的特别索引,被称为:丛生索引(
Clustered Index
)
一个表,只有一个丛生索引。
普通的索引,在叶子节点中保存的是指向实际表的指针。
而,丛生索引,在叶子节点中保存的就是实际数据。
丛生索引,
不需要为保存索引,而使用专用的硬盘空间,节约资源
不需要检查索引后,再访问实际的表,提高了效率
创建丛生索引时,需要对表中数据进行排序,因此,在执行数据插入、更新、删除等操作时,比普通索引慢。
复合索引
- CREATE INDEX idx_pinyin ON employee( lname_pinyin, fname_pinyin);
-
- SHOW INDEX FROM employee\G
唯一性索引
使用 UNIQUE 关键字,来创建不可重复的索引,称为:唯一性索引。
对特定列创建唯一性索引,相当于对该列追加了唯一性制约。
创建唯一性索引的时候,如果对象列中,已经含有重复数据,则:创建失败,报错。
创建成功后,如果,插入重复数据,则:插入失败,报错。
指定多个列,来创建唯一性索引,只要,这些列的组合数据不重复,就可以创建成功。
- CREATE UNIQUE INDEX idx_fname ON employee(fname);
- CREATE UNIQUE INDEX idx_lname ON employee(lname);
- CREATE UNIQUE INDEX idx_fullname ON employee(lname, fname);
- EXPLAIN SELECT * FROM employee WHERE lname_pinyin='wang'\G
- CREATE INDEX idx_lname_pinyin ON employee(lname_pinyin);
- EXPLAIN SELECT * FROM employee WHERE lname_pinyin='wang'\G
EXPLAIN 命令的说明:P100 表格
如果,创建索引后,遍历的次数与创建索引之前,变化不大。
说明,创建索引时,选择的列名不合理,需要选择合适的列重建索引。这是分析索引优劣的方法。
追加了索引后,也不能保证在每次检索时都会使用列索引。
如果, SQL 检索语句编写不当,就无法使用索引。
1、LIKE 运算符,进行模糊检索时,只能在前方一致的检索时,才能使用索引。
以下写法,索引不会被使用。
- SELECT * FROM employee WHERE lname_pinyin LIKE '%w%';
- SELECT * FROM employee WHERE lname_pinyin LIKE '%w';
2、使用 IS NOT NULL 、 <> 的场合,也不会使用索引。如下:
- SELECT * FROM employee WHERE lname_pinyin IS NOT NULL;
- SELECT * FROM employee WHERE lname_pinyin <> 'wang';
3、对列使用了运算或者函数的情况下,不会使用索引,如下:
- SELECT * FROM employee WHERE YEAR(birth) = '1980';
- SELECT * FROM employee WHERE birth >= '1980-01-01' AND birth <= '1980-12-31';
4、复合索引的第一列,没有包含在 WHERE 条件语句中,如下:
- CREATE INDEX idx_pinyin ON employee(lname_pinyin, fname_pinyin);
- SELECT * FROM employee WHERE lname_pinyin = 'wang' AND fname_pinyin = 'xiao';
- SELECT * FROM employee WHERE lname_pinyin = 'wang';
-
- SELECT * FROM employee WHERE fname_pinyin = 'xiao';
- SELECT * FROM employee WHERE lname_pinyin = 'wang' OR fname_pinyin = 'xiao';
实际开发过程中,需要积极使用 EXPLAIN 命令,来确认索引的使用情况,及时作相应修改。