文章目录
- LRU和LFU算法解析
- LRU
- LRU概念
- LRU算法实现
- LRU算法描述
- LRU算法图示
- LRU C++代码
- 代码测试
- LFU
- LFU概念
- LFU算法实现
- LFU算法描述
- LFU算法图示
- LFU C++代码
- 代码测试
- 总结
LRU和LFU算法解析
LRU
LRU概念
LRU(The Least Recently Used,最近最少未使用)是一种常见内存管理算法,最早应用于Linux操作系统,在Redis中也有广泛使用的。
LRU算法有这样一种假设:如果某个数据长期不被使用,在未来被用到的几率也不大;因此缓存容量达到上限时,应在写入新数据之前删除最久未使用的数据值,从而为新数据腾出空间。
LRU算法实现
LRU算法描述
需要设计一种数据结构,并且提供以下接口:
- 构造函数,确定初始容量大小
get(key):如果关键字key存于缓存中,则获取其对应的值;否则返回-1put(key, val):- 如果关键字key已经存在,则更改其对应的值为
val; - 如果关键字不存在,则插入(key,val)
- 当缓存容量达到上限时,最久没有访问的数据应该被置换。
- 如果关键字key已经存在,则更改其对应的值为
LRU算法图示
我们可以使用双向链表+哈希表来模拟实现LRU算法:
- 哈希表用来快速查找某个key是否存于缓存中
- 链表用来表示使用数据项的时间先后次序
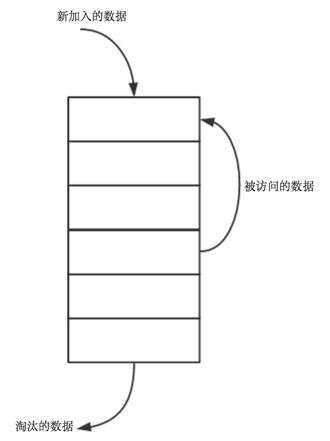
LRU存储图示
当LRU的容量未到达上限时,对某个数据进行访问(包括添加,读取,修改),则只需要在链表头部插入新节点即可。
当LRU的容量到达上限时,需要添加某个数据,则需要移除链表最末端的键值(最久未使用),然后头插新节点。
容量未满,插入新值003
容量上限,插入新值004
访问数据003
LRU C++代码
class LRUCache {
public:// 键值节点struct Node{int key;int val;Node(int k, int v):key(k), val(v){}};using node_iter = list<Node>::iterator;public:LRUCache(int capacity) {this->cap = capacity;}int get(int key) {auto it = mp.find(key);if(it == mp.end()) return -1; // 节点不存在else{int val = it->second->val;l.erase(it->second); // list通过迭代器删除节点l.push_front(Node(key, val)); // 头插最近访问节点mp[key] = l.begin(); // 更新哈希表中 key对应的 list迭代器return val;}}void put(int key, int value) {auto it = mp.find(key);if(it == mp.end()){if(cap == mp.size()){// 容量达到上限且需要添加, 移除最久未使用的mp.erase(l.back().key); l.pop_back(); }else{// 容量达到上限,则可以直接添加}}else{// key存于缓存,需要修改l.erase(it->second);}l.push_front(Node(key, value)); // 头插最近访问节点mp[key] = l.begin(); // 更新哈希表中 key对应的 list迭代器}
private:unordered_map<int, node_iter> mp; // 哈希表list<Node> l; // 双向链表int cap; // 缓存容量上限
};
代码测试
int main() {const int capacity = 3;LRUCache cache(capacity);cache.put(1, 1);cache.put(2, 2);std::cout << cache.get(1) << std::endl; // 返回 1cache.put(3, 3);std::cout << cache.get(2) << std::endl; // 返回 2 cache.put(4, 4); // 该操作会使得关键字 1 作废std::cout << cache.get(1) << std::endl; // 返回 -1 (未找到)std::cout << cache.get(3) << std::endl; // 返回 3std::cout << cache.get(4) << std::endl; // 返回 4
}/*out:1 2 -1 3 4
*/
LFU
LFU概念
LFU(The Least Frequently Used,最不经常使用)也是一种常见的缓存算法。
和LRU类似,LFU同样有这样的假设:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰;当存在两个或者更多个键具有相同的使用频次时,应该淘汰最久未使用的数据。(类比LRU)
LFU算法实现
LFU算法描述
需要设计一种数据结构,并且提供一下接口:
- 构造函数,确定初始缓存容量
get(key):如果键存在于缓存中,则获取键的值,否则返回 -1。put(key, value)- 如果键已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量时,则应该在插入新项之前,移除最不经常使用的项。当存在两个或者更多个键具有相同的使用频次时,应该移除最久未使用的键。
LFU算法图示
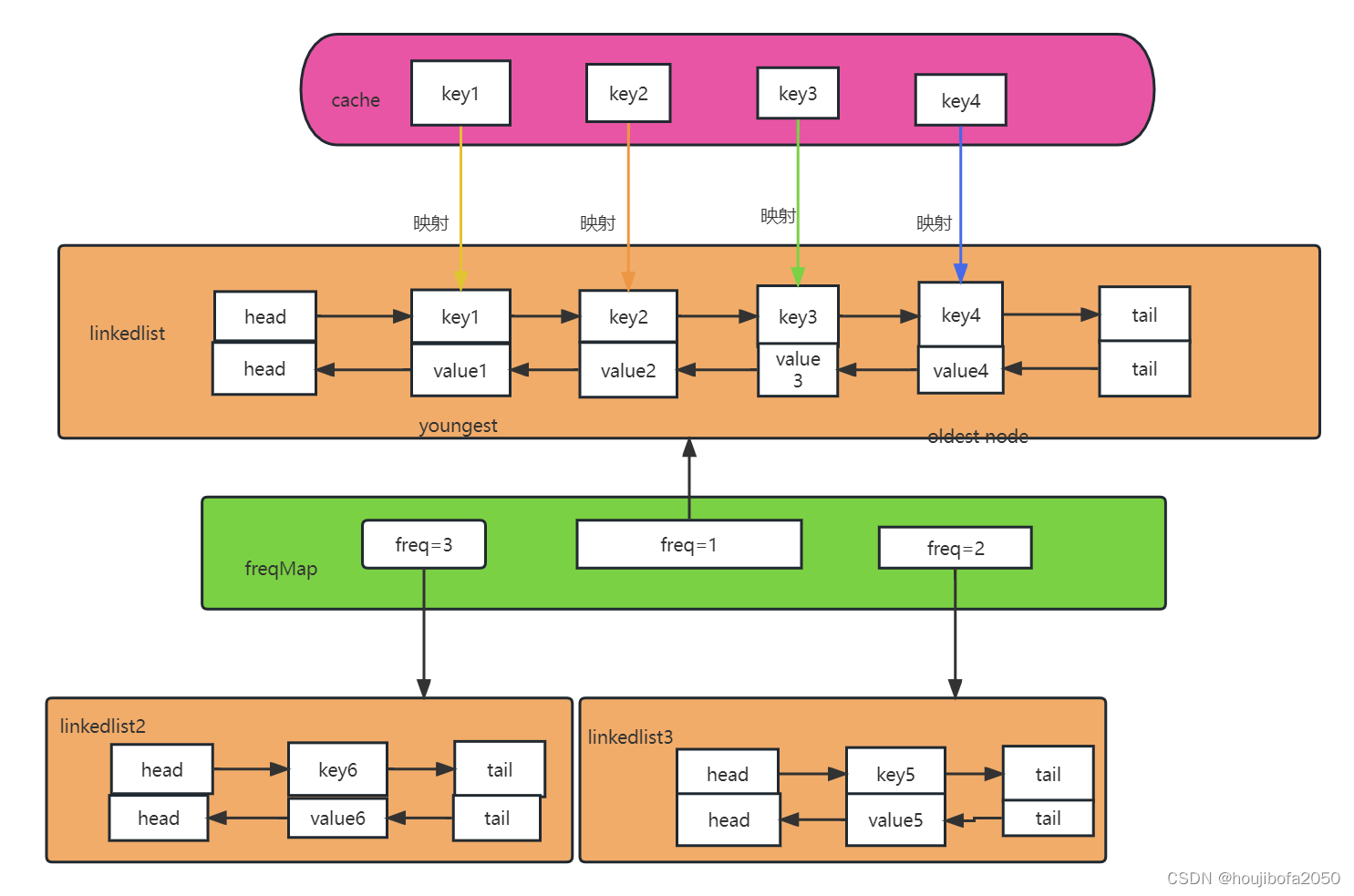
我们可以使用双哈希表 + 双链表来模拟实现LFU算法:
key_table:用来快速查找某个key是否存于缓存中freq_table:以使用频次为键,存储相同使用频次的节点
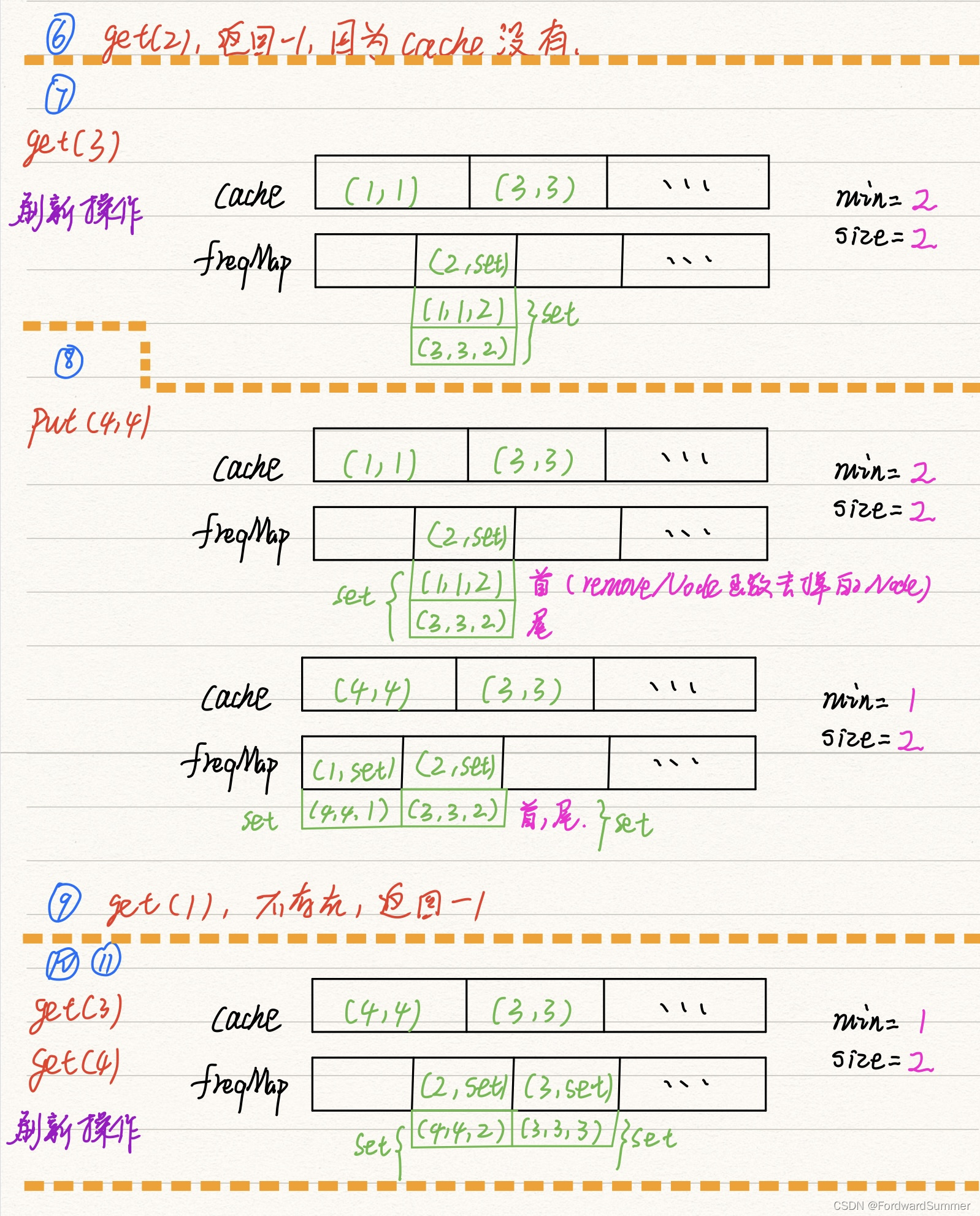
LFU存储图示
当LFU的容量未到达上限时,对某个数据进行访问(包括添加,读取,修改),其使用频次加一,则只需要在对应链表头部插入新节点即可。
当LFU的容量到达上限时,需要添加某个数据,则需要移除当前使用频次最低的链表最末端的键值(最久未使用),然后在频次为1的链表头插新节点。
容量未满,插入新值005
访问数据001
容量上限,插入新值006
LFU C++代码
class LFUCache {
public:// 键值节点struct Node {int key, val, freq;Node(int _key,int _val,int _freq): key(_key), val(_val), freq(_freq){}};public:LFUCache(int capacity) {this->cap = capacity;min_freq = 0;}int get(int key) {if(!cap) return -1;auto it = key_table.find(key); // 节点不存在if(it == key_table.end()){ return -1;}else{auto key_iter = it->second;Node* node = *key_iter;int val = node->val, freq = node->freq;freq_table[freq].erase(key_iter);// 如果 freq 对应的链表为空,则移除if(freq_table[freq].size() == 0){ freq_table.erase(freq);// 更新最小使用频次,为当前节点使用频次 ferq + 1if(min_freq == freq) min_freq = freq + 1;}node->freq += 1;// freq + 1 频次对应链表进行头插freq_table[freq + 1].push_front(node);// 更新 key 对应的list迭代器key_table[key] = freq_table[freq + 1].begin();return val;}}void put(int key, int value) {if(!cap) return;auto it = key_table.find(key);if(it != key_table.end()){// key 存于缓存中auto key_iter = it->second;auto node = *key_iter;int freq = node->freq;freq_table[freq].erase(key_iter);if(freq_table[freq].size() == 0){freq_table.erase(freq);// 更新 min_freqif(min_freq == freq)min_freq = freq + 1;}// 修改值, 更新freqnode->freq += 1; node->val = value;// freq + 1 频次链表进行头插freq_table[freq + 1].push_front(node);// 更新 key 对应的list迭代器key_table[key] = freq_table[freq + 1].begin();}else{// 容量达到上限if(key_table.size() == cap){// 获取使用频次最小且最久未使用的节点Node* del_node = freq_table[min_freq].back();freq_table[min_freq].pop_back();if(freq_table[min_freq].size() == 0){freq_table.erase(min_freq);}key_table.erase(del_node->key);delete del_node;}// 头插新节点freq_table[1].push_front(new Node(key, value, 1));key_table[key] = freq_table[1].begin();// 当前最小使用频次为1min_freq = 1;}}
private:// 缓存上限int cap;// 当前最低使用频次int min_freq;// 根据key建立哈希表unordered_map<int, list<Node*>::iterator> key_table;// 按照使用频次建立哈希表unordered_map<int, list<Node*>> freq_table;
};
代码测试
int main(){const int capacity = 2;LFUCache cache(capacity);cache.put(1, 1);cache.put(2, 2);std::cout << cache.get(1) << std::endl; // 返回 1cache.put(3, 3); // 此操作会使关键字 2 作废std::cout << cache.get(2) << std::endl; // 返回 -1 (未找到key 2)std::cout << cache.get(3) << std::endl; // 返回 3cache.put(4, 4); // 此操作会使关键字 1 作废std::cout << cache.get(1) << std::endl; // 返回 -1 (未找到 key 1)std::cout << cache.get(3) << std::endl; // 返回 3std::cout << cache.get(4) << std::endl; // 返回 4
}
/*out:1 -1 3 -1 3 4
*/
总结
LRU和LFU的算法暂时就介绍到这里了,作者水平有限,可能会存在疏漏之处,欢迎指正。
关于其他的缓存算法,例如FIFO,ARC,MRU等,我们会在后续的文章继续探讨。
谢谢~