今天我们学习一下数据库检索语句,由于经常用到,有需求的小伙伴欢迎来查看哦!
一、简单的查询
--获取所以列
select * from T_table
--获取部分列
select id, title from T_table效果展示:
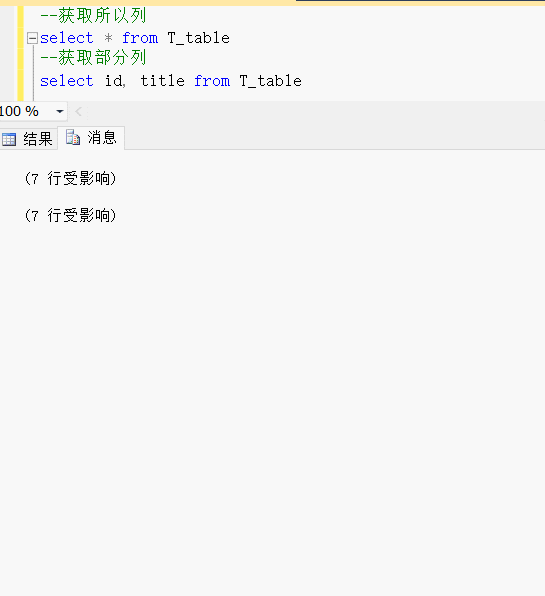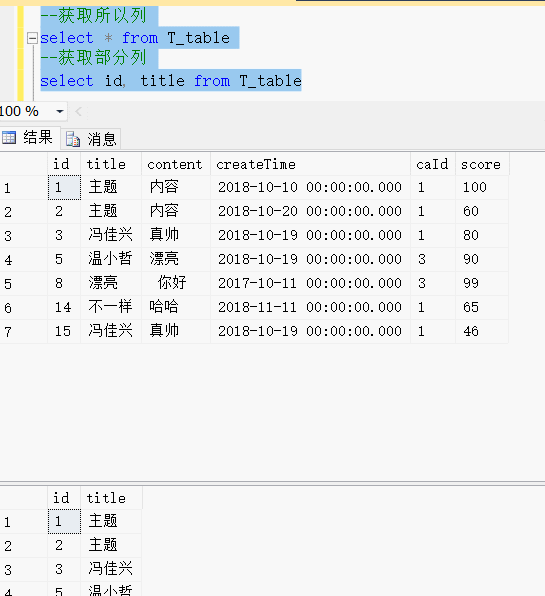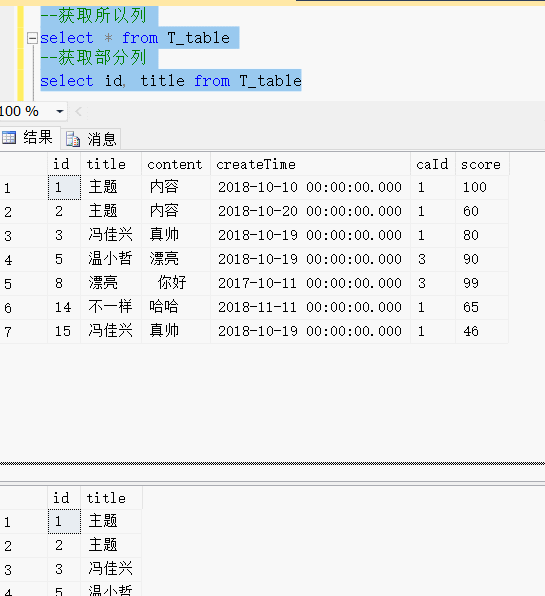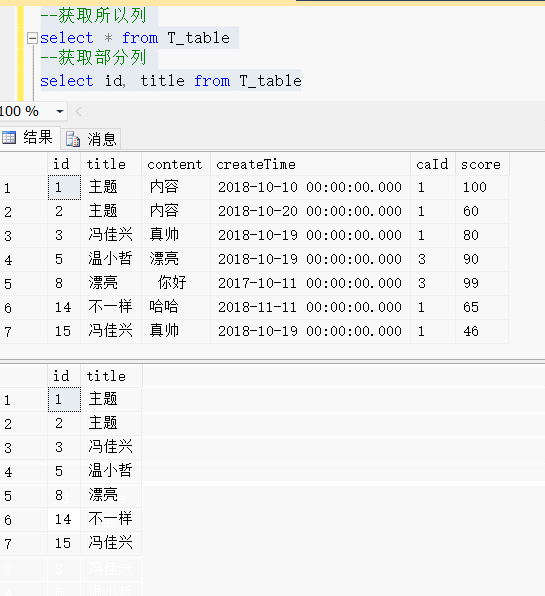
在...之间:Between.. and.. 相当于大于等于80 and 小于等于100
select id from T_table where score >=80 and score <=100select id from T_table where score between 80 and 100
二、为列起别名的三种方式
--为列起别名--方式一
select id as 学号,title as 主题,caId as 注册人from T_table--方式二select 学号=id ,主题=title,注册人=caid from T_table--方式三select id 学号,title 主题,caId 注册人from T_table效果展示:
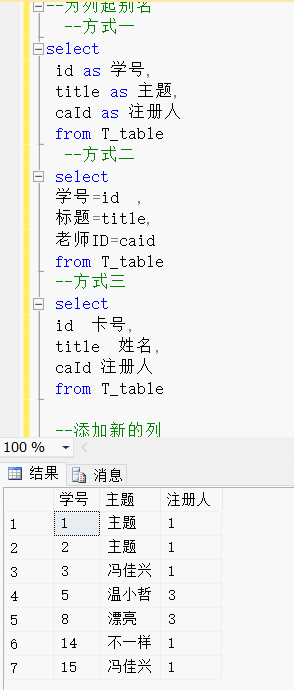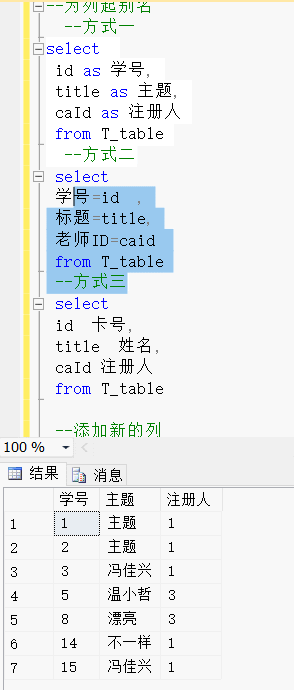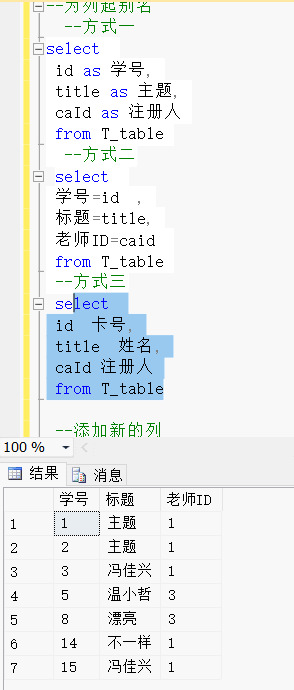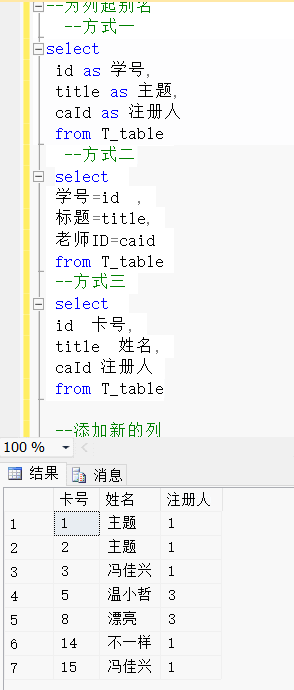
三、添加新列
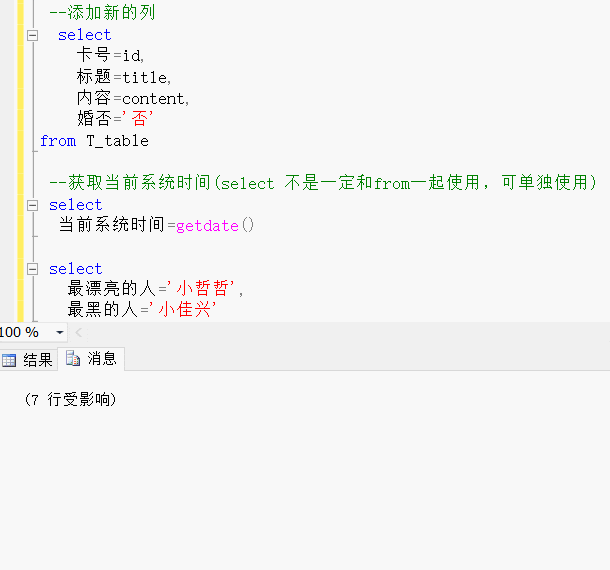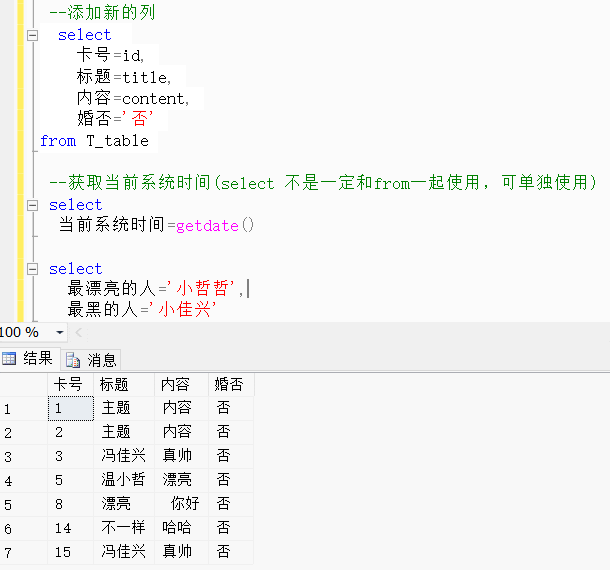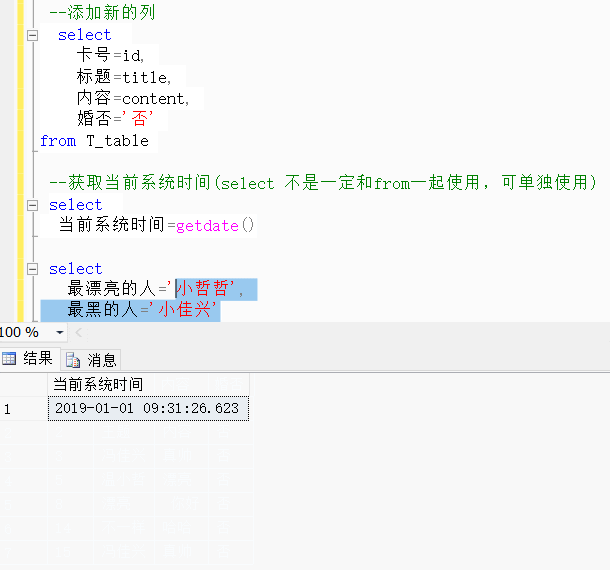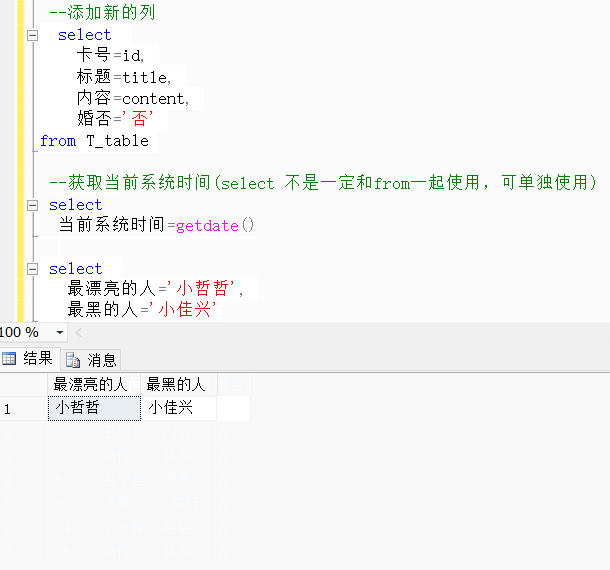
--添加新的列select 卡号=id,标题=title,内容=content,婚否='否'
from T_table --获取当前系统时间(select 不是一定和from一起使用,可单独使用)select 当前系统时间=getdate()select 最漂亮的人='小哲哲',最黑的人='小佳兴'效果展示:
四、排序 、去重 、TOP使用
--distinct,针对已经查询出的结果然后去除重复select * from T_tableselect distinct title from T_table --排序
select * from T_table order by score desc --降序
select * from T_table order by score asc --升序(不写,默认为asc)--top 获取前几条数据,一般与order by连用--top 后面如果是表达式,用括号select top 1 id from T_table order by score descselect top (2*3) * from T_table order by createTime desc--查询成绩最高前35%select top 35 percent * from T_table order by score desc效果展示:
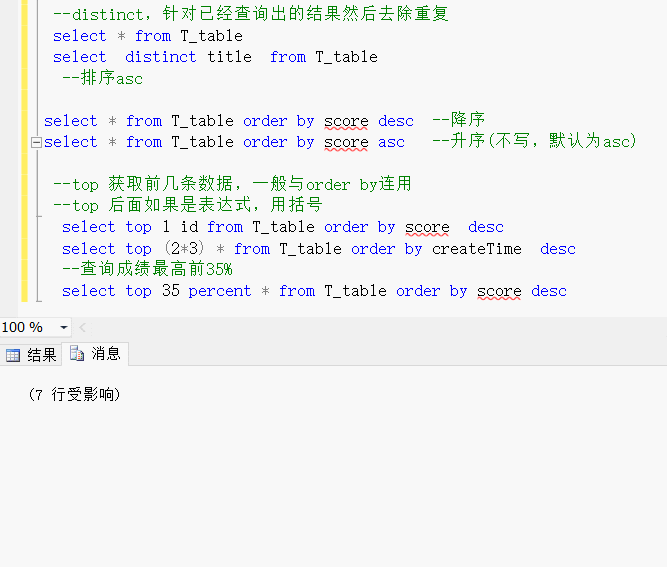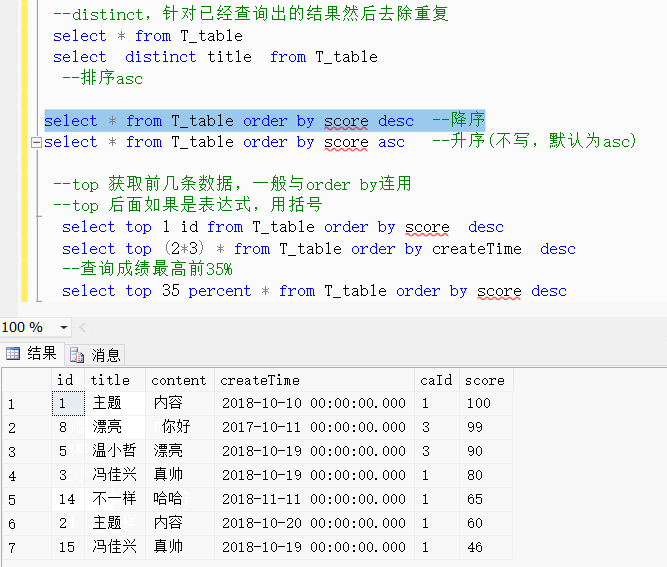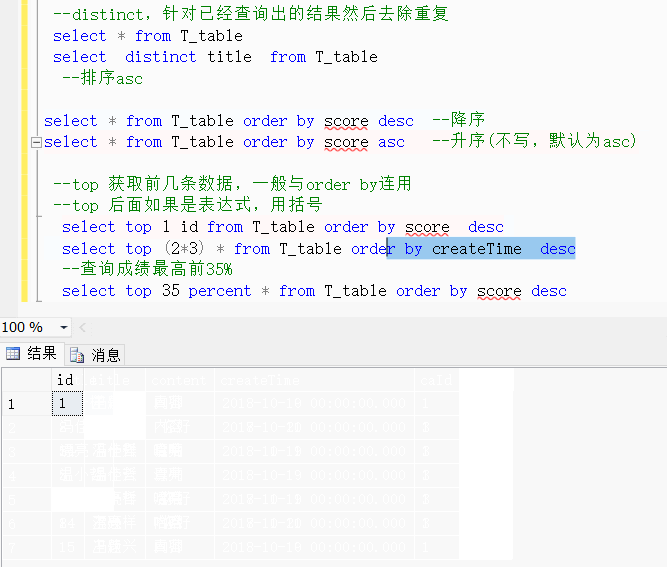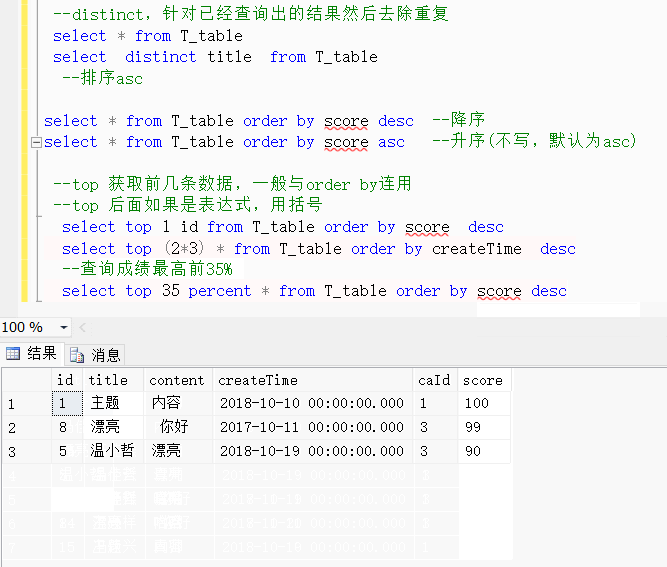
排序精讲
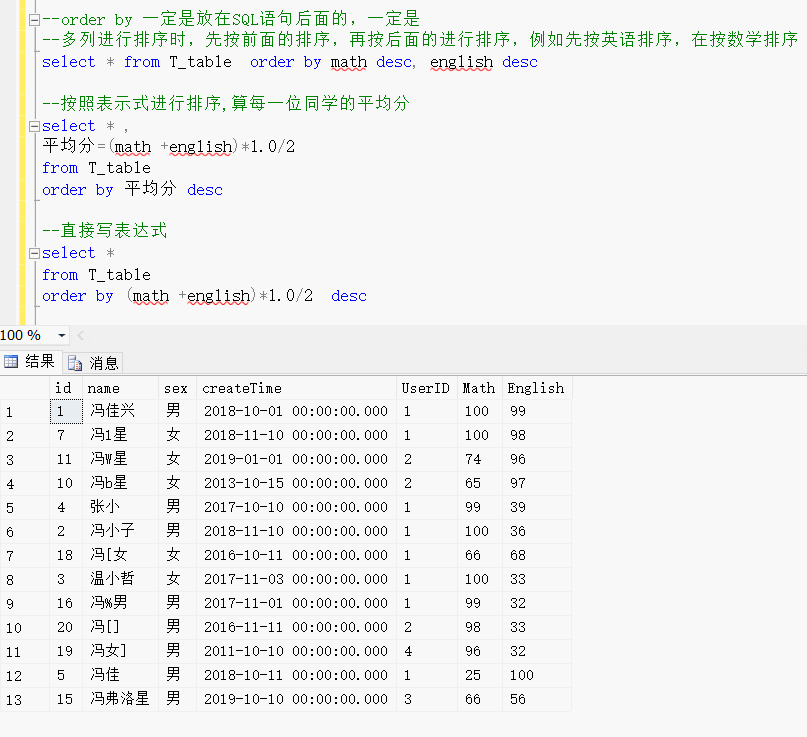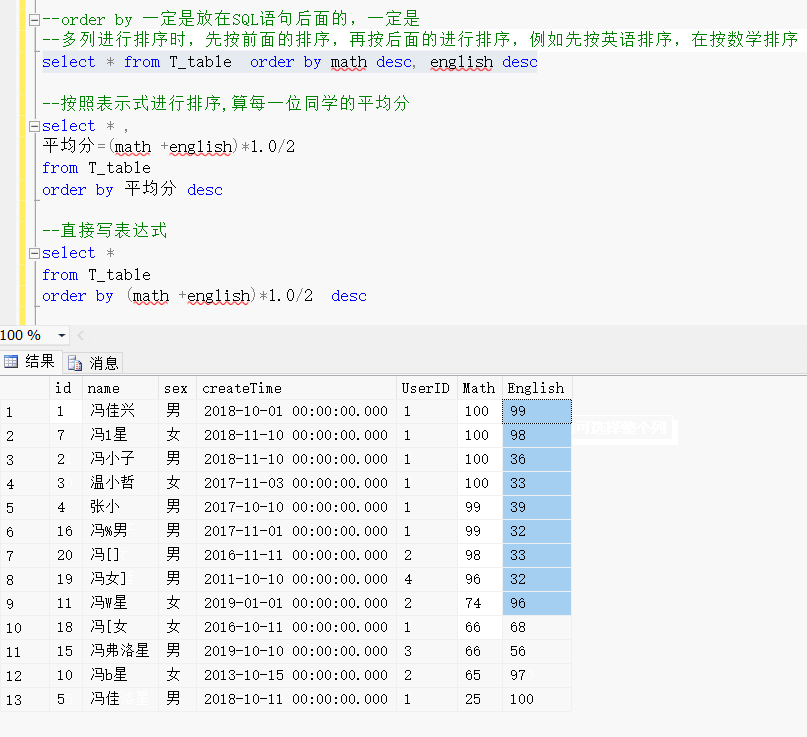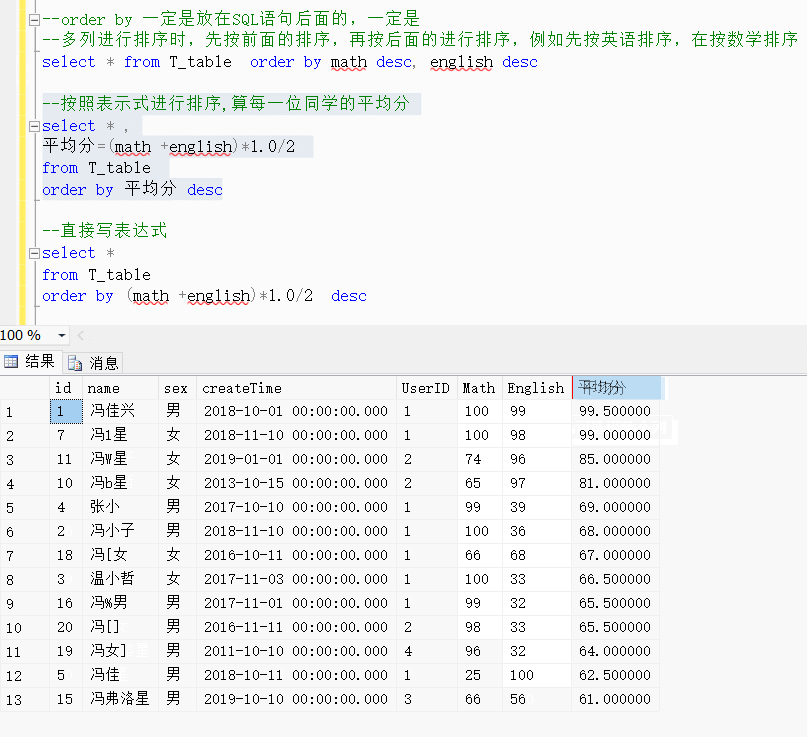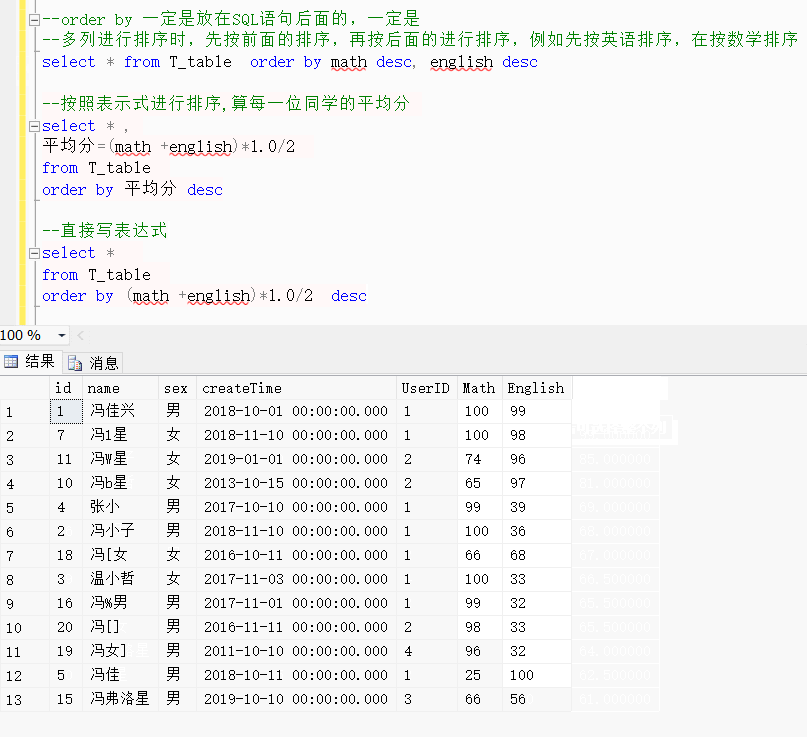
order by 一定是放在SQL语句后面的,一定是放在SQL语句后面的,一定是放在SQL语句后面的
多列进行排序时,先按前面的排序,再按后面的进行排序,例如先按英语排序,在按数学排序
--order by 一定是放在SQL语句后面的,一定是
--多列进行排序时,先按前面的排序,再按后面的进行排序,例如先按英语排序,在按数学排序
select * from T_table order by math desc, english desc--按照表示式进行排序,算每一位同学的平均分
select * ,
平均分=(math +english)*1.0/2
from T_table
order by 平均分 desc--直接写表达式
select *
from T_table
order by (math +english)*1.0/2 desc效果展示
五、模糊查询
六、NULL空值注意事项
1.null无法用=或<>来使用,而是用is null 或者is not null
2.任何值和null进行计算都是null
select * from T_table where score =100
select * from T_table where score <>100
--null无法用=或<>来使用,而是用is null 或者is not null
select * from T_table where score is null
select * from T_table where score is not null
--任何值和null进行计算都是null
select 200
select 200+null 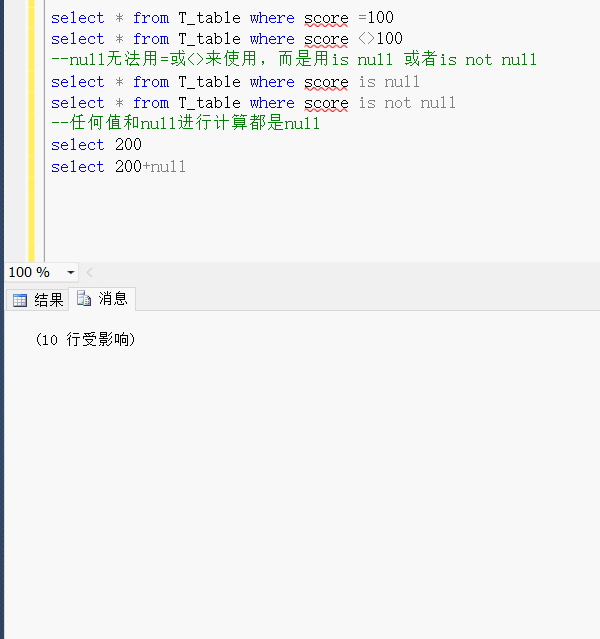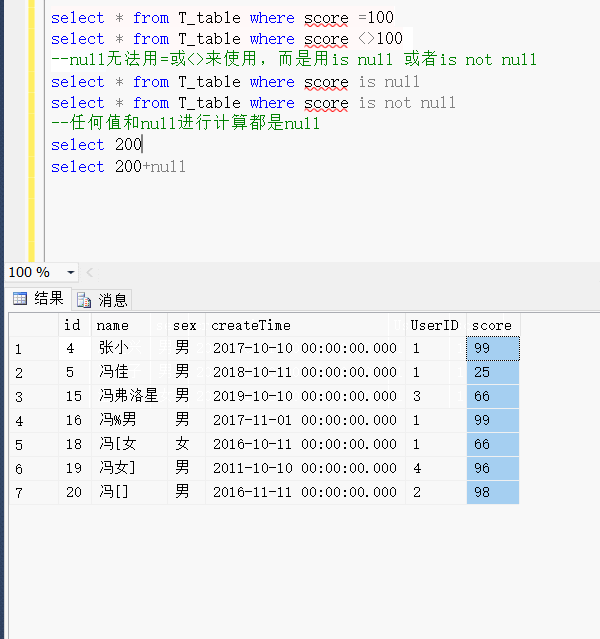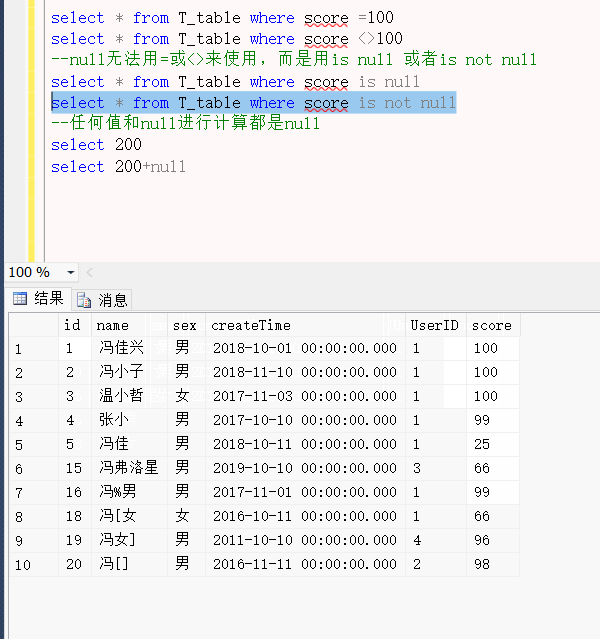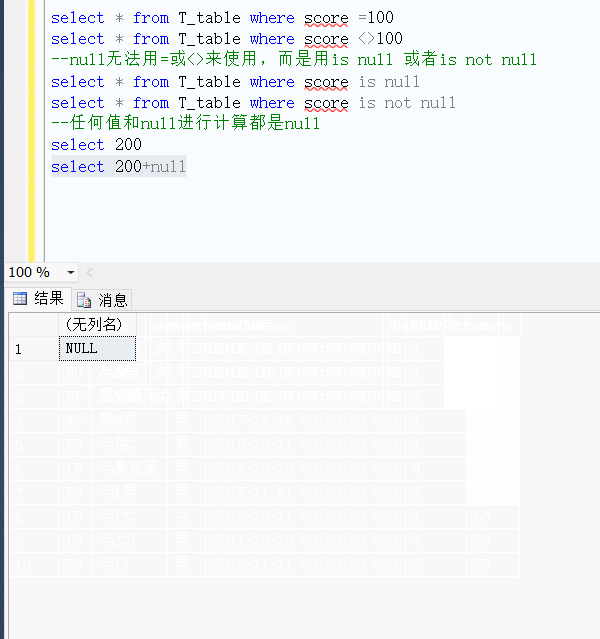
这次机房合作就用到了top,虽然语句很简单,很实用,勤加练习,最近一周每天都会出一篇数据库学习的博客,大家记得查看哦!