Muduo日志模块解析
图片取自muduo网络库源码解析(1):多线程异步日志库(上)_李兆龙的技术博客_51CTO博客也是很好的日志讲解博客,这篇讲解流程基本上和它差不多,并且写的比我条理清楚很多
AppendFile::append() 这个函数是日志写入文件的最终函数,并且AppendFile这个类里面也是包含着减少磁盘IO的秘密
同步日志
先看LogFile
class LogFile : noncopyable
{public:LogFile(const string& basename, //日志文件名字off_t rollSize, //每个文件可以容纳的最大字节数bool threadSafe = true, //线程是否安全int flushInterval = 3, //刷新间隔int checkEveryN = 1024); ~LogFile();void append(const char* logline, int len); void flush(); bool rollFile();private:void append_unlocked(const char* logline, int len); //append内部调用此函数static string getLogFileName(const string& basename, time_t* now);//获取时间函数const string basename_;const off_t rollSize_;const int flushInterval_;const int checkEveryN_;int count_; //文件已经写入的日志行数std::unique_ptr<MutexLock> mutex_; //封装了mutextime_t startOfPeriod_; //time_t lastRoll_; //上次回滚的时间time_t lastFlush_; //上次刷新的时间std::unique_ptr<FileUtil::AppendFile> file_;const static int kRollPerSeconds_ = 60*60*24; //一天的秒数
};
接下来看看实现
LogFile::LogFile(const string& basename,off_t rollSize, bool threadSafe, int flushInterval, int checkEveryN) : basename_(basename), //写入日志的文件名(用户传入)rollSize_(rollSize), //一个文件中允许的最大字节数(用户传入)flushInterval_(flushInterval), //允许刷新的最大间隙 (可调整) 默认为 3秒checkEveryN_(checkEveryN), //允许停留在buffer中的最大日志条数 默认为1024条count_(0), //目前写入的条数,最大位checkEverN_mutex_(threadSafe ? new MutexLock : NULL), startOfPeriod_(0), //记录前一天的时间 以秒记录lastRoll_(0), //上次rollfile的时间,以秒记录lastFlush_(0) //上次fulsh的时间,以秒记录
{assert(basename.find('/') == string::npos); //判断文件名是否合法rollFile(); //创建新文件
}LogFile::~LogFile() = default;//
void LogFile::append(const char* logline, int len)
{if (mutex_){MutexLockGuard lock(*mutex_);append_unlocked(logline, len);}else{append_unlocked(logline, len);}
}void LogFile::flush()
{
//这里的if是保证线程安全的,如果上层没有上锁,那么这里上锁if (mutex_){MutexLockGuard lock(*mutex_); //RALL自动释放锁file_->flush(); //调用FileUtil::AppendFile中的fulush,把缓冲区的内容刷新到指定流中}else{file_->flush();}
}void LogFile::append_unlocked(const char* logline, int len)
{file_->append(logline, len); //把logline中的数据写入文件if (file_->writtenBytes() > rollSize_) //已经写入的字节数是否大于一个文件所容纳的最大字节数{rollFile(); //新开一个文件}else{++count_; //记录当前写入buffer中的日志条数if (count_ >= checkEveryN_) //大于buffer所容纳的最大条数{count_ = 0;time_t now = ::time(NULL);time_t thisPeriod_ = now / kRollPerSeconds_ * kRollPerSeconds_;if (thisPeriod_ != startOfPeriod_) //天数不同重新生成文件{rollFile();}else if (now - lastFlush_ > flushInterval_) //大于最大刷新间隔数,把buffer中的数据写入文件中{lastFlush_ = now; //更新上次刷新时间file_->flush(); //刷新缓冲区数据写入文件}}}
}bool LogFile::rollFile()
{time_t now = 0;//这里传递指针 可以由now得到标准时间 即Unix时间戳. 是自1970年1月1日00:00:00 GMT以来的秒数string filename = getLogFileName(basename_, &now);time_t start = now / kRollPerSeconds_ * kRollPerSeconds_;//相当于 now-(now%kRollPerSeconds_)if (now > lastRoll_) //当前天数大于lastRoll天数(隔天日志写在不同文件中){lastRoll_ = now; lastFlush_ = now;startOfPeriod_ = start;//记录上一次rollfile的日期(天)file_.reset(new FileUtil::AppendFile(filename));//换一个文件写日志,即为了保证两天的日志不写在同一个文件中 可能上一天的日志可能并未写到rollSize_大小return true;}return false;
}//生成文件名并获取
string LogFile::getLogFileName(const string& basename, time_t* now)
{string filename;filename.reserve(basename.size() + 64);//开辟大小,+64原因是全部的日期在格式化为字符串后为64字节filename = basename;char timebuf[32];struct tm tm;*now = time(NULL);gmtime_r(now, &tm); // FIXME: localtime_r ?strftime(timebuf, sizeof timebuf, ".%Y%m%d-%H%M%S.", &tm);filename += timebuf;filename += ProcessInfo::hostname();char pidbuf[32];snprintf(pidbuf, sizeof pidbuf, ".%d", ProcessInfo::pid());filename += pidbuf;filename += ".log";return filename;
}
接下来就是Appendfile
class AppendFile : noncopyable
{public:explicit AppendFile(StringArg filename); ~AppendFile();void append(const char* logline, size_t len); //实际写入文件void flush();off_t writtenBytes() const { return writtenBytes_; }private:size_t write(const char* logline, size_t len);FILE* fp_; //打开文件指针char buffer_[64*1024];//用户缓冲区 64kboff_t writtenBytes_; //已写入文件字节数
};
FileUtil::AppendFile::AppendFile(StringArg filename): fp_(::fopen(filename.c_str(), "ae")), // 'e' for O_CLOEXEC 打开文件流writtenBytes_(0)
{assert(fp_);::setbuffer(fp_, buffer_, sizeof buffer_); //把buffer设置为前端缓冲区64kb 也是文件流的缓冲区// posix_fadvise POSIX_FADV_DONTNEED ?
}FileUtil::AppendFile::~AppendFile()
{::fclose(fp_); //关闭文件流
}//把logline数据写入文件
void FileUtil::AppendFile::append(const char* logline, const size_t len)
{size_t written = 0;while (written != len){size_t remain = len - written;size_t n = write(logline + written, remain); //调用自己封装的writeif (n != remain){int err = ferror(fp_);if (err){fprintf(stderr, "AppendFile::append() failed %s\n", strerror_tl(err));break;}}written += n;}writtenBytes_ += written; //更新已写入文件字节数
}void FileUtil::AppendFile::flush()
{::fflush(fp_); //刷新流 stream 的输出缓冲区,就是上述指定的缓冲区buffer_size_t FileUtil::AppendFile::write(const char* logline, size_t len)
{// #undef fwrite_unlocked//上层调用已经保证了线程安全,所以这里使用线程不安全的 fwrite_unlock()写入fp_,目的是为了效率,最后通过 //fflush写入文件return ::fwrite_unlocked(logline, 1, len, fp_);
}
通过这两个类我们可以知道
LogFile:生成一个日志文件名,并且记录下写入文件的数据信息,由此来判断是否需要重新创建日志文件
AppendFile:创建了一个用户缓冲,最后通过fflush()函数刷新到文件中,或者在LofFile类中的rollFile()函数重新创建新 文件写入,并不会析构AppendFile对象,只是重新打开新文件,这样就不会造成缓冲区日志信息丢失
Logging用于提供写日志的接口
#define LOG_TRACE if (muduo::Logger::logLevel() <= muduo::Logger::TRACE) \muduo::Logger(__FILE__, __LINE__, muduo::Logger::TRACE, __func__).stream()
#define LOG_DEBUG if (muduo::Logger::logLevel() <= muduo::Logger::DEBUG) \muduo::Logger(__FILE__, __LINE__, muduo::Logger::DEBUG, __func__).stream()
#define LOG_INFO if (muduo::Logger::logLevel() <= muduo::Logger::INFO) \muduo::Logger(__FILE__, __LINE__).stream()
#define LOG_WARN muduo::Logger(__FILE__, __LINE__, muduo::Logger::WARN).stream()
#define LOG_ERROR muduo::Logger(__FILE__, __LINE__, muduo::Logger::ERROR).stream()
#define LOG_FATAL muduo::Logger(__FILE__, __LINE__, muduo::Logger::FATAL).stream()
#define LOG_SYSERR muduo::Logger(__FILE__, __LINE__, false).stream()
#define LOG_SYSFATAL muduo::Logger(__FILE__, __LINE__, true).stream()
SourceFile处理传入的路径
class SourceFile{public:template<int N>SourceFile(const char (&arr)[N]) //匹配传入的字符串数组,构造函数可隐式转换: data_(arr), //传入的字符串首地址size_(N-1) //传入的字符串数组的size(大小){//返回参二在参一中最后出现的位置的指针const char* slash = strrchr(data_, '/'); // builtin functionif (slash){data_ = slash + 1; //把data_置为末尾指针size_ -= static_cast<int>(data_ - arr); } }}
Impl
class Impl
{public://重声明日志级别枚举类typedef Logger::LogLevel LogLevel;Impl(LogLevel level, int old_errno, const SourceFile& file, int line);void formatTime();void finish();Timestamp time_; //提供当前时间 可得到1970年到现在的毫秒数与生成标准时间字符串LogStream stream_; //流LogLevel level_; //当前日志级别int line_; //日志行数 由__line__得到SourceFile basename_; //日志所属文件名 //由__file__与sourcefile_helper类得到
};
看下Impl的构造函数
Logger::Impl::Impl(LogLevel level, int savedErrno, const SourceFile& file, int line): time_(Timestamp::now()), //当前时间stream_(), //构造stream_对象level_(level), //初始化日志等级line_(line), //初始化行数basename_(file) //日志文件名字
{formatTime(); //写入一条日志信息的时间CurrentThread::tid();stream_ << T(CurrentThread::tidString(), CurrentThread::tidStringLength());//当前线程ID写入缓冲区stream_ << T(LogLevelName[level], 6);//当前日志等级写入缓冲区if (savedErrno != 0){stream_ << strerror_tl(savedErrno) << " (errno=" << savedErrno << ") ";}
}
通过这个构造函数就可以确定了一条日志的 时间 线程id 日志等级,并且使用 << 写入 stream_ 这里,从这里可以知道 LogStream 重载了 << 运算符.
formattTme(这个类中的时间处理现在我们不必过于关注,抓住主要流程)
void Logger::Impl::formatTime()
{int64_t microSecondsSinceEpoch = time_.microSecondsSinceEpoch(); //得到由1970到现在的微秒数//秒数与微秒数time_t seconds = static_cast<time_t>(microSecondsSinceEpoch / Timestamp::kMicroSecondsPerSecond);int microseconds = static_cast<int>(microSecondsSinceEpoch % Timestamp::kMicroSecondsPerSecond);/*效率提升的地方,t_lastSecond为__thread变量,意味着如果此次写入与上次写入在同一秒内,不必再生成一次重复的字符串*/if (seconds != t_lastSecond){t_lastSecond = seconds;struct DateTime dt;if (g_logTimeZone.valid()){dt = g_logTimeZone.toLocalTime(seconds);}else{dt = TimeZone::toUtcTime(seconds);}//t_time同样是__thread的int len = snprintf(t_time, sizeof(t_time), "%4d%02d%02d %02d:%02d:%02d",dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second);assert(len == 17); (void)len;}if (g_logTimeZone.valid()){Fmt us(".%06d ", microseconds); //Fmt是一个helper类assert(us.length() == 8);stream_ << T(t_time, 17) << T(us.data(), 8); //把时间写入 LogStream 中的字符串}else{Fmt us(".%06dZ ", microseconds);assert(us.length() == 9);stream_ << T(t_time, 17) << T(us.data(), 9);}
}
在Impl中的构造函数完成了一条日志的 时间 线程id 日志等级我们看下Logger析构函数做了什么事情
Logger::~Logger()
{impl_.finish(); //写入文件名与函数到LogStream中的缓冲区const LogStream::Buffer& buf(stream().buffer());//声明一个LogStream中的 data_[] 的引用g_output(buf.data(), buf.length()); /*把上述的引用传入这个回调函数,通过这个回调函数可以使用同步日志输出函数 或 异步日志输出函数同步:把 buf 直接传入到 LogFile里面的append函数中,写入文件异步:把 buf 传入到 AsyncLogging 里面的 append 函数中,然后通过 FiexdBuffer 的大缓冲来管理数据,最后在线程函数中传入给 LogFile 里面的append函数写入文件*/if (impl_.level_ == FATAL) //日志等级为致命{g_flush();abort(); //终止程序,从调用的地方跳出}
}
void Logger::Impl::finish()
{stream_ << " - " << basename_ << ':' << line_ << '\n';
}
析构中写入了 - 文件名 : 行数 \n
所以现在就可以知道一条完整的日志 时间 线程id 日志等级 日志内容 - 文件名 : 行数 \n
后续声明了一个 LogStream 对象的引用buf(就是引用 Impl中的 stream_) ,然后把 buf 中的数据传入 回调函数 g_output(),
通过这个回调函数,我们可以直接改变日志的输出方式,同步或异步(看到这里简直叹为观止) 通过封装一层函数,达到不同输出方式
现在我们来看下 LogStream
//缓冲区大小
const int kSmallBuffer = 4000; //同步日志使用
const int kLargeBuffer = 4000*1000; //异步日志使用
首先是FixedBuffer,这个类就是维护一个内存快( INFO << str 就是往这个内存块里面写数据)
class FixedBuffer : noncopyable
{public:FixedBuffer(): cur_(data_){setCookie(cookieStart);}~FixedBuffer(){setCookie(cookieEnd);}//把buf输入到缓冲区cur指向的位置,并且调整cur的位置void append(const char* /*restrict*/ buf, size_t len){// FIXME: append partiallyif (implicit_cast<size_t>(avail()) > len){memcpy(cur_, buf, len);cur_ += len;}}//返回缓冲区的首地址const char* data() const { return data_; }//获取缓冲区的长度int length() const { return static_cast<int>(cur_ - data_); }// write to data_ directly//返回当前可写缓冲区的首地址char* current() { return cur_; }//返回当前缓冲区的剩余空间int avail() const { return static_cast<int>(end() - cur_); }//调整cur指针void add(size_t len) { cur_ += len; }//重置缓冲区void reset() { cur_ = data_; }//封装memset(),data_的内存空间置为0void bzero() { memZero(data_, sizeof data_); }// for used by GDBconst char* debugString();void setCookie(void (*cookie)()) { cookie_ = cookie; }// for used by unit teststring toString() const { return string(data_, length()); }StringPiece toStringPiece() const { return StringPiece(data_, length()); }private://返回缓冲区末尾地址const char* end() const { return data_ + sizeof data_; }// Must be outline function for cookies.static void cookieStart();static void cookieEnd();void (*cookie_)();char data_[SIZE]; //缓冲区大小,以传入的SIZE为准char* cur_; //当前缓冲区可写位置的指针
};
Logstream类的主要部分
class LogStream : noncopyable
{typedef LogStream self;public:typedef detail::FixedBuffer<detail::kSmallBuffer> Buffer;......一串输出运算符的重载void append(const char* data, int len) { buffer_.append(data, len); }const Buffer& buffer() const { return buffer_; }void resetBuffer() { buffer_.reset(); }private:void staticCheck();template<typename T>void formatInteger(T); //用于数字转字符串,建议大家可以单独找找这个部分的博客看看,也是无敌的设计Buffer buffer_;static const int kMaxNumericSize = 32;};
重载我们看两个就行,其他都是一样的
字符类型:
self& operator<<(char v){buffer_.append(&v, 1);return *this;}
数值类型:
template<typename T>
void LogStream::formatInteger(T v)
{if (buffer_.avail() >= kMaxNumericSize){size_t len = convert(buffer_.current(), v); //int 转 char 并且加入了 buffer_ 中buffer_.add(len); // 更新buffer_的指针位置,即使是多线程环境,只要线程没有操作共享变量// 使用的是线程内部自己创建的变量,它就是线程安全的}
}LogStream& LogStream::operator<<(short v)
{*this << static_cast<int>(v); //转为int类型再次调用函数(int类型的) (链式编程)return *this;
}LogStream& LogStream::operator<<(int v)
{formatInteger(v); //调用这个模板函数,并且写入FiexdBUffer中的buffer_return *this;
}
至此我们的同步日志就完成了,可能还会有一些困惑,我们看一个muduo中的例子来一步步讲解:
#include "muduo/base/LogFile.h"
#include "muduo/base/Logging.h"#include <unistd.h>std::unique_ptr<muduo::LogFile> g_logFile;void outputFunc(const char* msg, int len)
{g_logFile->append(msg, len);
}void flushFunc()
{g_logFile->flush();
}int main(int argc, char* argv[])
{char name[256] = { '\0' };strncpy(name, argv[0], sizeof name - 1);g_logFile.reset(new muduo::LogFile(::basename(name), 200*1000));muduo::Logger::setOutput(outputFunc); //设置回调函数,调用LogFile中的 append() 同步日志muduo::Logger::setFlush(flushFunc); //设置回调, 调用LogFile中的flush() // 等同于调用 AppendFile -> fflush(fp_)//就是把缓冲区的数据从这个流刷新到文件中muduo::string line = "1234567890 abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ ";for (int i = 0; i < 10000; ++i){LOG_INFO << line << i;//usleep(1000); usleep(10000);}
}
大家可以先运行下这个Demo,看下日志文件是不是间隔写入数据的.
LOG_INFO << line << i;
底层调用
#define LOG_TRACE if (muduo::Logger::logLevel() <= muduo::Logger::TRACE) \
muduo::Logger(__FILE__, __LINE__).stream()调用Logger的构造函数
Logger::Logger(SourceFile file, int line): impl_(INFO, 0, file, line)
{
}
会调用SourceFile的构造函数,再掉用 impl 的构造函数至此 一条日志的 时间 线程id 日志等级 就完成了
之后
.stream() << line 就是把 line 中的字符输入到 .stream() 中的 buffer_ 现在 线程id 日志等级 日志内容 就完成了 最后该条语句结束调用 Impl 的析构函数把日志剩余部分加上,并且调用回调函数,写入用户缓冲区中,最后等待3秒刷新到日志文件中,或者其他条件满足.
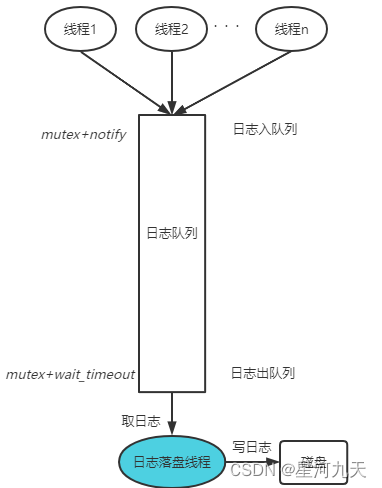
异步日志:
接下来就是异步日志,这部分推荐大家看陈硕大神的书图文并茂
主体流程:
前端有两个内存块用于写入日志信息,在线程函数中等待线程 超时唤醒 或 被唤醒后进行加锁处理前端的日志块(由于操作内存块需要mutex_所以在此期间还有日志写入的会被阻塞)在临界区代码段中,直接把存储当前内存块加入到前端数组块中,然后swap与后端数组交换临界区代码结束,之后只需要日志线程操作后端数组写入用户缓冲区即可
class AsyncLogging : noncopyable
{public:......
LogFile output(basename_, rollSize_, false);
void threadFunc();
//使用大块SIZE
typedef muduo::detail::FixedBuffer<muduo::detail::kLargeBuffer> Buffer;
//声明一个vector来管理Buffer
typedef std::vector<std::unique_ptr<Buffer>> BufferVector;
//STL 中的一个类型 value_type ==std::unique_ptr<Buffer>
typedef BufferVector::value_type BufferPtr; BufferPtr currentBuffer_ GUARDED_BY(mutex_); //当前缓冲区块
BufferPtr nextBuffer_ GUARDED_BY(mutex_); //下一个缓冲区块
BufferVector buffers_ GUARDED_BY(mutex_); //前端保存缓冲区块的数组
}
异步类中的append函数()
void AsyncLogging::append(const char* logline, int len)
{muduo::MutexLockGuard lock(mutex_);if (currentBuffer_->avail() > len){currentBuffer_->append(logline, len); //currentBuffer还未满,直接写入当前块}else{buffers_.push_back(std::move(currentBuffer_)); //currentBuffer满了就加入到vector中等待写入用户缓冲区if (nextBuffer_){currentBuffer_ = std::move(nextBuffer_);}else{currentBuffer_.reset(new Buffer); // Rarely happens}currentBuffer_->append(logline, len);cond_.notify();}
}
线程函数:
void AsyncLogging::threadFunc()
{assert(running_ == true);latch_.countDown();LogFile output(basename_, rollSize_, false);BufferPtr newBuffer1(new Buffer); //后备块1BufferPtr newBuffer2(new Buffer); //后备块2newBuffer1->bzero();newBuffer2->bzero();BufferVector buffersToWrite; buffersToWrite.reserve(16); //写入文件使用的 vector 后端保存缓冲区块的数组while (running_){assert(newBuffer1 && newBuffer1->length() == 0);assert(newBuffer2 && newBuffer2->length() == 0);assert(buffersToWrite.empty());{ //临界区muduo::MutexLockGuard lock(mutex_);if (buffers_.empty()) // unusual usage!{cond_.waitForSeconds(flushInterval_); //等待三秒或条件唤醒}buffers_.push_back(std::move(currentBuffer_)); //把currentBuffer_currentBuffer_ = std::move(newBuffer1); //把备用块1交给当前块buffersToWrite.swap(buffers_); //把前端数组中的数据交给后端数组写入用户缓冲区if (!nextBuffer_){nextBuffer_ = std::move(newBuffer2);}} //临界区结束assert(!buffersToWrite.empty());//异常处理,陈硕大神书中有讲这一块if (buffersToWrite.size() > 25){char buf[256];snprintf(buf, sizeof buf, "Dropped log messages at %s, %zd larger buffers\n",Timestamp::now().toFormattedString().c_str(),buffersToWrite.size()-2);fputs(buf, stderr);output.append(buf, static_cast<int>(strlen(buf)));buffersToWrite.erase(buffersToWrite.begin()+2, buffersToWrite.end());}//遍历后端数组,并且依次写入缓冲区for (const auto& buffer : buffersToWrite){// FIXME: use unbuffered stdio FILE ? or use ::writev ?output.append(buffer->data(), buffer->length());}//留下两块用于填充后备块if (buffersToWrite.size() > 2){// drop non-bzero-ed buffers, avoid trashingbuffersToWrite.resize(2);}if (!newBuffer1){assert(!buffersToWrite.empty());newBuffer1 = std::move(buffersToWrite.back());buffersToWrite.pop_back();newBuffer1->reset();}if (!newBuffer2){assert(!buffersToWrite.empty());newBuffer2 = std::move(buffersToWrite.back());buffersToWrite.pop_back();newBuffer2->reset();}buffersToWrite.clear();output.flush();}output.flush();
}