文章目录
- 什么是LFU?
- 设计思路
- 代码实现(基础版本)
- 参考论文
- 代码实现(优化版本)
- 区别
什么是LFU?
LRU及其实现
上文讲解了LRU,他是一个基于最近是否被访问来做缓存淘汰的策略。
那么今天介绍一个新的,LFU (Least Frequently Used)最不经常使用。
即淘汰访问频率最低的元素。
LFU 和 LRU 的区别,LRU 的淘汰规则是基于访问时间,而 LFU 是基于访问次数。
其思想依据是:如果数据最近被访问过,那么将来被访问的几率也更高。
当然,如果直接存储的是访问的频次,那么很可能出现一个问题:缓存污染
首先,如果一个数据在早期比如初始化加载的时候,我们需要多次的访问,但是这个数据在初始化完毕之后几乎不会再被访问,但是由于一开始他的访问次数特别高,所以并不会被淘汰而是一直占用空间,那么就会导致无用数据一直占用缓存,也就是我们所谓的缓存污染。
那么为了解决这个问题,我们可以把访问时间也纳入为是否淘汰缓存的一个因素之一。
这个算法的名字叫做,LFU-Aging。
虽然LFU-Aging考虑时间因素,但其算法并不直接记录数据的访问时间,而是通过平均引用计数来标识时间。
LFU-Aging在LFU的基础上,增加了一个最大平均引用计数。当当前缓存中的数据“引用计数平均值”达到或者超过“最大平均引用计数”时,则将所有数据的引用计数都减少。减少的方法有多种,可以直接减为原来的一半,也可以减去固定的值等。(Redis的底层就考虑了这种算法)
设计思路
与LRU差不多,作为缓存淘汰策略,LFU也应该保证获取和放入数据的速度是极快的。
有了LRU的基础,我们就知道,为了快速的获取数据,我们可以使用HashMap,用其快速的get到某一个具体的key。
同时,LFU相比于LRU还需要保存一个访问的频次,那么很容易可以想到创建一个key-freq(访问频次)的HashMap。当然,如果真的这样子设计,那么我们需要遍历一整个HashMap才能得到那个访问频次最小的key,很明显不太合适。我们可以反转一下,freq-key,也就是访问频次对应一个key,当然,由于同一访问频次可能对应多个key,所以我们可以设定结构为freq-List
从上总结,我们可以得到如下设计思路:
1:使用一个HashMap存储key到value的映射,并且通过get(key)快速得到value。
2:使用一个HashMap存储key到freq的映射,就可以快速得到key对应的freq。
需要存储一个freq到key的映射,用来找到最小的freq对应的key。可能有多个key拥有相同的freq,所以freq对key是一对多的关系,即一个freq对应一个key的列表(List)。
3:freq对应的key的列表是存在时序的,便于快速查找并删除最旧的key。
4:能够快速删除key列表中的任何一个key,因为如果频次为freq的某个key被访问,那么它的频次就会变成freq+1,就应该从freq对应的key列表中删除,加到freq+1对应的key的列表中。
我们现在逐点分析设计思路:
1:存储真正的数据
我们的键可以设置为String类型,值对应的为Node类型。
之所以为Node类型是因为,在第二点中我们提到了,我们需要使用到List类型,也就是链表类型,这意味着,为了方便我们更快的在链表中插入和删除数据,同时删除Hash表中的数据,我们应该保证能从链表中也能获取到Key,所以这里使用的是Node<K,V>类型
2:存储访问的频率
上面分析我们得出,我们的key应该是频率freq,那么我们可以设定为一个Long/Integer类型。
而value我们设定为一个List< Node >类型。
3:为了保证时序,我们其实可以用链表来做到,在JDK1.8之后的HashMap中的链表,使用的是尾插法,那么头节点就是最旧的数据。
4:要求快速访问数据,并且要求能快速的插入和删除数据,很明显,可以使用LinkedHashSet。
代码实现(基础版本)
package com.base.learn.cache;import org.junit.platform.commons.util.CollectionUtils;import java.util.*;
import java.util.Map.Entry;public class LFUCache<V> {private Map<String, Node<V>> cache = null;private Map<Long, LinkedHashSet<Node<V>>> countMap = null;private int capacity = 0;private int size = 0;public LFUCache(int capacity) {this.capacity = capacity;this.countMap = new HashMap<>();cache = new LinkedHashMap<>(capacity, 0.75f, true);}public V get(String key){Node<V> node = cache.get(key);if (node==null){return null;}node.count++;node.lastGetTime=System.nanoTime();cache.put(key,node);LinkedHashSet<Node<V>> set = countMap.get(node.count);if (set==null){set = new LinkedHashSet<>();}set.add(node);countMap.put(node.count,set);return node.value;}public void put(String key, V value) {size++;//更新操作if (cache.get(key) != null) {cache.remove(key);size--;}Node<V> node = new Node<V>();node.value = value;//由于是更新操作 把使用次数设定为1node.count = 1;node.lastGetTime = System.nanoTime();//判断是否还有空间存放if (size <= this.capacity) {cache.put(key, node);} else {//没有空间则移除那个访问频次最少的数据removeLastNode();if (cache.size() < this.capacity) {cache.put(key, node);}}}// 淘汰最少使用的缓存private void removeLastNode() {long minCount = 0; //最小的计数数long oldestGetTime = 0; //最老的获取时间String waitRemoveKey = null; //等待要删除的keylong flag = 0; //表示当前遍历的数据的个数//首先获取到cache缓存中的所有节点//然后去记录了频次的链表中再去查找频次最低,访问时间最早的数据//然后删除这个数据Set<Entry<String, Node<V>>> cacheSet = this.cache.entrySet();LinkedHashSet<Entry<String, Node<V>>> linkedHashSet = new LinkedHashSet<>(cacheSet);Iterator<Entry<String, Node<V>>> iterator = linkedHashSet.iterator();while (iterator.hasNext()) {Entry<String, Node<V>> entry = iterator.next();flag++;String key = entry.getKey();long count = entry.getValue().count;long lastGetTime = entry.getValue().lastGetTime;//判断当前记录是否是第一条记录if (flag == 1) {minCount = count;waitRemoveKey = key;oldestGetTime = entry.getValue().lastGetTime;if (minCount == 1) { //是第一条记录并且访问次数为最少的1break; //直接退出循环并且删除该数据}}//判断当前数据是否count数更小if (count < minCount) {minCount = count;waitRemoveKey = key;oldestGetTime = lastGetTime;}if (minCount == count) {//两条记录他们的访问次数一样//访问次数一样并且数据的访问时间更老if (oldestGetTime > lastGetTime) {minCount = count;waitRemoveKey = key;oldestGetTime = lastGetTime;}}}//删除数据if (waitRemoveKey != null) {this.cache.remove(waitRemoveKey);}}class Node<V> {public V value;public long count;public long lastGetTime;}public static void main(String[] args) {LFUCache<Integer> cache = new LFUCache(2);cache.put("1", 1);cache.put("2", 2);cache.put("3", 3);//空间不足 剔除1 放入3System.out.println(cache.get("3"));System.out.println(cache.get("2"));//空间不足 此时有3 2 ,访问次数都为1,但是3的访问时间更久之前,剔除3cache.put("4", 4);System.out.println(cache.get("3"));System.out.println(cache.get("4"));System.out.println(cache.get("2"));}}参考论文
早期的LFU算法的实现是基于堆排序的,时间复杂度做不到O(1),后来有人提出了使用Hash+Set+链表的方式来优化,使得时间复杂度达到了O(1),下面是那篇论文。
论文链接
考虑一个HTTP协议的缓存网络代理应用程序。这种代理通常位于互联网和用户或一组用户之间。它确保所有用户都能够访问互联网,并能够共享所有可共享资源,以实现最佳的网络利用率和改进的响应性。
这样的缓存代理应该尝试在有限的存储或内存量中最大限度地缓存数据量。
通常,许多静态资源,如图像、CSS样式表和javascript代码,在被新版本取代之前,可以很容易地缓存相当长的时间。这些静态资源或程序员所说的“资产”几乎包含在每个页面中,因此缓存它们是最有益的,因为几乎每个请求都将需要它们。
此外,由于网络代理需要每秒处理数千个请求,因此这样做所需的开销应该保持在最低限度。
为此,它应该只驱逐那些不经常使用的资源。因此,应保留经常使用的资源,以牺牲不经常使用的资源为代价,因为前者在一段时间内已证明是有用的。当然,也有相反的观点认为,可能已经被广泛使用的资源在未来可能不再需要,但我们观察到,在大多数情况下,情况并非如此。例如,频繁使用的页面的静态资源总是由该页的每个用户请求。
因此,当内存不足时,这些缓存代理可以使用LFU缓存替换策略来驱逐其缓存中使用频率最低的项。
LRU在这里也可能是一种适用的策略,但是当请求模式是这样的,即所有请求的项都不适合缓存,并且以轮询方式请求这些项时,它将失败。在LRU的情况下,条目会不断地进入和离开缓存,而没有用户请求击中缓存。然而,在相同的条件下,LFU算法将执行得更好,大多数缓存项都会导致缓存命中。
LFU算法的病态行为并非不可能发生。在这里,我们并不是试图为LFU提供一个案例,而是试图表明,如果LFU是一种适用的策略,那么就有一种比以前发表的更好的方法来实现它。
LFU缓存支持的字典操作。
当我们谈到缓存清除算法时,我们主要需要关注对缓存数据的3种不同操作。
- 在缓存中设置(或插入)项
- 检索(或查找)缓存中的项;同时增加其使用计数(对于LFU)
- 从缓存中取出(或删除)最不常用的(或根据取出算法的策略指定的)项
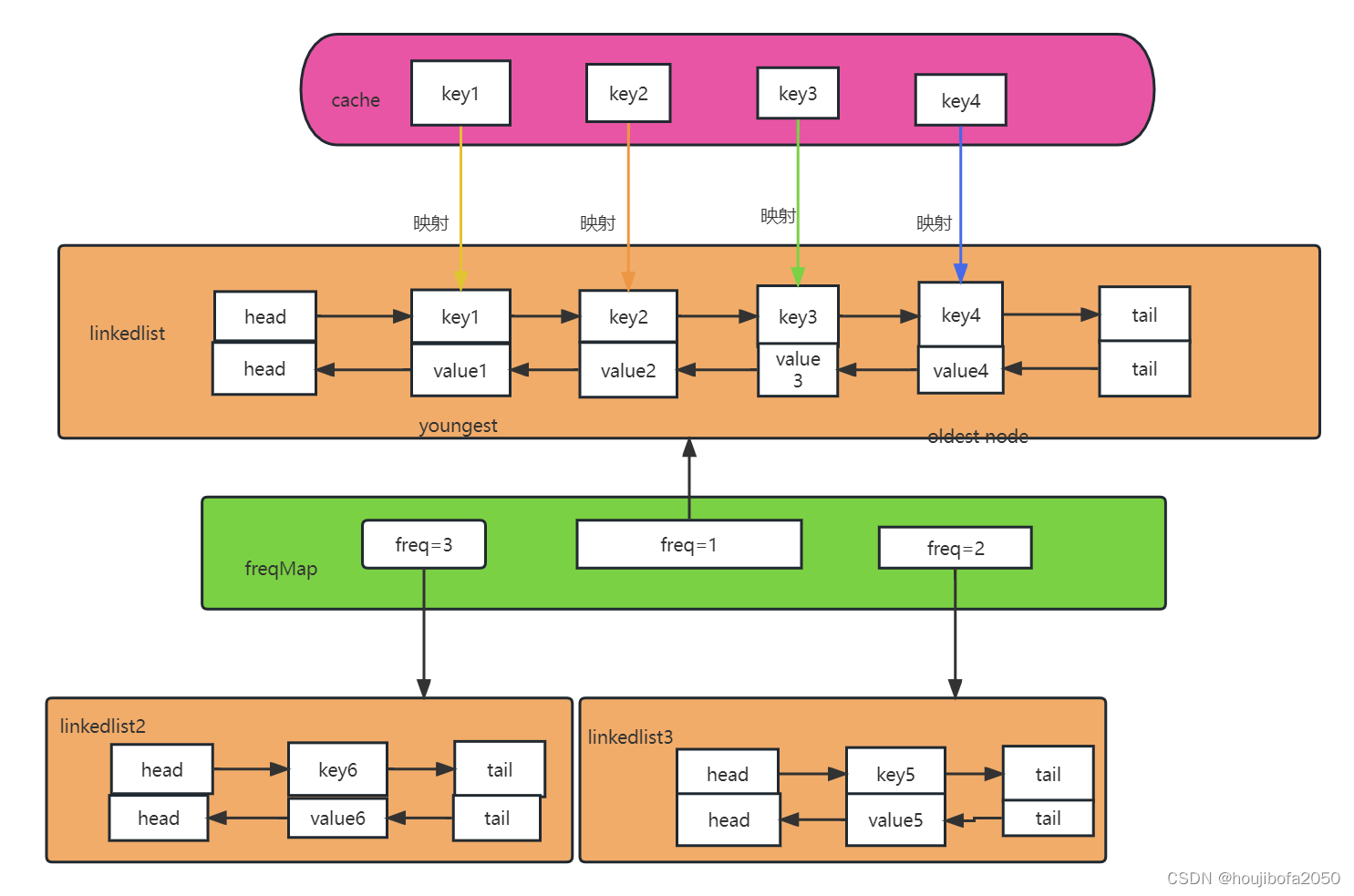
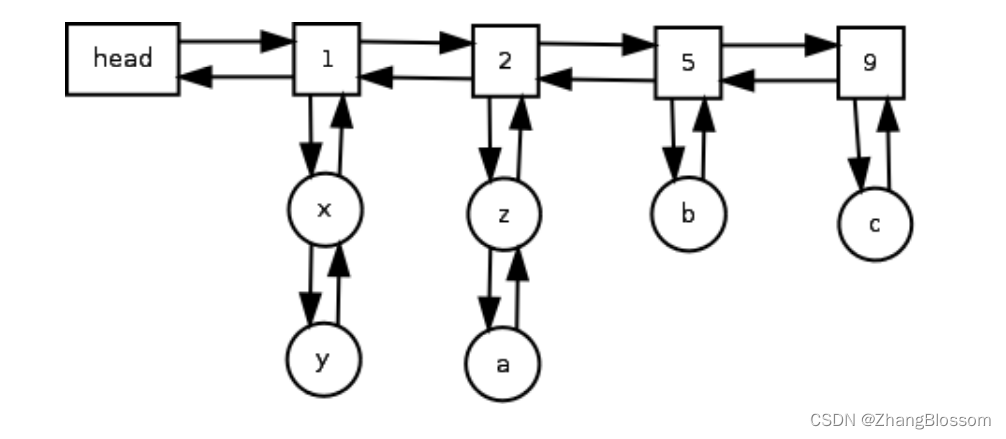
对于可以在LFU缓存上执行的每个字典操作(插入、查找和删除),所提出的LFU算法的运行时复杂度为O(1)。这是通过维护两个链表实现的:一个是访问频率,另一个是所有具有相同访问频率的元素。
哈希表用于按键访问元素(为了清晰起见,没有在下面的图中显示)。双链表用于将节点连接在一起,这些节点表示具有相同访问频率的一组节点(在下面的图中以矩形块表示)。
我们把这个双链表称为频率表。具有相同访问频率的这组节点实际上是这样的节点的双链表(如下图中的圆形节点所示)。我们将这个双链表(它是特定频率的本地链表)称为节点表。节点列表中的每个节点都有一个指向其在频率列表中的父节点的指针(为了清晰起见,没有在图中显示)。因此,节点x和y将有一个指向节点1的指针,节点z和a将有一个指向节点2的指针
依此类推……
下面的伪代码显示了如何初始化LFU缓存。用于按键定位元素的哈希表由变量key表示。为了简化实现,我们使用SET代替链表来存储具有相同访问频率的元素。
我们使用SET代替链表来保存具有相同访问频率的元素的键。它的插入、查找和删除运行时复杂度为O(1)。
代码实现(优化版本)
package com.base.learn.array;import com.base.learn.cache.LFUCache;import java.util.HashMap;
import java.util.LinkedHashSet;
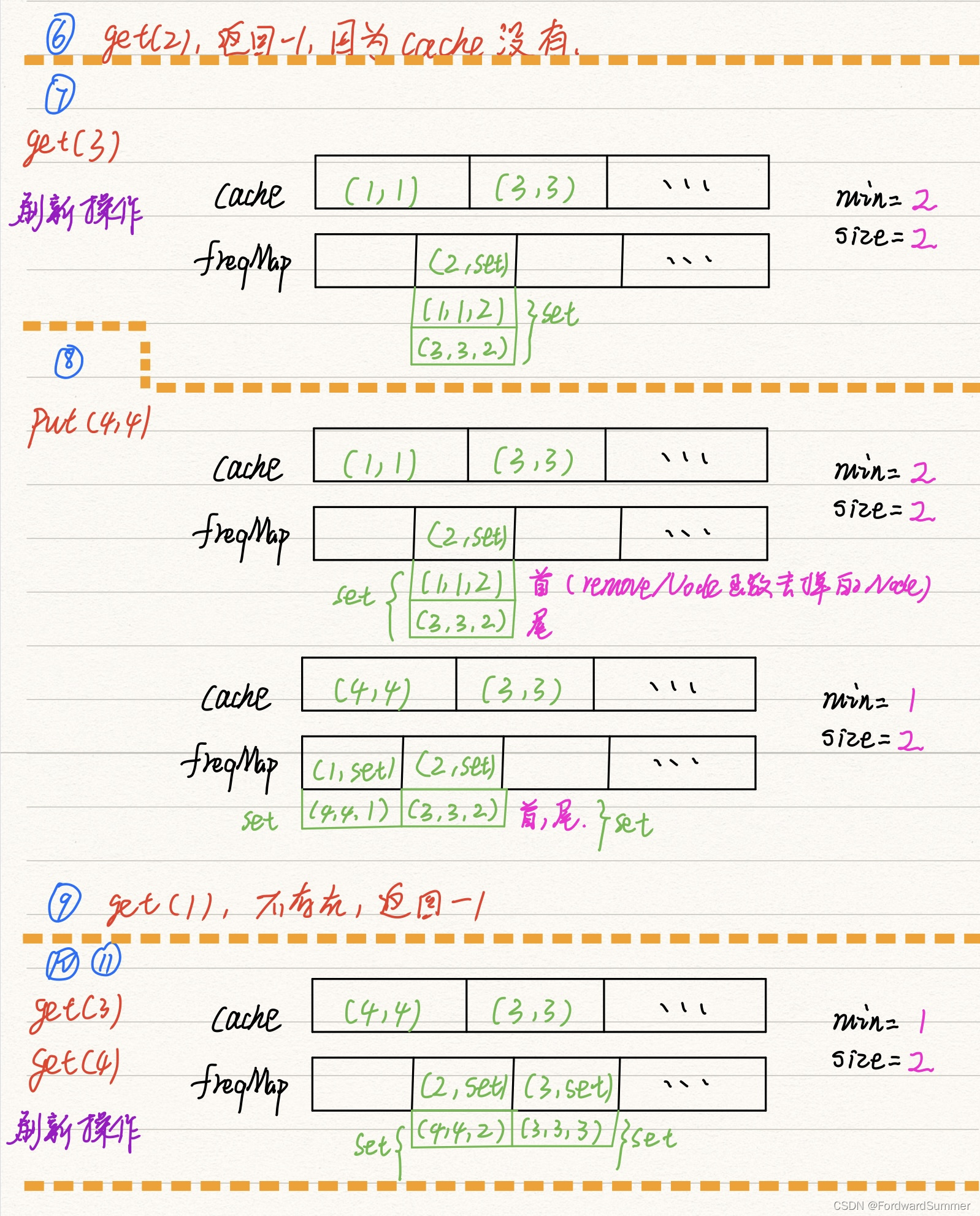
import java.util.Map;class LFUCachePlus {private int capacity; // 容量限制private int size; // 当前数据个数private int minFreq; // 当前最小频率private Map<Integer, Node> cache; // key和数据的映射private Map<Integer, LinkedHashSet<Node>> freqMap; // 数据频率和对应数据组成的链表public LFUCachePlus(int capacity) {this.capacity = capacity;this.size = 0;this.minFreq = 1;this.cache = new HashMap<>();this.freqMap = new HashMap<>();}public int get(int key) {Node node = cache.get(key);if (node == null) {return -1;}// 增加数据的访问频率freqPlus(node);return node.value;}public void put(int key, int value) {if (capacity <= 0) {return;}Node node = cache.get(key);if (node != null) {// 如果存在则增加该数据的访问频次node.value = value;freqPlus(node);} else {// 淘汰数据eliminate();// 新增数据并放到数据频率为1的数据链表中Node newNode = new Node(key, value);cache.put(key, newNode);LinkedHashSet<Node> set = freqMap.get(1);//初始化频率链表if (set == null) {set = new LinkedHashSet<>();freqMap.put(1, set);}set.add(newNode);minFreq = 1;size++;}}private void eliminate() {if (size < capacity) {return;}LinkedHashSet<Node> set = freqMap.get(minFreq);//使用的是LinkedHashSet,有序,因此直接删除头节点//头节点就是最老的数据Node node = set.iterator().next();set.remove(node);cache.remove(node.key);size--;}private void freqPlus(Node node) {int frequency = node.frequency;LinkedHashSet<Node> oldSet = freqMap.get(frequency);//移除当前这个被获取到的节点oldSet.remove(node);// 更新最小数据频率if (minFreq == frequency && oldSet.isEmpty()) {minFreq++;}frequency++;node.frequency++;LinkedHashSet<Node> set = freqMap.get(frequency);if (set == null) {set = new LinkedHashSet<>();freqMap.put(frequency, set);}set.add(node);}
}class Node {int key;int value;int frequency = 1;Node(int key, int value) {this.key = key;this.value = value;}public static void main(String[] args) {LFUCachePlus cache = new LFUCachePlus(2);cache.put(1, 1);cache.put(2, 2);cache.put(3, 3);//空间不足 剔除1 放入3System.out.println(cache.get(3));System.out.println(cache.get(2));//空间不足 此时有3 2 ,访问次数都为1,但是3的访问时间更久之前,剔除3cache.put(4, 4);System.out.println(cache.get(3));System.out.println(cache.get(4));System.out.println(cache.get(2));}
}区别
LFU相比于LRU的优劣
区别:
LFU是基于访问频次的模式,而LRU是基于访问时间的模式。
优势:
在数据访问符合正态分布时,相比于LRU算法,LFU算法的缓存命中率会高一些。
劣势:
LFU的复杂度要比LRU更高一些。
需要维护数据的访问频次,每次访问都需要更新。
早期的数据相比于后期的数据更容易被缓存下来,导致后期的数据很难被缓存。
新加入缓存的数据很容易被剔除,像是缓存的末端发生“抖动”。
LFU算法优化
从上面的优劣分析中我们可以发现,优化LFU算法可以从下面几点入手:
更加紧凑的数据结构,避免维护访问频次的高消耗。
避免早期的热点数据一直占据缓存,即LFU算法也需有一些访问时间模式的特性。
消除缓存末端的抖动。