- 基本概念
- 代码
基本概念
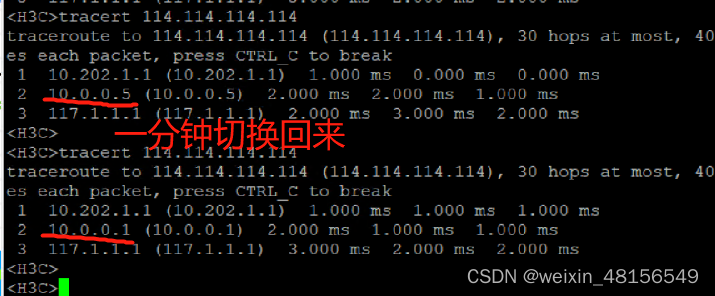
受限玻尔兹曼机(RBM)是一个两层神经网络,第一层被称为可见层,第二层被称为隐藏层,因为网络只有两层,所以又被称为浅层神经网络。
该模型最早由 Paul Smolensky 于 1986 年提出(他称其为 Harmony 网络),此后 Geoffrey Hinton 在 2006 年提出了对比散度(Contrastive Divergence,CD)方法对 RBM 进行训练。可见层中的每个神经元与隐藏层中的所有神经元都相连接,但是同一层的神经元之间无连接,所有的神经元输出状态只有两种。
RBM 可以用于降维、特征提取和协同过滤,RBM 的训练可以分成三部分:正向传播、反向传播和比较。下面看看 RBM 的表达式。
正向传播:可见层(V)已知,利用权重(W)和偏置(c)采样出隐藏层(h0),根据下式的随机概率(σ 是随机概率),隐藏单元开启或关闭:

反向传播:反过来,隐藏层h0已知,通过相同的权重 W 采样出可见层,但是偏置 c 不同,以此重建输入。采样概率为:

这两个传递过程重复 k 步或直到收敛,研究表明,k=1 就已经能给出很好的结果,所以此处设置 k=1。
RBM 模型是一个基于能量的模型,对于一组给定的状态(可见向量 V 和隐藏向量)可构造能量函数:

与每个可见向量 V 相关联的是自由能量,一个单独配置的能量,要想与其他含有 V 的配置的能量相等,则:

使用对比发散度目标函数,即 Mean(F(Voriginal))-Mean(F(Vconstructed)),则权重的变化由下式给出:

其中,η 是学习率,偏置 b 和 c 也存在类似表达式。
代码
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as pltclass RBM(object):def __init__(self,m,n):''':param m:Number of neurons in visible layer:param n:Number of neurons in hidden layer'''self._m = mself._n = n# Create the Computational graph# Weights and biasesself._W = tf.Variable(tf.random_normal(shape=(self._m,self._n)))self._c = tf.Variable(np.zeros(self._n).astype(np.float32))# bias for hidden layerself._b = tf.Variable(np.zeros(self._m).astype(np.float32))# bias for visible layer# placeholder for inputsself._X = tf.placeholder('float',[None,self._m])# forward pass_h = tf.nn.sigmoid(tf.matmul(self._X,self._W)+self._c)self.h = tf.nn.relu(tf.sign(_h - tf.random_uniform(tf.shape(_h))))# backward pass_v = tf.nn.sigmoid(tf.matmul(self.h,tf.transpose(self._W))+self._b)self.V = tf.nn.relu(tf.sign(_v - tf.random_uniform(tf.shape(_v))))# objective functionobjective = tf.reduce_mean(self.free_energy(self._X)) - tf.reduce_mean(self.free_energy(self.V))self._train_op = tf.train.GradientDescentOptimizer(1e-3).minimize(objective)# cross entropy costreconstructed_input = self.one_pass(self._X)self.cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=self._X,logits=reconstructed_input))def fit(self,X,epochs=1,batch_size=100):N,D = X.shapenum_batches = N // batch_sizeobj = []for i in range(epochs):# X = shuffle(x)for j in range(num_batches):batch = X[j*batch_size:(j*batch_size+batch_size)]_,ob = self.session.run([self._train_op,self.cost],feed_dict={self._X:batch})if j % 10 ==0:print('training epoch {0} cost {1}'.format(j,ob))obj.append(ob)return objdef set_session(self,session):self.session = sessiondef free_energy(self,V):b = tf.reshape(self._b,(self._m,1))term_1 = -tf.matmul(V,b)term_1 = tf.reshape(term_1,(-1,))term_2 = -tf.reduce_sum(tf.nn.softplus(tf.matmul(V,self._W)+self._c))return term_1+term_2def one_pass(self,X):h = tf.nn.sigmoid(tf.matmul(X,self._W)+self._c)return tf.matmul(h,tf.transpose(self._W))+self._bdef reconstruct(self,X):x = tf.nn.sigmoid(self.one_pass(X))return self.session.run(x,feed_dict={self._X:X})if __name__ == '__main__':mnist = input_data.read_data_sets("Mnist_data/",one_hot=True)trX,trY,teX,teY = mnist.train.images,mnist.train.labels,mnist.test.images,mnist.test.labelsXtrain = trX.astype(np.float32)Xtest = teX.astype(np.float32)_,m = Xtrain.shaperbm = RBM(m,100)# initialize all variablesinit = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)rbm.set_session(sess)err = rbm.fit(Xtrain)out = rbm.reconstruct(Xtest[0:100]) # let us reconstruct test data
参考http://c.biancheng.net/view/1954.html