点击上方“程序员小灰”,选择“置顶公众号”
有趣有内涵的文章第一时间送达!
本文转载自公众号 占小狼的博客
说”JVM内存模型“,有人会说是关于JVM内存分布(堆栈,方法区等)这些介绍,也有地方说(深入理解JVM虚拟机)上说Java内存模型是JVM的抽象模型(主内存,本地内存)。这两个到底怎么区分啊?有必然关系吗?比如主内存就是堆,本地内存就是栈,这种说法对吗?
时间久了,我也把内存模型和内存结构给搞混了,所以抽了时间把JSR133规范中关于内存模型的部分重新看了下。
后来听了好多人反馈:在面试的时候,有面试官会让你解释一下Java的内存模型,有些人解释对了,结果面试官说不对,应该是堆啊、栈啊、方法区什么的(这不是半吊子面试么,自己概念都不清楚)
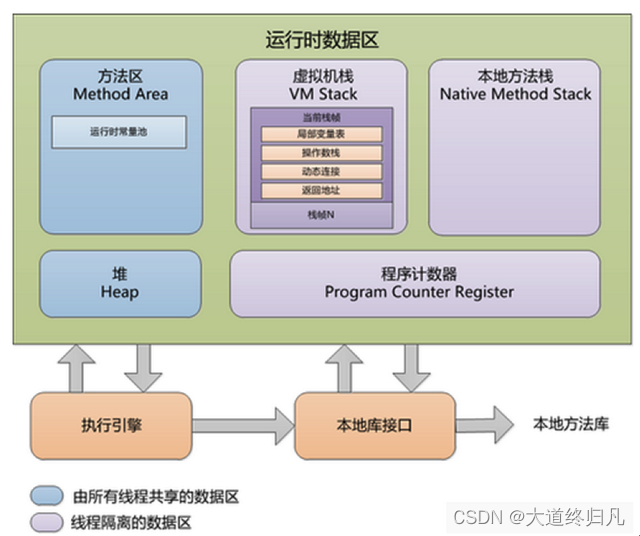
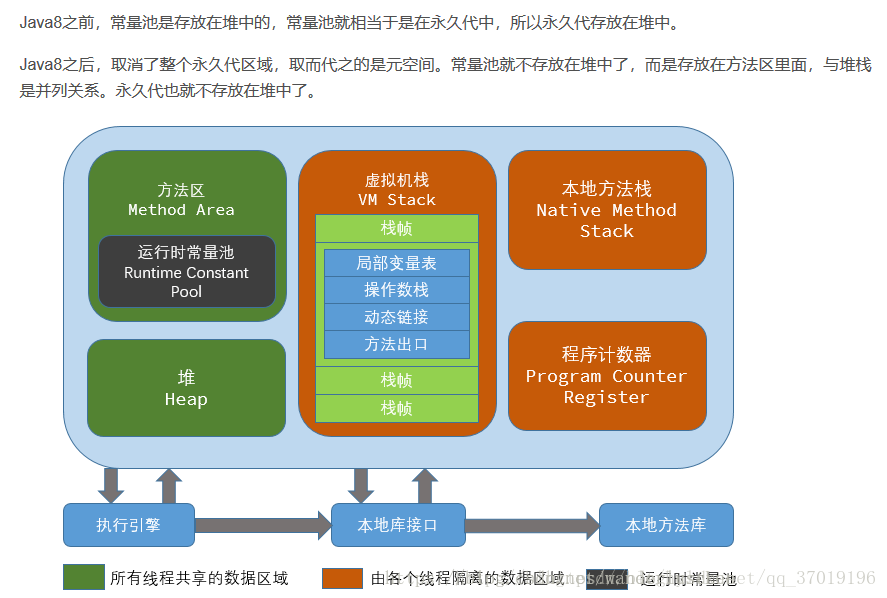
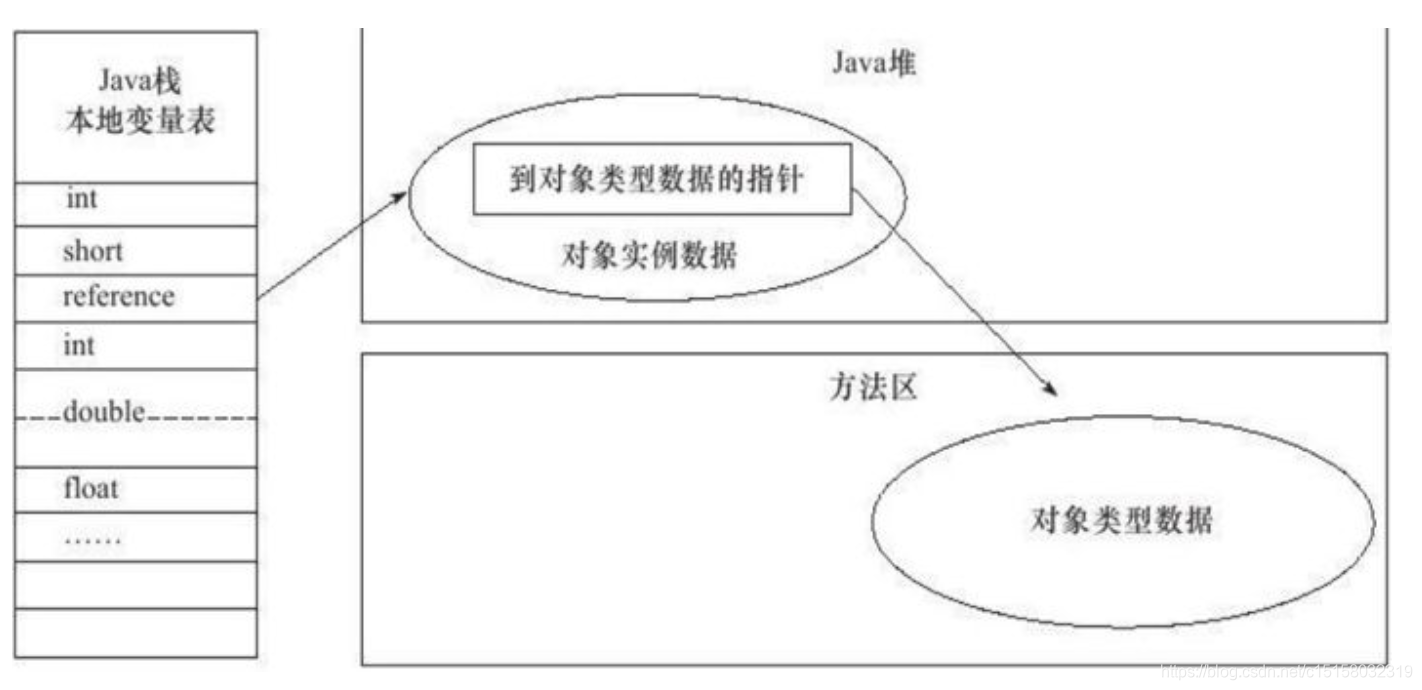
JVM中的堆啊、栈啊、方法区什么的,是Java虚拟机的内存结构,Java程序启动后,会初始化这些内存的数据。
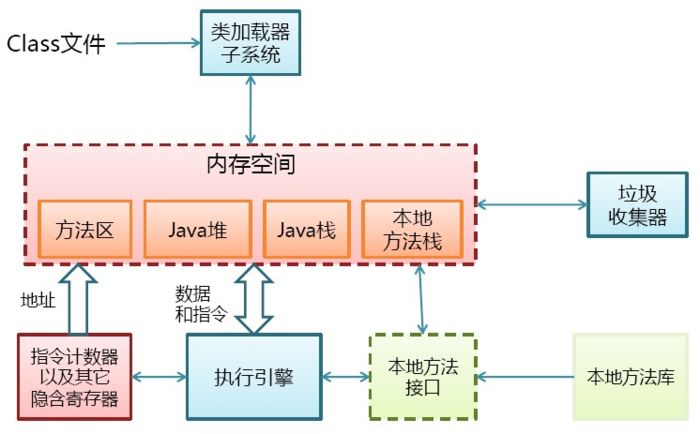
内存结构就是上图中内存空间这些东西,而Java内存模型,完全是另外的一个东西。
什么是内存模型
在多CPU的系统中,每个CPU都有多级缓存,一般分为L1、L2、L3缓存,因为这些缓存的存在,提供了数据的访问性能,也减轻了数据总线上数据传输的压力,同时也带来了很多新的挑战,比如两个CPU同时去操作同一个内存地址,会发生什么?在什么条件下,它们可以看到相同的结果?这些都是需要解决的。
所以在CPU的层面,内存模型定义了一个充分必要条件,保证其它CPU的写入动作对该CPU是可见的,而且该CPU的写入动作对其它CPU也是可见的,那这种可见性,应该如何实现呢?
有些处理器提供了强内存模型,所有CPU在任何时候都能看到内存中任意位置相同的值,这种完全是硬件提供的支持。
其它处理器,提供了弱内存模型,需要执行一些特殊指令(就是经常看到或者听到的,memory barriers内存屏障),刷新CPU缓存的数据到内存中,保证这个写操作能够被其它CPU可见,或者将CPU缓存的数据设置为无效状态,保证其它CPU的写操作对本CPU可见。通常这些内存屏障的行为由底层实现,对于上层语言的程序员来说是透明的(不需要太关心具体的内存屏障如何实现)。
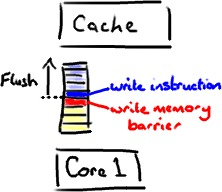
前面说到的内存屏障,除了实现CPU之前的数据可见性之外,还有一个重要的职责,可以禁止指令的重排序。
这里说的重排序可以发生在好几个地方:编译器、运行时、JIT等,比如编译器会觉得把一个变量的写操作放在最后会更有效率,编译后,这个指令就在最后了(前提是只要不改变程序的语义,编译器、执行器就可以这样自由的随意优化),一旦编译器对某个变量的写操作进行优化(放到最后),那么在执行之前,另一个线程将不会看到这个执行结果。
当然了,写入动作可能被移到后面,那也有可能被挪到了前面,这样的“优化”有什么影响呢?这种情况下,其它线程可能会在程序实现“发生”之前,看到这个写入动作(这里怎么理解,指令已经执行了,但是在代码层面还没执行到)。通过内存屏障的功能,我们可以禁止一些不必要、或者会带来负面影响的重排序优化,在内存模型的范围内,实现更高的性能,同时保证程序的正确性。
下面看一个重排序的例子:
Class Reordering {
int x = 0, y = 0;
public void writer() {
x = 1;
y = 2;
}
public void reader() {
int r1 = y;
int r2 = x;
}
}
假设这段代码有2个线程并发执行,线程A执行writer方法,线程B执行reader方法,线程B看到y的值为2,因为把y设置成2发生在变量x的写入之后(代码层面),所以能断定线程B这时看到的x就是1吗?
当然不行! 因为在writer方法中,可能发生了重排序,y的写入动作可能发在x写入之前,这种情况下,线程B就有可能看到x的值还是0。
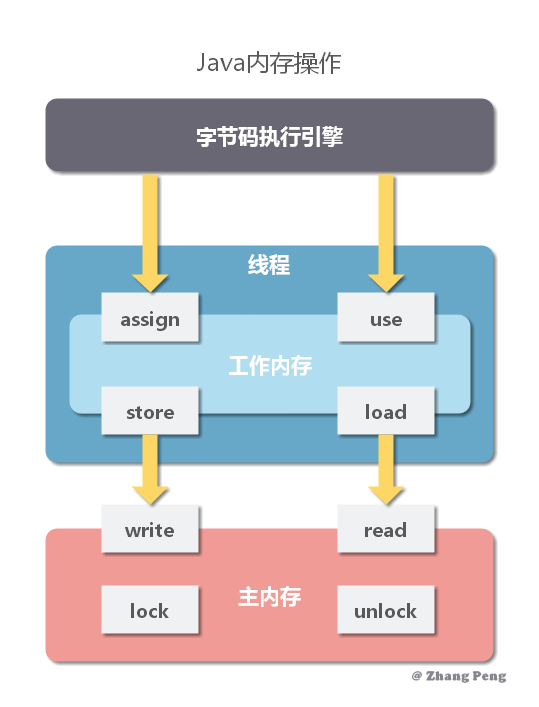
在Java内存模型中,描述了在多线程代码中,哪些行为是正确的、合法的,以及多线程之间如何进行通信,代码中变量的读写行为如何反应到内存、CPU缓存的底层细节。
在Java中包含了几个关键字:volatile、final和synchronized,帮助程序员把代码中的并发需求描述给编译器。Java内存模型中定义了它们的行为,确保正确同步的Java代码在所有的处理器架构上都能正确执行。
### synchronization 可以实现什么 Synchronization有多种语义,其中最容易理解的是互斥,对于一个monitor对象,只能够被一个线程持有,意味着一旦有线程进入了同步代码块,那么其它线程就不能进入直到第一个进入的线程退出代码块(这因为都能理解)。
但是更多的时候,使用synchronization并非单单互斥功能,Synchronization保证了线程在同步块之前或者期间写入动作,对于后续进入该代码块的线程是可见的(又是可见性,不过这里需要注意是对同一个monitor对象而言)。在一个线程退出同步块时,线程释放monitor对象,它的作用是把CPU缓存数据(本地缓存数据)刷新到主内存中,从而实现该线程的行为可以被其它线程看到。在其它线程进入到该代码块时,需要获得monitor对象,它在作用是使CPU缓存失效,从而使变量从主内存中重新加载,然后就可以看到之前线程对该变量的修改。
但从缓存的角度看,似乎这个问题只会影响多处理器的机器,对于单核来说没什么问题,但是别忘了,它还有一个语义是禁止指令的重排序,对于编译器来说,同步块中的代码不会移动到获取和释放monitor外面。
下面这种代码,千万不要写,会让人笑掉大牙:
synchronized (new Object()) {
}
这实际上是没有操作的操作,编译器完成可以删除这个同步语义,因为编译知道没有其它线程会在同一个monitor对象上同步。
所以,请注意:对于两个线程来说,在相同的monitor对象上同步是很重要的,以便正确的设置happens-before关系。
final 可以影响什么
如果一个类包含final字段,且在构造函数中初始化,那么正确的构造一个对象后,final字段被设置后对于其它线程是可见的。
这里所说的正确构造对象,意思是在对象的构造过程中,不允许对该对象进行引用,不然的话,可能存在其它线程在对象还没构造完成时就对该对象进行访问,造成不必要的麻烦。
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x;
int j = f.y;
}
}
}
上面这个例子描述了应该如何使用final字段,一个线程A执行reader方法,如果f已经在线程B初始化好,那么可以确保线程A看到x值是3,因为它是final修饰的,而不能确保看到y的值是4。 如果构造函数是下面这样的:
public FinalFieldExample() { // bad!
x = 3;
y = 4;
// bad construction - allowing this to escape
global.obj = this;
}
这样通过global.obj拿到对象后,并不能保证x的值是3.
volatile可以做什么
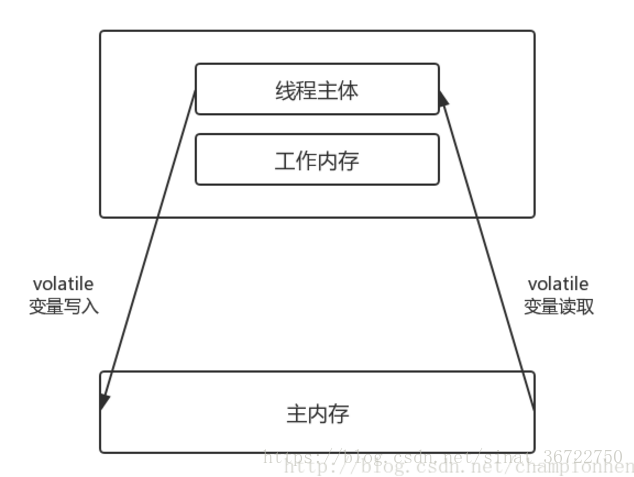
Volatile字段主要用于线程之间进行通信,volatile字段的每次读行为都能看到其它线程最后一次对该字段的写行为,通过它就可以避免拿到缓存中陈旧数据。它们必须保证在被写入之后,会被刷新到主内存中,这样就可以立即对其它线程可以见。类似的,在读取volatile字段之前,缓存必须是无效的,以保证每次拿到的都是主内存的值,都是最新的值。volatile的内存语义和sychronize获取和释放monitor的实现目的是差不多的。
对于重新排序,volatile也有额外的限制。
下面看一个例子:
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
//uses x - guaranteed to see 42.
}
}
}
同样的,假设一个线程A执行writer,另一个线程B执行reader,writer中对变量v的写入把x的写入也刷新到主内存中。reader方法中会从主内存重新获取v的值,所以如果线程B看到v的值为true,就能保证拿到的x是42.(因为把x设置成42发生在把v设置成true之前,volatile禁止这两个写入行为的重排序)。
如果变量v不是volatile,那么以上的描述就不成立了,因为执行顺序可能是v=true, x=42,或者对于线程B来说,根本看不到v被设置成了true。
double-checked locking的问题
臭名昭著的双重检查(其中一种单例模式),是一种延迟初始化的实现技巧,避免了同步的开销,因为在早期的JVM,同步操作性能很差,所以才出现了这样的小技巧。
private static Something instance = null;
public Something getInstance() {
if (instance == null) {
synchronized (this) {
if (instance == null)
instance = new Something();
}
}
return instance;
}
这个技巧看起来很聪明,避免了同步的开销,但是有一个问题,它可能不起作用,为什么呢?因为实例的初始化和实例字段的写入可能被编译器重排序,这样就可能返回部门构造的对象,结果就是读到了一个未初始化完成的对象。
当然,这种bug可以通过使用volatile修饰instance字段进行fix,但是我觉得这种代码格式实在太丑陋了,如果真要延迟初始化实例,不妨使用下面这种方式:
private static class LazySomethingHolder {
public static Something something = new Something();
}
public static Something getInstance() {
return LazySomethingHolder.something;
}
由于是静态字段的初始化,可以确保对访问该类的所以线程都是可见的。
对于这些,我们需要关心什么
并发产生的bug非常难以调试,通常在测试代码中难以复现,当系统负载上来之后,一旦发生,又很难去捕捉,为了确保程序能够在任意环境正确的执行,最好是提前花点时间好好思考,虽然很难,但还是比调试一个线上bug来得容易的多。
—————END—————
喜欢本文的朋友们,欢迎长按下图关注订阅号程序员小灰,收看更多精彩内容