目录
快速了解一个领域的情况
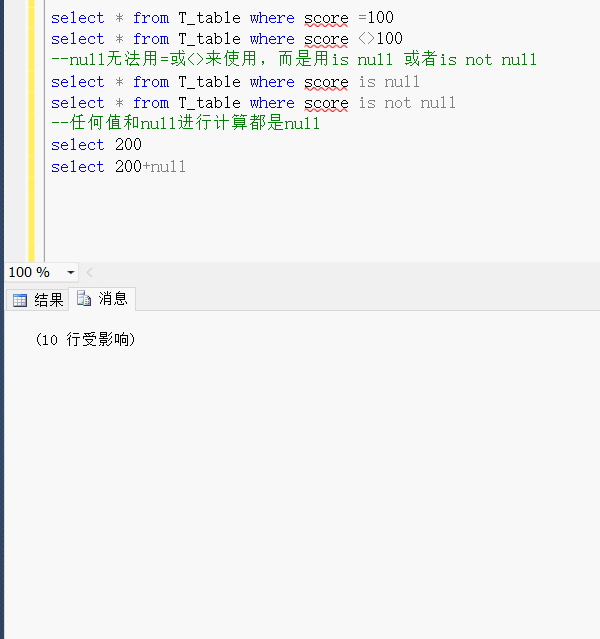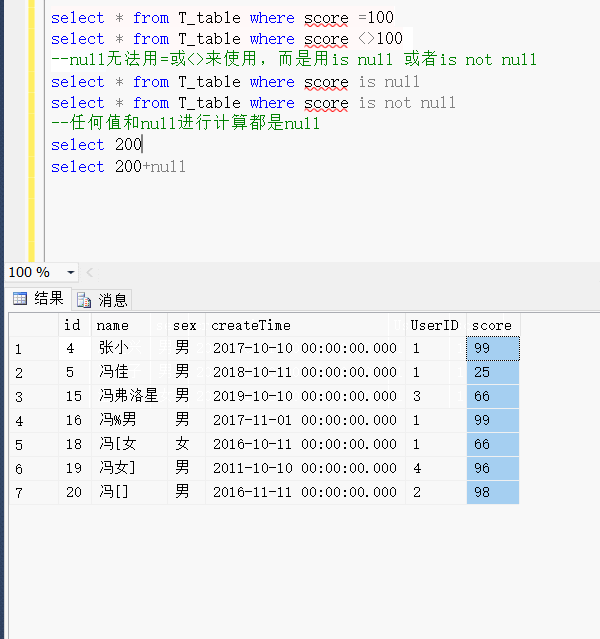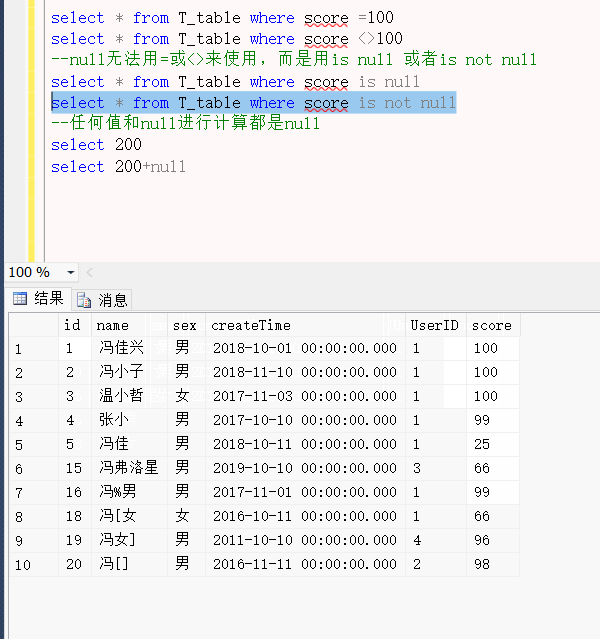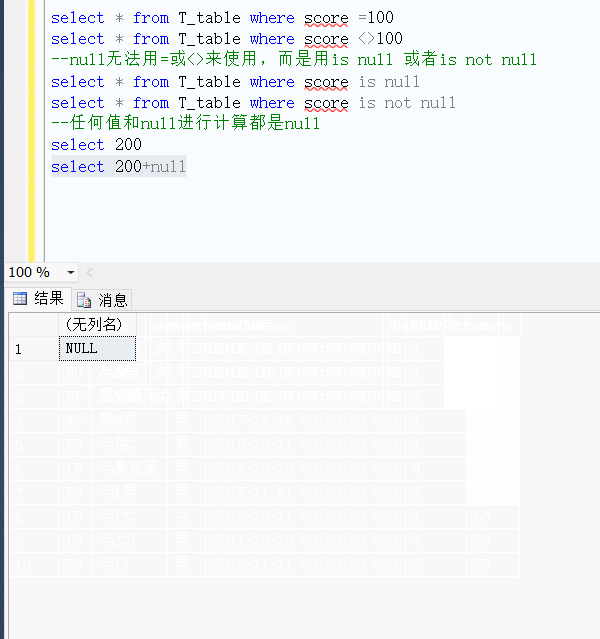
1. 核心合集检索和所有数据库检索的区别
2. 检索结果分析
2.1 排序方式(日期,被引频次)
2.2 分析检索结果
2.3 精炼检索结果(二次检索)
2.4 创建引文报告
2.5 具体某一篇文献
快速了解一个科学家的情况
这个技术可有新进展
快速了解一个领域的情况

1. 核心合集检索和所有数据库检索的区别
- 同一个检索词,所有数据库检索出来的结果比核心合集检索多一些。

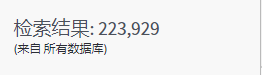
- 核心合集检索的栏位要多一些,还多一个作者检索。检索指南可以参考检索提示。


- 引文报告不可用因为检索结果超过10000条。

2. 检索结果分析
全貌

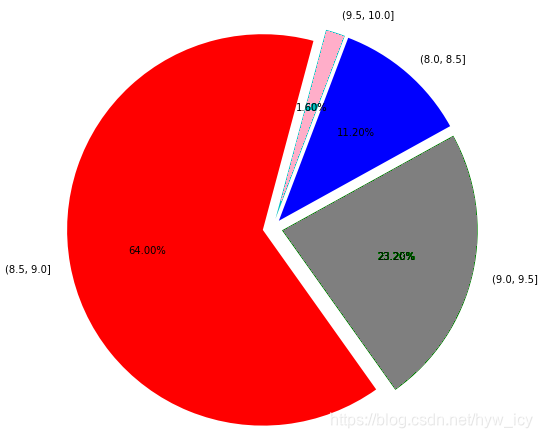
2.1 排序方式(日期,被引频次)
![]()
2.2 分析检索结果
默认按照WoS的类别进行分类。常用的还有出版年、作者、机构,国家。

出版年的图形也可以看出这个领域的活跃度。

作者分类,找到相关研究领域的大牛。

研究机构主要有哪些。

2.3 精炼检索结果(二次检索)
过滤器的选项:高被引论文,热点论文(比较新的)、出版年排序。一般热点论文也是高被引论文。文章类型(综述),WoS学科类别




更多的一些筛选选项如下所示。


出现这种情况是因为同时勾选了高被引论文、综述、2021年三个筛选条件。

2.4 创建引文报告
h-index:共有多少篇文章引用超过多少次。

通过年份被引频次曲线图,可以大致看出该领域的受关注度。如果曲线呈上升趋势,那就是比较活跃的领域。
2.5 具体某一篇文献

快速了解一个科学家的情况

这个技术可有新进展
直接检索论文,然后去看它引用它的论文,按时间排序。