上篇文章是讲了WebDriver定位元素的方法,这篇文章就要讲操作了,本文内容篇幅可能会比较长,一个是因为要操作的项目比较多,另一个是我会将完整的代码放进来,总体原则上我还是追求尽量细致一些,以便能方便读者理解。
控制浏览器
WebDriver主要提供了操作页面上各种元素的方法,同时它还提供了操作浏览器的一些方法,如控制浏览器的大小,操作浏览器前进或后退等。
1.控制浏览器窗口大小
如下图,通常自动化操作谷歌页面时,默认打开的页面不是全屏,这个时候,如果你觉得屏幕分辨率不够,或者太大,你可以通过两个方法来控制浏览器窗口的大小
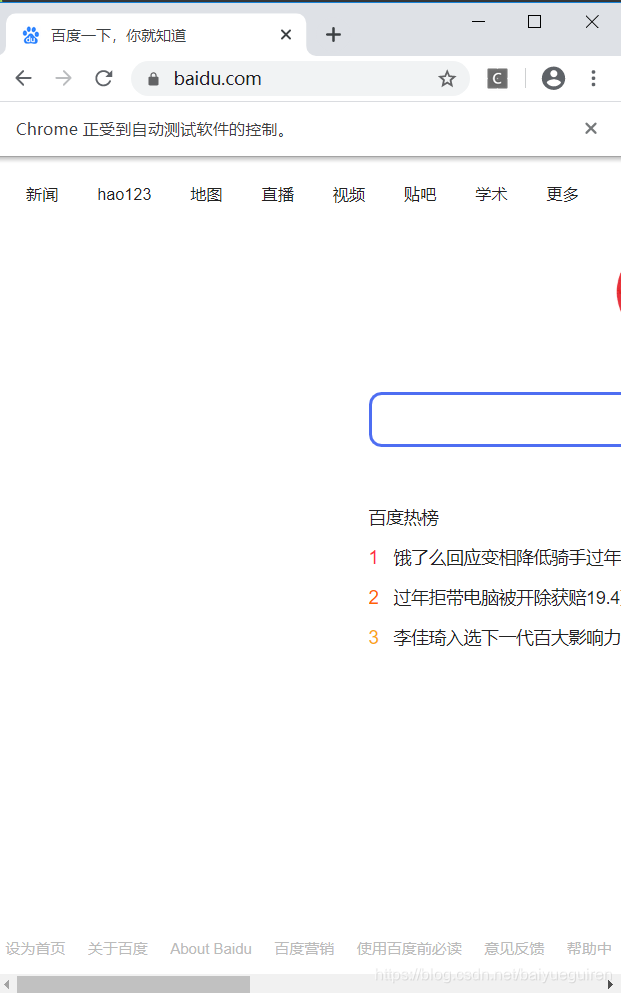
第一个方法是:set_window_size(),可以设置浏览器窗口的大小,下图是效果
from selenium import webdriver
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")print("设置浏览器宽480、高800显示") # 这里设置的数字是分辨率(像素)
driver.set_window_size(480, 800)
time.sleep(1)
dirver.quit()
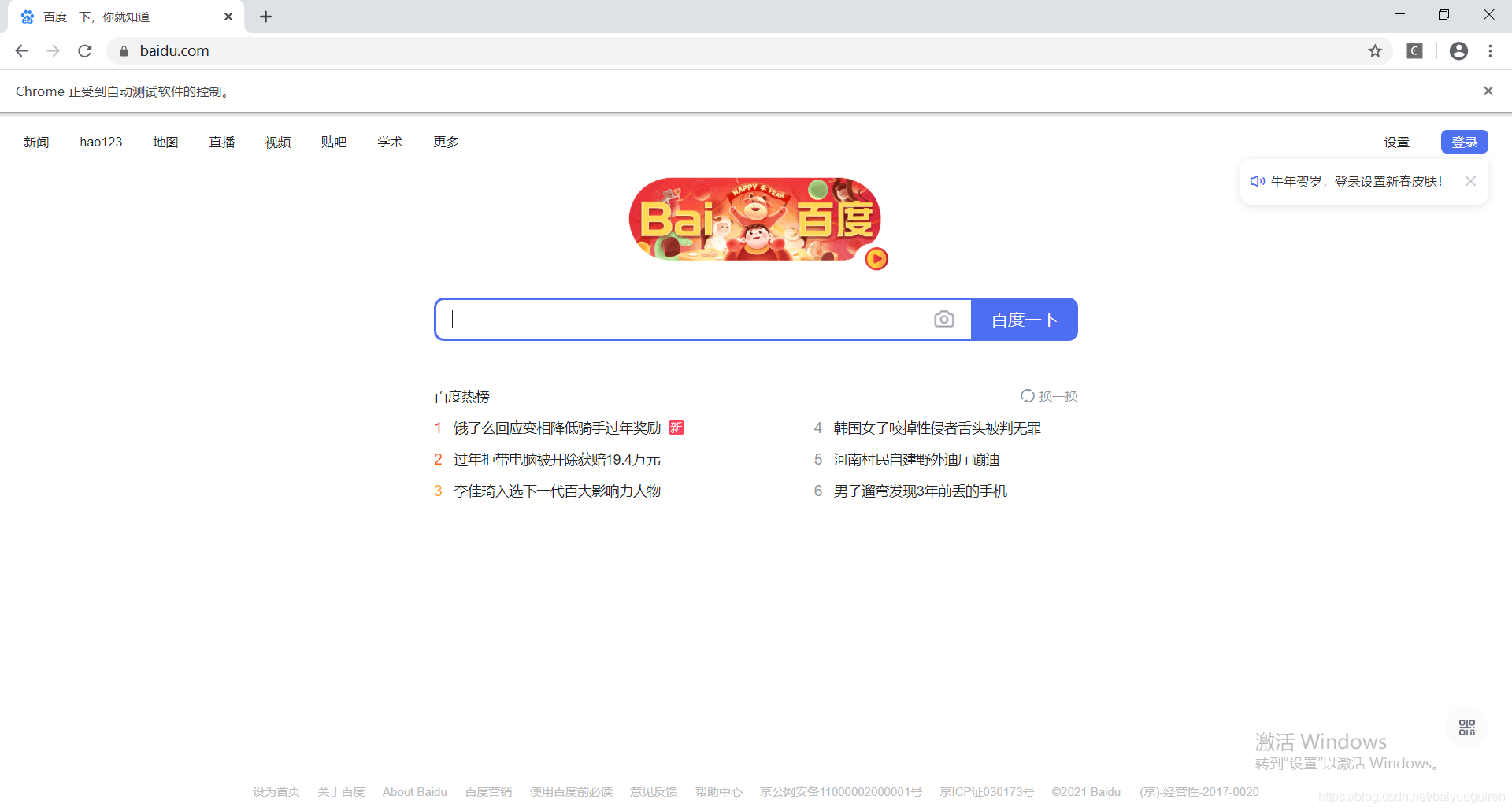
第二个方法是:maximize_window(),可以将浏览器的窗口设为全屏,下图是效果
from selenium import webdriver
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")print("浏览器最大化")
driver.maximize_window() # 将浏览器最大化显示
time.sleep(1)
driver.quit()
2.控制浏览器后退、前进
在使用Web浏览器浏览网页时,浏览器提供了后退和前进按钮,可以方便地在浏览过的网页之间进行切换,主要是通过Webdriver提供的back()和forward()方法来模拟后退和前进按钮
from selenium import webdriver
import timedriver = webdriver.Chrome()
# 访问百度首页
first_url = "http://www.baidu.com"
print("now access %s" % (first_url))
driver.get(first_url)# 访问新闻页面
second_url = "http://news.baidu.com"
print("now access %s" % (second_url))
driver.get(second_url)# 返回到百度首页
print("back to %s" % (first_url))
driver.back()# 前进到新闻页
print("forward to %s" % (second_url))
driver.forward()driver.quit()模拟浏览器刷新
有时候需要手动刷新(F5)Web页面,可以通过refresh()方法实现,driver.refresh(),这个比较简单就不写代码了
Webdriver中的常用方法
1.clear():清除文本
2.send_keys() :模拟按键输入
3.click():单击元素
这三个方法可以在一个代码案例中进行说明
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium库的基本使用") #在百度输入框中输入内容
time.sleep(3)
driver.find_element_by_id("kw").clear() # 清除百度输入框中的文本
time.sleep(3)
driver.find_element_by_id("kw").send_keys("selenium库的基本使用") #在百度输入框中输入内容
time.sleep(3)
driver.find_element_by_id("su").click() #点击"百度一下"
time.sleep(3)
driver.quit()
4.submit:提交表单
有时候在输入框内输入了内容,但是却没有搜索按钮,而是通过按键盘上的回车键(Enter)完成搜索内容的提交,现在还可以通过submit()模拟提交,其实submit()作用和click()大体是一样的,只是因为有时候没有搜索按钮才用submit(),click()作用范围远大于submit(),它可以单击任何可以单击的元素,例如,按钮,复选框(有好几个框可以选),单选框,下拉文字链接和图片链接等,而这些submit()确实做不到
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium库的基本使用") #在百度输入框中输入内容
time.sleep(3)
driver.find_element_by_id("su").submit() #点击"百度一下"
time.sleep(3)
driver.quit()
5.size:返回元素的尺寸
6.text:获取元素的文本
7.get_attribute():获得属性值
8.is_displayed():设置该元素是否用户可见
这四个方法放在一个代码案例中展现,size()方法用于获取百度输入框的宽和高,text()方法用于获得百度底部的备案信息,get_attribute()方法用于获得百度输入框属性的值,is_displayed()方法用于返回一个元素是否可见,如果可见,返回True,否则返回False
# 返回元素的尺寸
# 如:返回百度输入框的宽高
from selenium import webdriver
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
size = driver.find_element_by_id("kw").size
print(size)# 获取元素的文本
# 如:返回百度页面底部备案信息
text = driver.find_element_by_class_name("s-bottom-layer-content").text
print(text)# 获得属性值
# 返回元素的属性值,可以是id,name,type或元素拥有的其他任意属性
attribute = driver.find_element_by_id("kw").get_attribute('name')
print(attribute)# 设置该元素是否用户可见
# 返回元素的结果是否可见,返回结果为true或false
result = driver.find_element_by_id('kw').is_displayed()
print(result)driver.quit()结果:
{'height': 44, 'width': 548}
设为首页关于百度About Baidu百度营销使用百度前必读意见反馈帮助中心京公网安备11000002000001号京ICP证030173号©2021 Baidu (京)-经营性-2017-0020
wd
True
鼠标操作
在Webdriver中,与鼠标操作相关的方法都封装在ActionChains类中
方法:
perform():执行ActionChains类中存储的所有行为
context_click():右击
double_click():双击
drag_and_drop():拖动
move_to_element():鼠标悬停
click_and_hold() 按下鼠标左键在一个元素上
# 1.鼠标右击操作 context_click() 右键点击一个元素
# 引入ActionChains类:用于生成用户的行为
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time# 定位到要右击的元素
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
right = driver.find_element_by_xpath('//*[@id="kw"]')
# # 对定位到的元素执行鼠标右键操作
ActionChains(driver).context_click(right).perform()
driver.quit()
对应的图片:

# 2.鼠标双击操作 double_click(on_element) 双点击页面元素
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import timedriver = webdriver.Chrome()
driver.get("https://map.baidu.com/search/%E5%85%A8%E5%9B%BD/@12959219.600001993,4825334.630014527,7z?querytype=s&wd=%E5%85%A8%E5%9B%BD&c=1&provider=pc-aladin&pn=0&device_ratio=2&da_src=shareurl")
driver.maximize_window()
# 定位到要双击的元素
# 对于操作系统的操作来说,双击使用非常频繁,但对于web应用来说双击的用户比较少,可能的场景有地图程序(如百度地图)可以通过双击鼠标放大地图
double = driver.find_element_by_xpath('//*[@id="mask"]')
# # 对定位到的元素执行鼠标双击操作
ActionChains(driver).double_click(double).perform() # 第一次双击
time.sleep(4)
ActionChains(driver).double_click(double).perform() # 第二次双击
driver.quit()
未双击的效果:

双击一次的效果:

双击两次的效果:

# 3.鼠标拖放操作 drag_and_drop(source, target)
# 在源元素上按下鼠标左键,然后移动到目标元素上释放
# source 鼠标按下的源元素 target 鼠标释放的目标元素
from selenium import webdriver
from selenium.webdriver import ActionChains
import timedriver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.maximize_window()
driver.switch_to.frame('iframeResult')
# 定位元素的原位置
source = driver.find_element_by_css_selector('#draggable')
# 定位元素要移动到的目标位置
target = driver.find_element_by_css_selector('#droppable')
time.sleep(3)
# 执行元素的移动操作
ActionChains(driver).drag_and_drop(source, target).perform()
鼠标未拖曳效果图:

鼠标拖曳之后的效果图:

# 4.鼠标移动到元素上 move_to_element()
# 模拟鼠标移动到一个元素上
from selenium import webdriver
from selenium.webdriver import ActionChains
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.maximize_window()
# 定位到鼠标移动到的目标元素
above = driver.find_element_by_xpath('//*[@id="s-usersetting-top"]') # 先定位到设置
above.click() # 点击设置
time.sleep(5)
abanon = driver.find_element_by_xpath('//*[@id="s-user-setting-menu"]/div/a[4]') # 定位到隐私设置
# 对定位到的元素执行鼠标移动到上面的操作
ActionChains(driver).move_to_element(abanon).perform()
driver.quit()
效果图:

# 5.按下鼠标左键 click_and_hold()
# 按住鼠标左键在第一个元素
# 定位到鼠标按下左键的元素
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.maximize_window()
left = driver.find_element_by_xpath('//*[@id="hotsearch-content-wrapper"]/li[2]/a/span[2]')
ActionChains(driver).click_and_hold(left).perform()
driver.quit()
效果图:

键盘操作
# 我们在实际的测试工作中,有时候我们在测试时需使用tab键将焦点转移到下一个元素用于验证元素的排列是否正确。webdriver的Keys()类提供键盘
# 上所有按键的操作,甚至可以模拟一些组合建的操作,如Ctrl + A,Ctrl+C, Ctrl+ V等,在某些更复杂的情况下,还会出现使用send_keys来模拟上
# 下键来操作下拉列表的情况
# 其他的一些键盘操作对应的方法:send_keys(Keys.TAB):制表键 send_keys(Keys.ESCAPE):回退键 send_keys(Keys.F1):键盘F1
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys# 输入框输入内容
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(2)# 删除多输入的一个m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
time.sleep(2)
# 输入空格键 + "教程"
driver.find_element_by_id("kw").send_keys(Keys.SPACE)
driver.find_element_by_id("kw").send_keys(u"教程")
time.sleep(2)# ctrl+ a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'a')
time.sleep(2)# ctrl+ x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'x')
time.sleep(2)# ctrl+ v 粘贴输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'v')
time.sleep(2)# 通过回车键盘来代替点击操作
driver.find_element_by_id("su").send_keys(Keys.ENTER)
time.sleep(2)driver.quit()
获得验证信息
在进行Web自动化测试中,用的最多的几种验证信息是title、current_url和text
title:用于获取当前页面的标题
current_url:用于获取当前页面的URL
text:用于获取当前页面的文本信息
以百度搜索为例,对比搜索前后的信息
from time import sleep,ctime
from selenium import webdriver
from selenium.webdriver import ActionChains# 1.访问网址
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window() # 窗口最大化
print("before search====")
sleep(3)# 打印当前页面title
title = driver.title
print("title:" + title)# 打印当前页面的URL
now_url = driver.current_url
print("now_url:" + now_url)driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()print("After search======")# 再次打印当前页面title
title = driver.title
print("title:" + title)# 再次打印当前页面的URL
now_url = driver.current_url
print("now_url:" + now_url)
sleep(3) # 这个地方必不可少,没有的话,下面会一直报错,让你怀疑人生!# 获取搜索结果条数
num = driver.find_element_by_class_name("nums.new_nums").text
print("result:" + num)
print(ctime())
driver.quit()结果:
before search====
title:百度一下,你就知道
now_url:https://www.baidu.com/
After search======
title:百度一下,你就知道
now_url:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=selenium&fenlei=256&rsv_pq=c9604d7600012dad&rsv_t=a1a7IzPU19T2BsJN5104VTSfQ0rx8SvThuhqMAcW8FafjYzUFcsHSmxI8TY&rqlang=cn&rsv_enter=0&rsv_dl=tb&rsv_sug3=8&rsv_btype=i&inputT=136&rsv_sug4=136
result:搜索工具
百度为您找到相关结果约53,700,000个
Thu Feb 25 15:24:41 2021Process finished with exit code 0设置元素等待
WebDriver提供了两种类型的元素等待:显示等待和隐式等待
显示等待是WebDriver等待某个条件成立则继续执行,否则在达到最大时长时抛出超时异常(TimeoutException)
# Webdriver提供了两种类型的元素等待:显示等待和隐式等待
# 显示等待是Webdriver等待某个条件则继续执行,否则在达到最大时长时间时抛出超时异常(TimeoutException)from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
driver.get("http://www.baidu.com")# 显示等待
element = WebDriverWait(driver, 5, 0.5).until(EC.visibility_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
driver.quit()
# WebDriverWait类是WebDriver提供的等待方法,在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间仍检测不到,则抛出异常
# 格式:WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exception=None)
# driver:浏览器驱动
# timeout:最大超长时间
# poll_frequency:检测的间隔时间(步长),默认为0.5s
# ignored_exceptions:超时后的异常信息,默认情况下抛出NoSuchElementException异常
# WebDriverWait()一般与until()或者until_not()方法配合使用
# until(method,message="):调用该方法提供的驱动程序作为一个参数,直到返回值为True
# until_not(method,message="):调用该方法提供的驱动程序作为一个参数,直到返回值为False
# visibility_of_element_located是expected_conditions类下的一个判断元素是否存在的方法,expected_conditions类还有很多其他丰富的预期条件判断方法等# 隐式等待
# WebDriver提供的implicitly_wait()方法可以用来实现隐式等待,用法相对来说要简单的多
from time import ctime
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementExceptiondriver = webdriver.Chrome()
# 设置隐式等待为10s
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")try:print(ctime())driver.find_element_by_id("kw22").send_keys('selenium')
except NoSuchElementException as e:print(e)
finally:print(ctime())driver.quit()
# implicitly_wait()的参数是时间,单位为秒,本例中设置的等待时间为10s,首先这个10s并非一个固定的等待时间,它并不影响脚本的执行速度,其次
# 它会等待页面上的所有元素,当脚本执行到某个元素定位时,如果元素存在,则继续执行,如果定位不到元素,则它将以轮询的方式不断地判断元素是否存在
# 假如在第六秒定位到了元素,则继续执行,若直到超出设置时间(10s)还没有定位到元素,则抛出异常定位一组元素
from time import sleep
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.baidu.com")driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
sleep(2)# 定位一组元素
texts = driver.find_elements_by_xpath("//div[@tpl='se_com_default']/h3/a")
# 计算匹配结果个数
print(len(texts))# 循环遍历出每一条搜索结果的标题
for t in texts:print(t.text)driver.quit()
结果:
7
Selenium automates browsers. That's it!
selenium中文网 | selenium安装、selenium使用、selenium...
Python+Selenium详解(超全)
selenium库的基本使用 - 简书
Selenium环境安装配置 - 环境配置 - 测试人社区
Python Selenium库的使用_凯耐的博客-CSDN博客_selenium
Selenium 简介 - 灵笑若然 - 博客园Process finished with exit code 0多表单切换
# 在Web应用中经常会遇到frame/iframe表单嵌套网页的应用,Webdriver只能在一个页面上对元素进行识别和定位,无法直接定位frame/iframe
# 表单内嵌页面的元素,这时需要通过switch_to.frame()方法将当前的定位主体切换为frame/iframe表单的内嵌页面
# 通俗点就是说,A页面里面有一个B页面,现在要定位到B页面里的元素,直接定位是不行的,要先从A页面到B页面,然后才能定位到B页面里的元素from time import sleep
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.126.com")
driver.maximize_window()
sleep(3)login_frame = driver.find_element_by_css_selector('iframe[id^="x-URS-iframe"]') # id后半部分的数字一直在变化,所以匹配所有以x-URS-iframe开头的id
driver.switch_to.frame(login_frame)
driver.find_element_by_name('email').send_keys('xxxxxxxx')
driver.find_element_by_name('password').send_keys('xxxxx')
driver.find_element_by_name('un-login').click()
driver.find_element_by_id('dologin').click()
driver.switch_to.default_content() # 回到最外层的页面sleep(3)
driver.find_element_by_xpath('//*[@id="_mail_component_213_213"]/div[1]/b[3]').click()driver.quit()
# switch_to.frame()默认可以直接对表单的id属性或name属性传参,因而可以定位元素的对象,在这个例子中表单的id属性后半部分的数字是随机变化
# 的,在CSS定位方法中,可以通过"^="匹配id属性为以"x_URS-iframe"开头的元素,最后通过switch_to.default_content()回到最外层的页面
多窗口切换
# 在页面操作过程中,有时候单击某个链接会弹出新的窗口,这时就需要切换到新打开的窗口中进行操作,Webdriver提供的switch_to.window()
# 方法可以实现在不同的窗口间切换
# current_window_handle:获得当前窗口句柄
# window_handles:返回所有窗口的句柄到当前会话
# switch_to.window():切换到相应的窗口
# close():用于关闭当前窗口,quit()用于退出驱动程序并关闭所有相关窗口import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")# 获得百度搜索窗口句柄
search_windows = driver.current_window_handle
driver.find_element_by_link_text('登录').click()
driver.find_element_by_link_text("立即注册").click()# 获得当前所有打开的窗口句柄
all_handles = driver.window_handles# 进入注册窗口
for handle in all_handles:if handle != search_windows:driver.switch_to.window(handle)print(driver.title)driver.find_element_by_name("userName").send_keys('username')driver.find_element_by_name('phone').send_keys('1221')time.sleep(2)# 关闭当前窗口driver.close()
# 回到搜索窗口
driver.switch_to.window(search_windows)
print(driver.title)driver.quit()
# 脚本的执行过程:首先打开百度首页,通过current_window_handle获得当前窗口句柄,并赋值给变量search_handle,接着打开登录弹窗,在登录弹窗
# 上单击“立即注册”链接,从而打开新的注册窗口,通过window_handles获得当前所有窗口句柄(包含百度首页和账号注册页),并赋值给变量all_handles
# 循环遍历all_handles,如果handle不等于search_handle,那么一定是注册窗口,因为在脚本执行过程中,只打开了两个窗口,然后,通过switch_to.window()
# 切换到账号注册页警告框处理
# webdriver 中处理 JavaScript所生成的alert,confirm,prompt是很简单的,具体思路是使用switch_to.alert方法定位到alert,confirm,
# prompt然后使用text、accept、dismiss、send_keys按需进行操作
# text:返回alert,confirm,prompt中的文字信息
# accept:点击确认按钮
# dismiss:点击取消按钮,如果有的话
# send_keys:输入值,这个alert,confirm,prompt没有对话框就不能用了,不然就会报错
# ctrl + shift + c :如果那个地方不好定位出来,就用这个组合键,就可以将它定住定位了,先打开页面,再ctrl + shift + c定住(很重要)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import timedriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.maximize_window()
driver.find_element_by_xpath('//*[@id="s-usersetting-top"]').click()
time.sleep(3)
# 点击打开搜索设置
driver.find_element_by_xpath('//*[@id="s-user-setting-menu"]/div/a[1]').click()
time.sleep(3)
# 点击保存设置
driver.find_element_by_xpath('//*[@id="se-setting-7"]/a[2]').click()
time.sleep(3)
# 获取网页上的警告信息
# WebDriverWait(driver,10,1).until(EC.alert_is_present())
alert = driver.switch_to.alert # 这个地方不能定位就只能通过这个方法到那个界面,然后点击accept就可以了
# 打印文本信息
print(alert.text)
# 接受警告信息
alert.accept()
time.sleep(4)
driver.quit()
# 取消对话框(如果有的话)
# alert = driver.switch_to.alert
# alert.dismiss()
# # 输入值(如果有的话)
# alert = driver.switch_to.alert
# alert.send_keys('我爱编程')下拉框处理
# 下拉框是Web页面常见功能之一,WebDriver提供了Select类来处理下拉框
# Select类:用于定位<select>标签
# select_by_value():通过value值定位下拉选项
# select_by_visible_text():通过text值定位下拉选项
# select_by_index():根据下拉选项框的索引进行选择,第一个选项为0,第二个选项为1
# **以上仅做参考,因为下面我没有用到这些内容**
# 百度页面好像没有看到搜索框设置的下拉框(点击搜索设置之后),所以我还是采用之前的方式去定位,将搜索显示条数改成20条
from time import sleep
from selenium import webdriver
from selenium.webdriver.support.select import Selectdriver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()# 打开搜索设置
driver.find_element_by_xpath('//*[@id="s-usersetting-top"]').click()
sleep(5)
driver.find_element_by_xpath('//*[@id="s-user-setting-menu"]/div/a[1]').click()
sleep(3)driver.find_element_by_xpath('//*[@id="nr_2"]').click()
# # 搜索结果显示条数
# sel = driver.find_element_by_xpath("//select[@id='nr']")
# # value="20"
#
# Select(sel).select_by_value('20')
# sleep(5)
#
# # <option>每页显示50条</option>
# Select(sel).select_by_visible_text("每页显示50条")
# sleep(5)
#
# # 根据下拉选项的索引进行选择
# Select(sel).select_by_index(0)
# sleep(2)
#
driver.quit()
后续待补充!!!