每日鸡汤 :
—— 若你困于无风之地,我将奏响高空之歌要和我一起花 10 min 学一会 SQL 嘛? - 当然愿意,我美丽的小姐
(封寝期间练就的自言自语能力越来越炉火纯青了~~~)
前言:
-
本实验中所用数据库创建SQL代码以及插入数据SQL代码链接:https://pan.baidu.com/s/1hvcR13JJqx_0VXA3bz3rgQ
提取码:2333 -
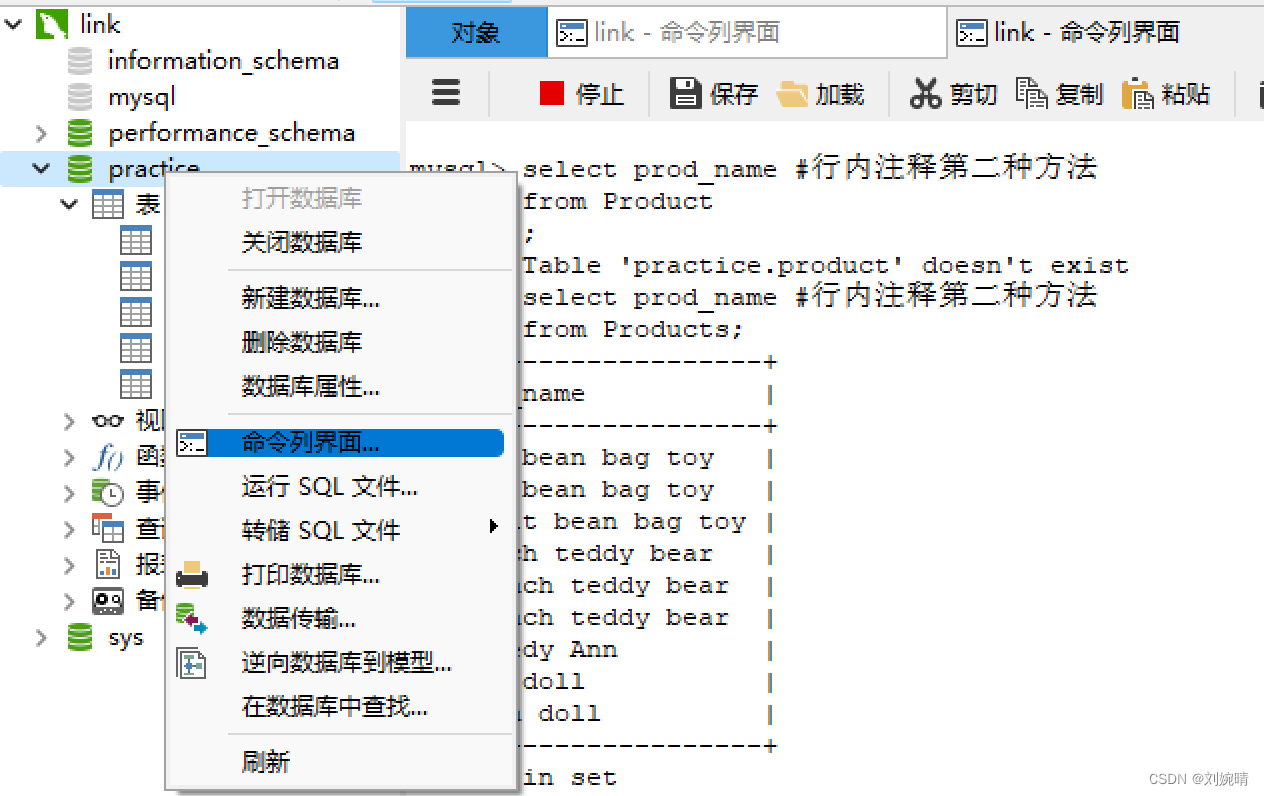
本人用来编写运行 SQL 代码的工具是 Navicat ,将 Navicat 转换为命令行模式的方法如下:鼠标右键自己新建的数据库 ,选择命令行界面
1. select 语句 —— 用于检索所有列
(1)检索单列
从 Product s表中检索名为 prod_name 的列
select prod_name from Products
注意:
- SQL 语句要以 ;分割
- SQL 语句不区分大小写
- SQL 语句忽略空格及空行
(2)检索多个列
select prod_id, prod_name, prod_price from Products;
选择多个列时,列间以逗号分割
(3)检索所有列 : 用 * 表示所有列
select * from Products;
(4)检索不同的值
当我们不希望结果中含有重复值时,用 distinct 关键字修饰
select distinct vend_id from products;
注意: distinct 关键字作用于所有列,不仅仅是紧跟其后的一列,即返回包含指定所有列的不同结果数
(5)限制结果
对这部分功能的实现,不同的数据库具有不同的实现方法,这里以 MySQL 数据库为例。
如果只需返回一定数量的行,使用 limit 字句,如下代码表示限制只返回 5 行
select prod_name from Products limit 5;
也可通过 offset 语句指定从第几行开始向下检索,入下代码表示从第5行开始向下检索 5 行(若不够5行,则有多少返回多少)
注意: MySQL 数据库有第0行
select prod_name from Products limit 5 offset 5;
2. 注释的使用
(1)行内注释
方法一:使用 --,-- 后的内容为注释
select prod_name -- 选择产品名
from Products;
方法二: 使用 # ,# 后的内容为注释
select prod_name #行内注释第二种方法
from Products;
(2)多行注释
使用 /**/
/*测试多行注释*/
select prod_name
from Products;