LFU算法:least frequently used,最近最不经常使用算法
对于每个条目,维护其使用次数 cnt、最近使用时间 time。
cache容量为 n,即最多存储n个条目。
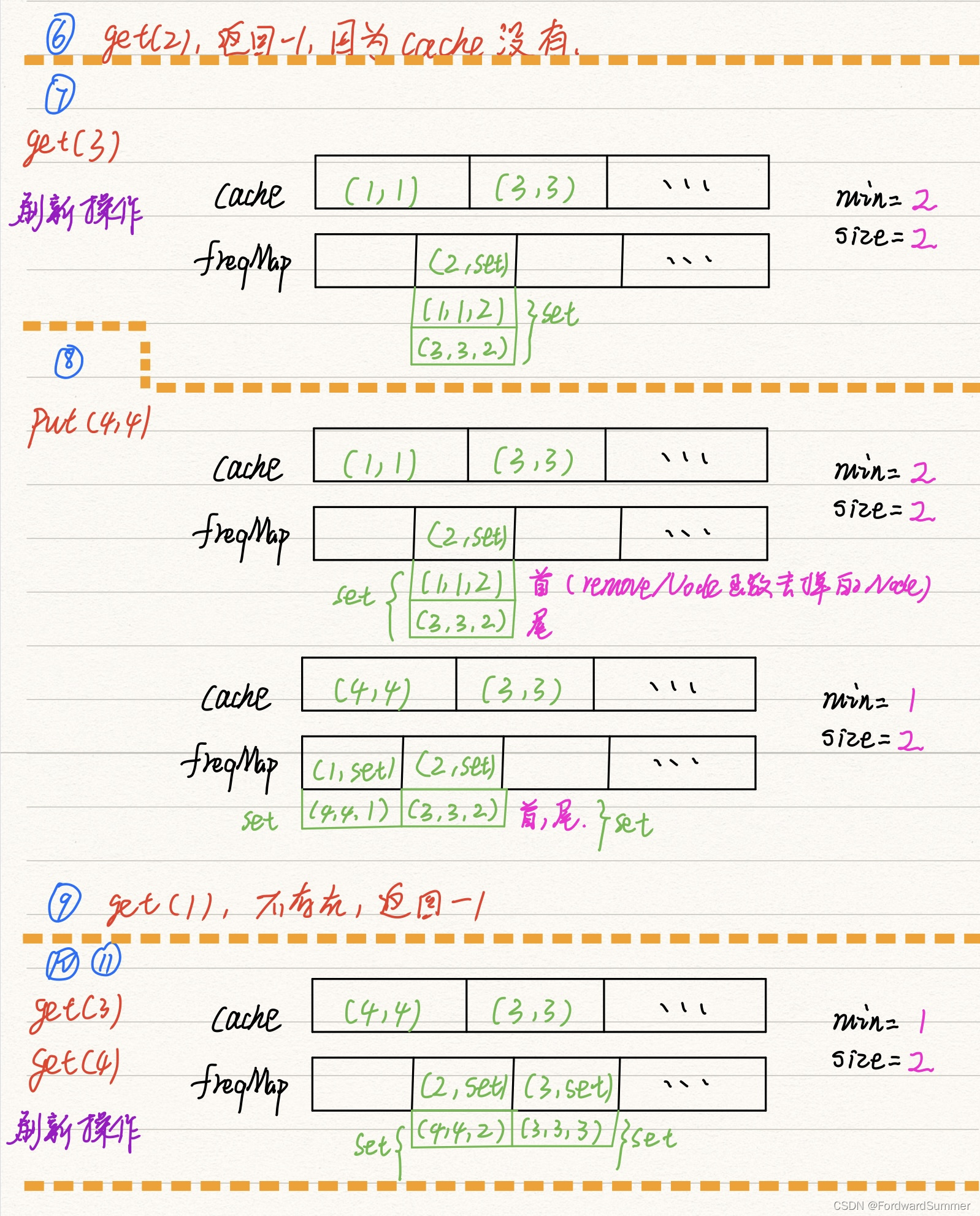
那么当我需要插入新条目并且cache已经满了的时候,需要删除一个之前的条目。删除的策略是:优先删除使用次数cnt最小的那个条目,因为它最近最不经常使用,所以删除它。如果使用次数cnt最小值为min_cnt,这个min_cnt对应的条目有多个,那么在这些条目中删除最近使用时间time最早的那个条目(举个栗子:a资源和b资源都使用了两次,但a资源在5s的时候最后一次使用,b资源在7s的时候最后一次使用,那么删除a,因为b资源更晚被使用,所以b资源相比a资源来说,更有理由继续被使用,即时间局部性原理)。
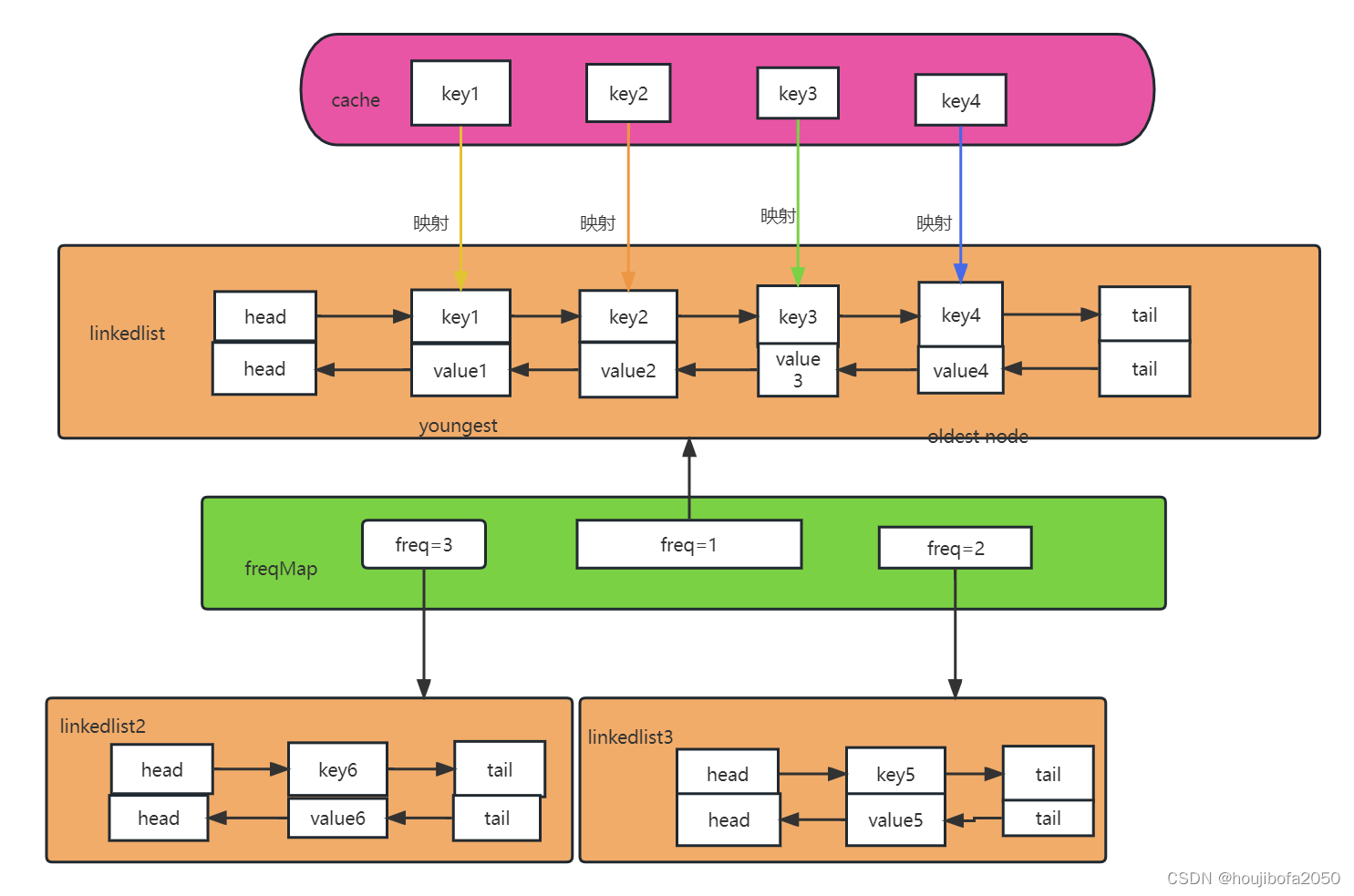
类似lru算法的想法,利用哈希表+链表。
链表是负责按时间先后排序的。哈希表是负责O(1)时间查找key对应节点的。
引用力扣的一张图片
lfu算法是按照两个维度:引用计数、最近使用时间来排序的。所以一个链表肯定不够用了。解决办法就是按照下图这样,使用第二个哈希表,key是引用计数,value是一个链表,存储使用次数为当前key的所有节点。该链表中的所有节点按照最近使用时间排序,最近使用的在链表头部,最晚使用的在尾部。这样我们可以完成O(1)时间查找key对应节点(通过第一个哈希表);O(1)时间删除、更改某节点(通过第二个哈希表)。
注意:get(查询)操作和put(插入)操作都算“使用”,都会增加引用计数。
所以get(key)操作实现思路:如果第一个哈希表中能查到key,那么取得相应链表节点。接下来在第二个哈希表中,把它移到其引用计数+1位置的链表头部,并删除之前的节点。
put(key,value)操作实现思路:如果第一个哈希表中能查找key,那么操作和get(key)一样,只是把新节点的value置为新value。
如果查不到key,那么我们有可能需要删除cache中的某一项(容量已经达到限制):直接找到第二个哈希表中最小引用计数的链表,删除其末尾节点(最晚使用),之后再添加新节点即可。
注意点:
1.容量超限需要删除节点时,删除了第二个哈希表中的项的同时,第一个哈希表中对应的映射也应该删掉。
2.需要保持一个min_cnt整型变量用来保存当前的最小引用计数。因为容量超限需要删除节点时,我们需要O(1)时间找到需要删除的节点。
实现代码:
import java.util.HashMap;
import java.util.Map;public class LFUCache {/*** key 就是题目中的 key* value 是结点类*/private Map<Integer, ListNode> map;/*** 访问次数哈希表,使用 ListNode[] 也可以,不过要占用很多空间*/private Map<Integer, DoubleLinkedList> frequentMap;/*** 外部传入的容量大小*/private Integer capacity;/*** 全局最高访问次数,删除最少使用访问次数的结点时会用到*/private Integer minFrequent = 1;public LFUCache(int capacity) {// 显式设置哈希表的长度 = capacity 和加载因子 = 1 是为了防止哈希表扩容带来的性能消耗// 这一步操作在理论上的可行之处待讨论,实验下来效果是比较好的map = new HashMap<>(capacity, 1);frequentMap = new HashMap<>();this.capacity = capacity;}/*** get 一次操作,访问次数就增加 1;* 从原来的链表调整到访问次数更高的链表的表头** @param key* @return*/public int get(int key) {// 测试测出来的,capacity 可能传 0if (capacity == 0) {return -1;}if (map.containsKey(key)) {// 获得结点类ListNode listNode = removeListNode(key);// 挂接到新的访问次数的双向链表的头部int frequent = listNode.frequent;addListNode2Head(frequent, listNode);return listNode.value;} else {return -1;}}/*** @param key* @param value*/public void put(int key, int value) {if (capacity == 0) {return;}// 如果 key 存在,就更新访问次数 + 1,更新值if (map.containsKey(key)) {ListNode listNode = removeListNode(key);// 更新 valuelistNode.value = value;int frequent = listNode.frequent;addListNode2Head(frequent, listNode);return;}// 如果 key 不存在// 1、如果满了,先删除访问次数最小的的末尾结点,再删除 map 里对应的 keyif (map.size() == capacity) {// 1、从双链表里删除结点DoubleLinkedList doubleLinkedList = frequentMap.get(minFrequent);ListNode removeNode = doubleLinkedList.removeTail();// 2、删除 map 里对应的 keymap.remove(removeNode.key);}// 2、再创建新结点放在访问次数为 1 的双向链表的前面ListNode newListNode = new ListNode(key, value);addListNode2Head(1, newListNode);map.put(key, newListNode);// 【注意】因为这个结点是刚刚创建的,最少访问次数一定为 1this.minFrequent = 1;}// 以下部分主要是结点类和双向链表的操作/*** 结点类,是双向链表的组成部分*/private class ListNode {private int key;private int value;private int frequent = 1;private ListNode pre;private ListNode next;public ListNode() {}public ListNode(int key, int value) {this.key = key;this.value = value;}}/*** 双向链表*/private class DoubleLinkedList {/*** 虚拟头结点,它无前驱结点*/private ListNode dummyHead;/*** 虚拟尾结点,它无后继结点*/private ListNode dummyTail;/*** 当前双向链表的有效结点数*/private int count;public DoubleLinkedList() {// 虚拟头尾结点赋值多少无所谓this.dummyHead = new ListNode(-1, -1);this.dummyTail = new ListNode(-2, -2);dummyHead.next = dummyTail;dummyTail.pre = dummyHead;count = 0;}/*** 把一个结点类添加到双向链表的开头(头部是最新使用数据)** @param addNode*/public void addNode2Head(ListNode addNode) {ListNode oldHead = dummyHead.next;// 两侧结点指向它dummyHead.next = addNode;oldHead.pre = addNode;// 它的前驱和后继指向两侧结点addNode.pre = dummyHead;addNode.next = oldHead;count++;}/*** 把双向链表的末尾结点删除(尾部是最旧的数据,在缓存满的时候淘汰)** @return*/public ListNode removeTail() {ListNode oldTail = dummyTail.pre;ListNode newTail = oldTail.pre;// 两侧结点建立连接newTail.next = dummyTail;dummyTail.pre = newTail;// 它的两个属性切断连接oldTail.pre = null;oldTail.next = null;// 重要:删除一个结点,当前双向链表的结点个数少 1count--;// 维护return oldTail;}}/*** 将原来访问次数的结点,从双向链表里脱离出来** @param key* @return*/private ListNode removeListNode(int key) {// 获得结点类ListNode deleteNode = map.get(key);ListNode preNode = deleteNode.pre;ListNode nextNode = deleteNode.next;// 两侧结点建立连接preNode.next = nextNode;nextNode.pre = preNode;// 删除去原来两侧结点的连接deleteNode.pre = null;deleteNode.next = null;// 维护双链表结点数frequentMap.get(deleteNode.frequent).count--;// 【注意】维护 minFrequent// 如果当前结点正好在最小访问次数的链表上,并且移除以后结点数为 0,最小访问次数需要加 1if (deleteNode.frequent == minFrequent && frequentMap.get(deleteNode.frequent).count == 0) {// 这一步需要仔细想一下,经过测试是正确的minFrequent++;}// 访问次数加 1deleteNode.frequent++;return deleteNode;}/*** 把结点放在对应访问次数的双向链表的头部** @param frequent* @param addNode*/private void addListNode2Head(int frequent, ListNode addNode) {DoubleLinkedList doubleLinkedList;// 如果不存在,就初始化if (frequentMap.containsKey(frequent)) {doubleLinkedList = frequentMap.get(frequent);} else {doubleLinkedList = new DoubleLinkedList();}// 添加到 DoubleLinkedList 的表头doubleLinkedList.addNode2Head(addNode);frequentMap.put(frequent, doubleLinkedList);}public static void main(String[] args) {LFUCache cache = new LFUCache(2);cache.put(1, 1);cache.put(2, 2);System.out.println(cache.map.keySet());int res1 = cache.get(1);System.out.println(res1);cache.put(3, 3);System.out.println(cache.map.keySet());int res2 = cache.get(2);System.out.println(res2);int res3 = cache.get(3);System.out.println(res3);cache.put(4, 4);System.out.println(cache.map.keySet());int res4 = cache.get(1);System.out.println(res4);int res5 = cache.get(3);System.out.println(res5);int res6 = cache.get(4);System.out.println(res6);}
}作者:liweiwei1419
链接:https://leetcode-cn.com/problems/lfu-cache/solution/ha-xi-biao-shuang-xiang-lian-biao-java-by-liweiwei/
来源:力扣(LeetCode)参考链接:LFU算法实现(460. LFU缓存) - NeoZy - 博客园