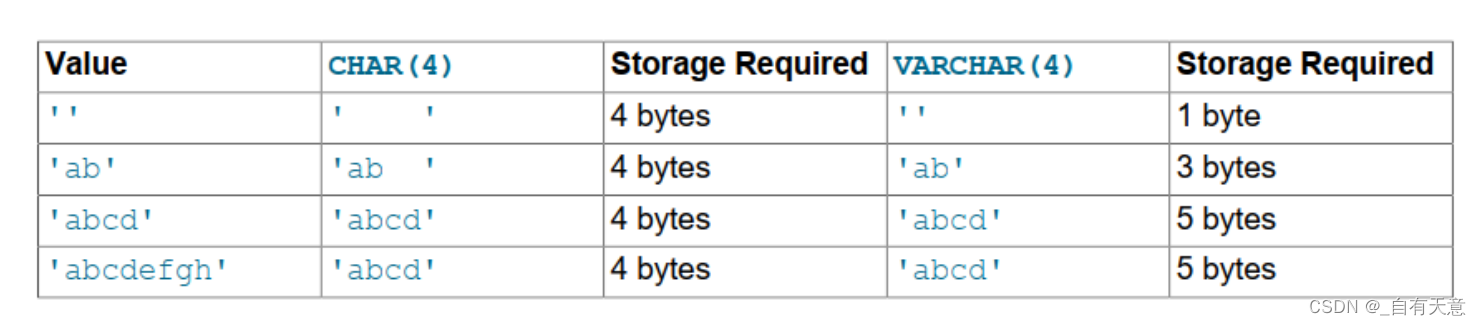
一,引言
在开发中,经常遇到前端需要实现一个多层级的目录树,那么后端就需要根据这种结构返回对应的数据,因此在这里记录一下本人在开发中是如何实现这个多层级的目录树。
二,建表建库
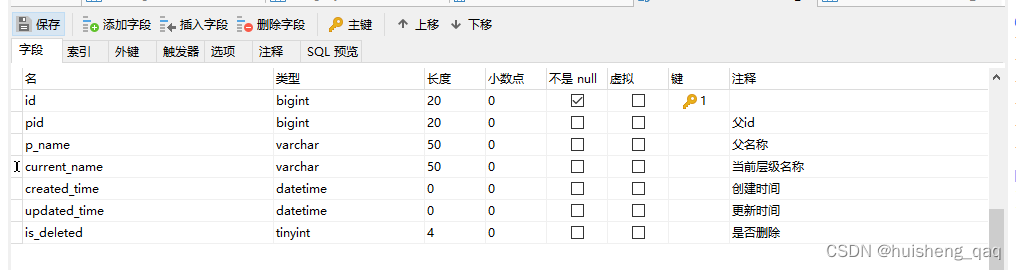
在建表时,需要注意的是一定要一个Pid和当前id,这样用于实现这个子级和父级的关联。建表语句如下
CREATE TABLE `site` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `pid` bigint(20) DEFAULT NULL COMMENT '父id', `p_name` varchar(50) DEFAULT NULL COMMENT '父名称', `current_name` varchar(50) DEFAULT NULL COMMENT '当前层级名称', `created_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间', `updated_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `is_deleted` tinyint(4) DEFAULT NULL COMMENT '是否删除', PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=35 DEFAULT CHARSET=utf8;
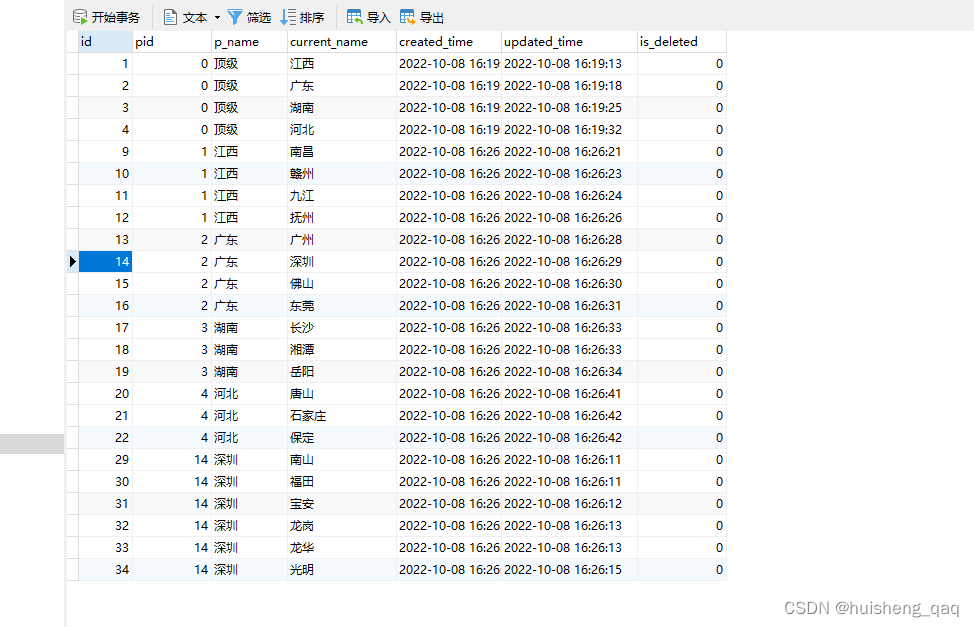
可以参考一下我的,也可以自己插入一些数据。接下来插入数据
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (0,'顶级','江西',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (0,'顶级','广东',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (0,'顶级','湖南',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (0,'顶级','河北',now(),now(),0);insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (1,'江西','南昌',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (1,'江西','赣州',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (1,'江西','九江',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (1,'江西','佛山',now(),now(),0);insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (2,'广东','广州',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (2,'广东','深圳',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (2,'广东','佛山',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (2,'广东','东莞',now(),now(),0);insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (3,'湖南','长沙',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (3,'湖南','湘潭',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (3,'湖南','岳阳',now(),now(),0);insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (4,'河北','唐山',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (4,'河北','石家庄',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (4,'河北','保定',now(),now(),0);insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'南山',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'福田',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'宝安',,now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'龙岗',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'龙华',now(),now(),0);
insert into site (pid,p_name,current_name,created_time,updated_time,is_deleted) VALUES (10,'深圳',,'光明',now(),now(),0);
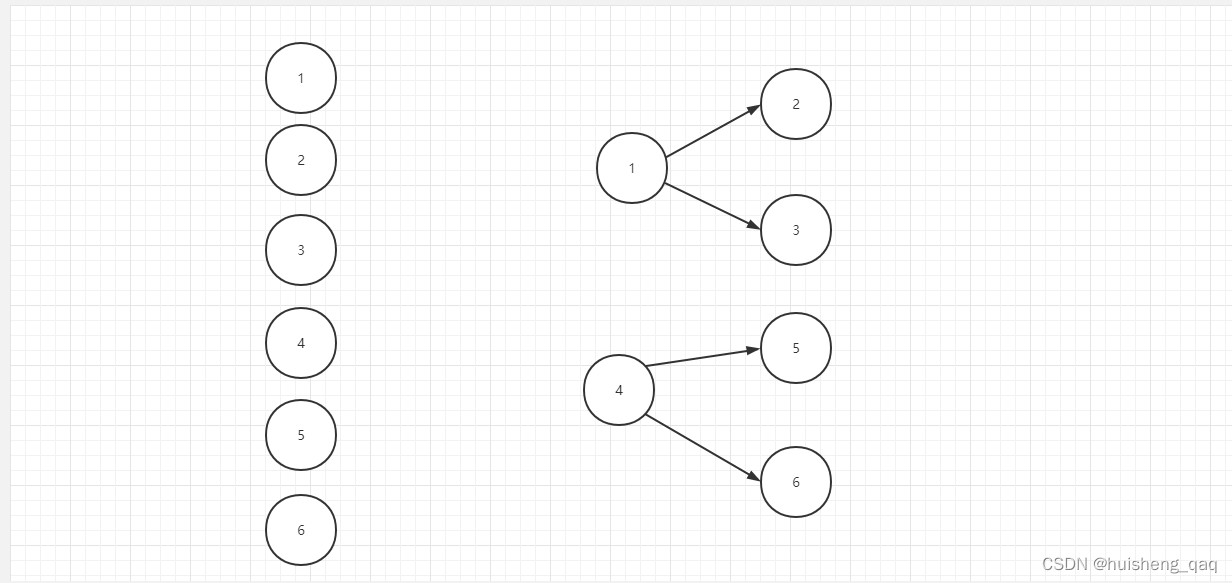
三,原理
就是利用递归思想,将所有的数据遍历,然后是否有其他结点的Pid为当前结点的id,因此这个数据库的表一定要有一个pid。其实就是类似于两个嵌套的for循环,一个用于遍历,一个用于查找。如果查找成功,那么将那个结点做为当前结点的子节点
for(int i = 0; i < list.size; i++){for(int j = 0; j < list.size; j++){...}
}
就是将之前在集合中全部零散的结点,变成一棵树状型的树。然后这个1,4结点就是最上面的顶层结点,其他结点依次遍历加入到这两棵子树的后面,最后将这两棵树加入到一个集合里面,就变成了一棵大树。也可以参考一下后面的代码,将这个原理再理解一下。
四,代码实现
这里主要使用springboot项目,依赖和数据库连接之类的暂时不讲。可以参考一下我之前写的这篇https://blog.csdn.net/zhenghuishengq/article/details/109510128?spm=1001.2014.3001.5502
1,实体类
/*** @author zhenghuisheng* @date : 2022/10/8*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Site implements Serializable {@TableId(value = "id", type = IdType.ASSIGN_ID)@JsonSerialize(using = ToStringSerializer.class)public Long id;@JsonSerialize(using = ToStringSerializer.class)public Long pid;public String pname;public String currentName;public Date createdTime;public Date updatedTime;public Integer isDeleted;
}2、dto类
对应上面的实体类,并在里面加入一个siteDtoList字段,用于保存当前结点的子集。
@Data
public class SiteDto implements Serializable {private static final long serialVersionUID = 1L;//用户idpublic Long id;//父idpublic Long pid;//父级namepublic String pname;//当前名称public String currentName;//创建时间public String createdTime;//更新时间public String updatedTime;//是否删除public Integer isDeleted;//子集,用于存储当前目录下面的全部子集public List<SiteDto> siteDtoList;
}
3,mybatis里面的sql
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.SiteMapper"><resultMap id="baseMap" type="com.example.demo.pojo.Site"><id column="id" property="id"></id><result column="pid" property="pid"></result><result column="p_name" property="pname"></result><result column="current_name" property="currentName"></result><result column="created_time" property="createdTime"></result><result column="updated_time" property="updatedTime"></result><result column="is_deleted" property="isDeleted"></result></resultMap><select id="queryAll" resultMap="baseMap" resultType="com.example.demo.pojo.Site">select * from site where is_deleted = 0;</select></mapper>
4,Mapper类
/*** @author zhenghuisheng* @date : 2022/10/8*/
@Repository
@Mapper
public interface SiteMapper {List<Site> queryAll();
}
5,service类
把这个看懂就基本上没问题了
/*** @author zhenghuisheng* @date : 2022/10/8*/
@Service
public class SiteService {@Autowiredprivate SiteMapper siteMapper;public List<SiteDto> queryAll(){List<SiteDto> datas = new ArrayList<>();//获取全部数据List<Site> siteList = siteMapper.queryAll();if (siteList != null){//将这个数据赋值到dto里面List<SiteDto> siteDtoList = siteList.stream().map(site -> {SiteDto siteDto = new SiteDto();BeanUtils.copyProperties(site,siteDto);//时间格式化siteDto.setCreatedTime(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(site.createdTime));siteDto.setUpdatedTime(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(site.updatedTime));return siteDto;}).collect(Collectors.toList());//遍历全部的数据,利用递归思想,获取全部的子集siteDtoList.forEach(e ->{//判断当前id是否为其他数据的父idList<SiteDto> childrenList = getChildrenList(e.getId(), siteDtoList);//设置子集,如果到了最后一级,那么直接设置为null,不展示这个属性即可e.setSiteDtoList(childrenList != null ? childrenList : null);});//获取所有的顶点数据,即最上层数据,该数据的pid为0//注意这个pid的数据类型,如果数据库为varchar则equals("0") 整型则为equals(0)List<SiteDto> siteDtoParents = siteDtoList.stream().filter(t -> t.getPid().equals(0L)).collect(Collectors.toList());datas.addAll(siteDtoParents);}return datas;}//获取全部的子集合public static List<SiteDto> getChildrenList(String id,List<SiteDto> list){//便利全部数据,将需要的数据过滤出来return list.stream().filter(t-> t.getPid().equals(id)).collect(Collectors.toList());}
}7,Contrller类测试
/*** @author zhenghuisheng* @date : 2022/10/8*/
@RestController
public class SiteController {@Autowiredprivate SiteService siteService;@RequestMapping("/getAllData")public List<SiteDto> getAllData(){return siteService.queryAll();}
}
用postman测试一下,结果就出来了
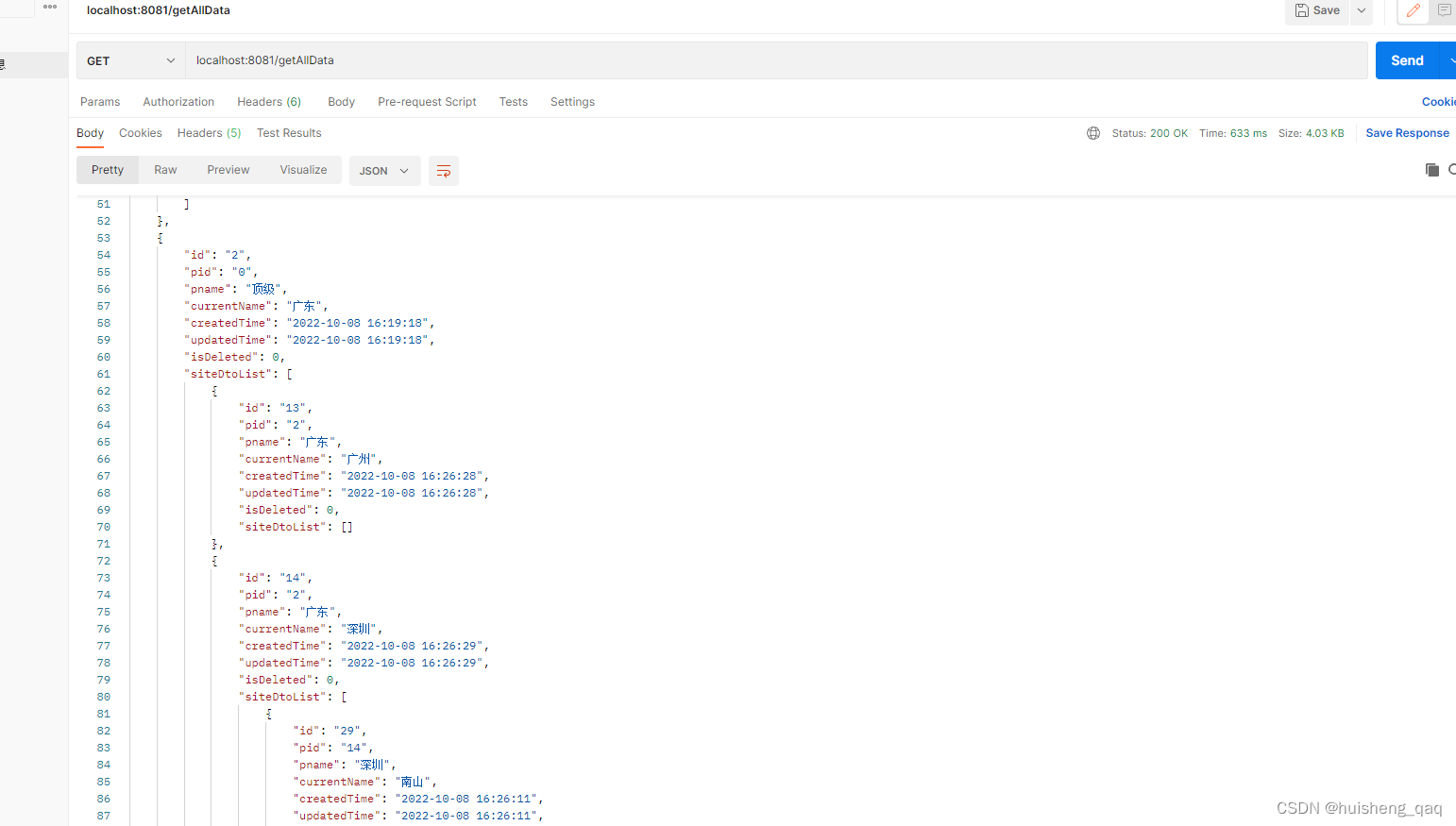
这样就大功告成了!!