Introduction to Matconvnet
MatConvNet是实现用于计算机视觉领域的卷积神经网络(CNN)的MATLAB工具箱。自从取得突破性工作以来,CNN在计算机视觉领域有一个重大影响,特别是图像理解,基本上取代了传统图像表示。有许多其他机器学习、深度学习和CNN开源库的存在。一些最受欢迎的:CudaConvNet ,Torch, Theano,Caffe等。MatConvNet是为研究人员提供一个尤其是友好和高效使用的环境,它其中包含许多CNN计算块,如卷积,归一化和池化等等,他们中的大部分是使用C++或CUDA编写的,这意味着它允许使用者写新的块来提高计算效率。MatConvNet可以学习AlexNet等大型深度CNN模型,这些强大的模型的Pre-trained版本可以从MatConvNet主页下载。虽然强大,但是MatConvNet易于使用和安装。实现是完全独立的,只需要MATLAB和兼容的c++编译器(使用GPU代码免费提供CUDA DevKit和合适的NVIDIA GPU)。
[注]:我下载的版本是matconvnet-1.0-beta19,这个在可以从MatConvNet主页下载,下载网址如下:http://www.vlfeat.org/matconvnet/
一、Getting started
编译MatConvNet的CPU版本
首先通过一个简单但是完整的例子看一下CNN是如何完成下载MatConvNet,编译,下载pre-trained CNN 模型,完成MATLAB图片分类的过程。代码可以从MatConvNet主页的http://www.vlfeat.org/matconvnet/pretrained/获得。
-
% install and compile MatConvNet (needed once) -
untar('http://www.vlfeat.org/matconvnet/download/matconvnet-1.0-beta20.tar.gz') ; -
cd matconvnet-1.0-beta20 -
run matlab/vl_compilenn -
% download a pre-trained CNN from the web (needed once) -
urlwrite(... -
'http://www.vlfeat.org/matconvnet/models/imagenet-vgg-f.mat', ... -
'imagenet-vgg-f.mat') ; -
% setup MatConvNet -
run matlab/vl_setupnn -
% load the pre-trained CNN -
net = load('imagenet-vgg-f.mat') ; -
net = vl_simplenn_tidy(net) ; -
% load and preprocess an image -
im = imread('peppers.png') ; -
im_ = single(im) ; % note: 0-255 range -
im_ = imresize(im_, net.meta.normalization.imageSize(1:2)) ; -
im_ = bsxfun(@minus, im_, net.meta.normalization.averageImage) ; -
% run the CNN -
res = vl_simplenn(net, im_) ; -
% show the classification result -
scores = squeeze(gather(res(end).x)) ; -
[bestScore, best] = max(scores) ; -
figure(1) ; clf ; imagesc(im) ; -
title(sprintf('%s (%d), score %.3f',... -
net.meta.classes.description{best}, best, bestScore));
注:1、untar('http://www.vlfeat.org/matconvnet/download/matconvnet-1.0-beta20.tar.gz') 是下载安装包的过程,建议单独下载其ZIP包,解压后放在任意位置,运行程序的时候会通过vl_setupnn()自动添加路径到Matlab中。下载时最好使用浏览器内置的下载器,因为迅雷下载下来的是一个txt文件,还需要转换。
2、run matlab/vl_compilenn是编译的过程,前提是要求matlab与编译器(VSc++)实现连接,如果没有可以使用mex -setup命令,设置matlab的C++编译器,提示MEX成功,才可以运行example中的示例。这个实际上就是配置Matconvnet的过程,只需要两句话:mex -setup;run matlab/vl_compilenn
3、run matlab/vl_setupnn,这句话在运行时总是报错,提示错误使用cd(当然上一句也可能出现这个问题,但我是直接运行的vl_compilenn,所以没出现,嘿嘿),在这里我将这句话改为run(fullfile(fileparts(mfilename('fullpath')),...
'..', 'matlab', 'vl_setupnn.m')) ,当然具体的语句与你所设的路径有关,就没有出现报错了。
4.net = load('imagenet-vgg-f.mat')这里net就是这个工具库所需要的预训练模型,在这里面链式网络已经架构完成,它的呈现形式是一个结构体,包括两部分,layers(因为这个结构有21层,故包含21个元胞)和meta(包含2个结构体,类别和标准化信息)。
5、程序的主体代码为vl_simplenn,包括CNN网络的输入输出及调用函数的过程。
编译MatConvNet的GPU版本
在GPU条件下编译,首先你的显卡得是INVIDA的,并且需要compute compability>2.0,其次一定要考虑版本相互协调的问题,我使用的版本是window7 65bits,vs2013,cuda7.5,MATLAB2014a,显卡是GTX960,compute compability=5.2,关于显卡是否合乎要求,也可以通过下载软件GPU Caps Viewer查看。

编译MatConvNet的GPU版本的具体步骤如下:
(1)官网下载CUDA 7.5.18、 以及 CUDA_Quick_Start_Guide.pdf,CUDA Toolkit 7.5.18 下载地址:http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_windows.exe
(2) 直接解压安装,建议采用默认安装的方式,方便MatConvNet按默认方式找到CUDA 编译器‘nvcc’。关于cuda与vs的具体配置,可以参考http://blog.csdn.net/listening5/article/details/50240147和http://www.cnblogs.com/shengshengwang/p/5139245.html
(3) 完成后打开 cuda samples 文件夹下 Samples_vs2013.sln 分别在DEBUG 和Release X64下进行完整编译。编译过程如提示找不到”d3dx9.h”、”d3dx10.h”、”d3dx11.h”头文件,则百度下载DXSDK_Jun10.exe并安装。下载网址http://www.microsoft.com/en-us/download/details.aspx?id=6812 之后再重新编译。
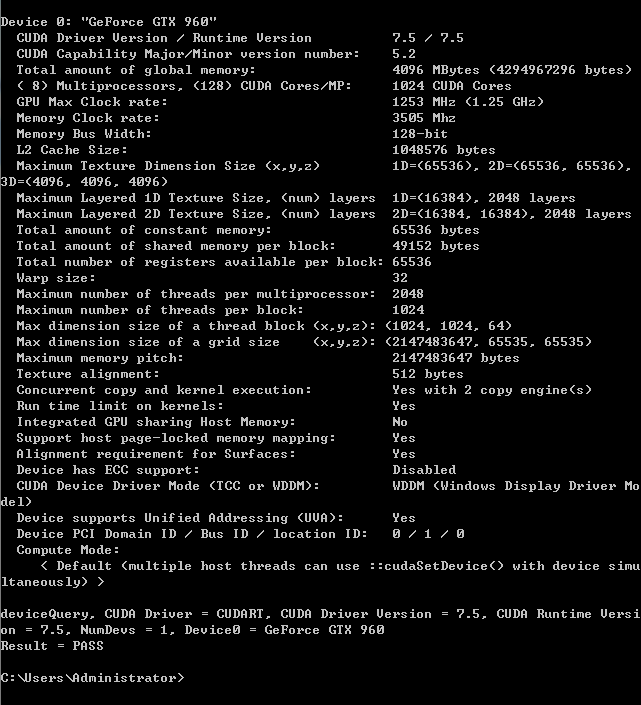
(4) 全部编译成功之后,打开CUDA Samples 文件夹下的 bin/win64/release ,如下图。运行其中的小程序,即可查看GPU CUDA信息。PASS 为通过。
(5)安装cudnn-win64-v4.0/or-v3.0,下载网址http://download.csdn.net/download/yfszzx/9307683直接解压到某文件夹下,将cudnn64_4.dll 文件拷贝到 ./matconvnet/Matlab/mex文件夹下即可。
(6)编译vl_compilenn程序,注意根据实际情况修改一些信息,大致调用方式为vl_compilenn('enableGpu',true,,'cudaMethod' ,'nvcc','enableCudnn','true','cudnnRoot','local/cuda),提示mex成功,则证明工作完成一大半了。
(7)最后就是运行cnn_cifa.m文件,运行前将程序中 opts.gpuDevice =[]改为opts.gpuDevice =[1];表示使用GPU显卡运行,运行结果如图
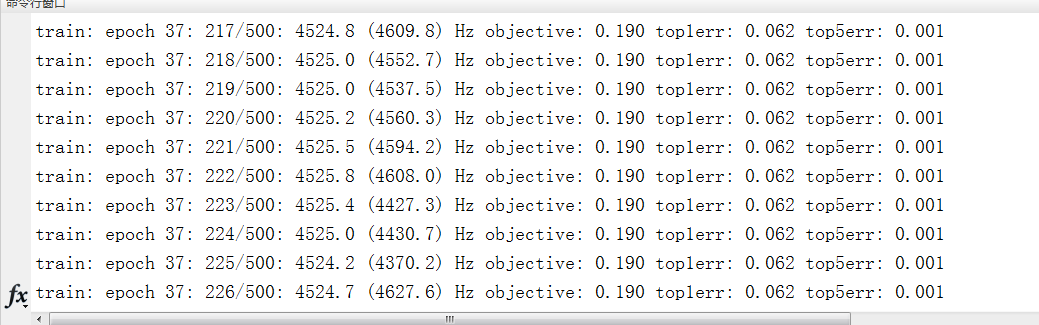
可见速度是相当快的!
接下来我们介绍一下这个工具库中的一些计算函数,方便大家理解。
Conputationnal blocks:实现cnn的计算块
一、卷积
Y = VL_NNCONV(X, F, B)计算图像堆x的卷积,F是卷积核,B是偏置。X=H*W*D*N, (H,W)是图像的高和宽,D是图像深度(特征频道的数目,例彩色就是3),N是堆中图像的数目。F=FW*FH*FD*K ,(FH,FW)是卷积核的大小,FD是卷积核的深度,须与D一致,或能整除D,K是卷积核的数目。针对一幅图像来说,卷积的公式为:
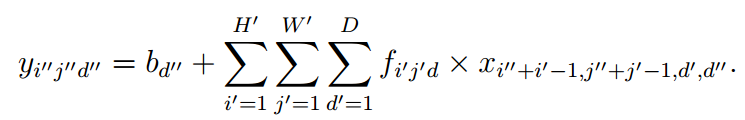 其中ij分别代表图像的高和宽,d”则代表了卷积核的数目,从而对应d”个输出。
其中ij分别代表图像的高和宽,d”则代表了卷积核的数目,从而对应d”个输出。
[DZDX, DZDF, DZDB] = VL_NNCONV(X, F, B, DZDY)计算映射到DZDY上的块的导数。这是反向传播中应用的梯度计算公式。
另外还有一些具体的变量设置。包括Stride=(sh,sw)是步长,即在卷积过程中每次移动的大小,这也决定了最后输出的大小,pad是补0的大小,表示为:
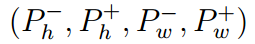
则最终输出的大小为:
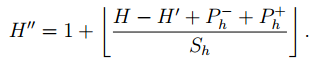
[注]:1、在Matconvnet中并不区分全连接层和卷积层,而认为前者是后者的一种特殊情况。
2、在Matconvnet中有Filter groups(即滤波组)的概念,意思是说vl_nnconv允许对输入x的通道进行分组,且每组应用不同子集的过滤器。groups=D/D',D是图像深度,D'是滤波器的深度,从而第一组可包括输入的1、2,,,D'维度,第二组包括输入的D'+1,,,2D',以此类推,但输出的大小是不变的。
二、卷积转换(反卷积)
Y = VL_NNCONVT(X, F, B)计算CNN的卷积转换,即进行卷积的反操作,其输入输出形式与上同。由于卷积支持输入补0输出进行下采样,因此反卷积支持输入上采样输出裁剪。
三、空间池化
Y = VL_NNPOOL(X, POOL)或Y = VL_NNPOOL(X, [POOLY, POOLX])对输入x的每个通道进行池化操作,池化的方式可以是求patch的最大值或平均值。同卷积相同,池化也支持pad和Stride操作,但pad有时是补负无穷。
四、激活函数
RELU函数:y = vl_nnrelu(x,dzdy,varargin),在leak=0时,表达式为

Sigmoid函数:out = vl_nnsigmoid(x,dzdy)

这里只给出了正向传播时的函数表达式,反向传播的(涉及dzdy)具体表达式可以看程序。
五、归一化
1、VL_NNNORMALIZE :CNN Local Response Normalization (LRN)
Local Response Normalization是对一个局部的输入区域进行的归一化,从表达式来看,也就是对每一个groups(前文)里的输入的相应子集进行归一化。表达式如下;其中的参数包括PARAM = [N KAPPA ALPHA BETA]
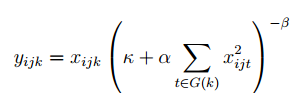
其中G(k)是对应通道k的输入相应子集,在程序中定义为 Q(k) = [max(1, k-FLOOR((N-1)/2)), min(D, k+CEIL((N-1)/2))];
2、VL_NNBNORM CNN 实现批次归一化
Y = VL_NNBNORM(X,G,B),这里XY均是4维张量,第4维T表示每批次处理的大小。标准化的表达式为
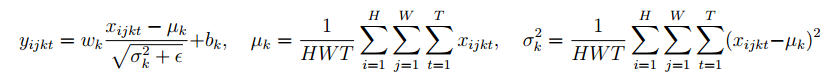
3.VL_NNSPNORM实现空间归一化
y = vl_nnspnorm(x, param, dzdy),PARAM = [PH PW ALPHA BETA];即对每个通道先进行池化操作,池化的方式为取平均,然后在进行归一化操作。其表达式为
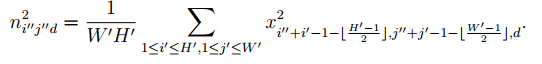
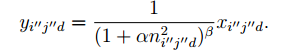
4、VL_NNSOFTMAX CNN softmax
Y = vl_nnsoftmax(X,dzdY):在一个groups(前文)中应用softmax函数,softmax函数可以看做一个激活函数和一个归一化操作的联合
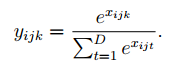 六、损失和比较
六、损失和比较
1、 [y1, y2] = vl_nnpdist(x, x0, p, varargin)计算每个向量x与目标x0之间的距离,定义为:
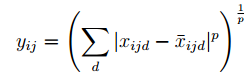
2. Y = vl_nnloss(X,c,dzdy,varargin)
原文链接:https://blog.csdn.net/Anysky___/article/details/51356158