概述
”树“在计算机的世界里是一个基本的数据结构,很多地方都能看到”树“的身影。最常见的应该是在各种软件和网页的菜单栏中,多层级的折叠其实就是以一棵树的形式进行展现的,如下图所示:

在树的层级和标签类别比较少,并且标签类别比较固定的时候,有时候是直接由前端同学硬编码实现。如果想要修改某个类别,则需要改动前端代码;如果想要增加类别,则需要大量改动前端代码。这种方式显然是不合理的,因此我们常常会从数据库中读取整个菜单的数据,并加以处理进行展现,再实现一些简单的接口,对数据库的数据进行增删改查,实现对菜单中类别树的动态控制。本文想要讨论的问题就是,为了实现动态加载网页中的树形结构,数据库里的数据应该如何设计和存储,又应该在返回前端之前进行怎样的数据处理呢?本文将以一个简单的层级结构为例,对这个问题进行探讨:
└── root├── level-1├── level-2│ ├── level-2.1│ └── level-2.2│ ├── level-2.2.1│ └── level-2.2.2└── level-3└── level-3.1
数据库存储
在数据结构中,如果想要在一棵树中定位某一个节点,我们需要知道它在某种特定遍历方式(层序遍历、前中后序遍历)中是第几个节点。在数据库中,我们需要思考的是存储什么信息,能够让整棵类别树的增删改查变得容易,因此我们可以从增删改查操作中思考需要存储哪些信息。
增加:增加一个节点时,首先需要知道当前节点应该挂在哪个父节点下面,因此父节点id是必要的。同时这里有一个注意点,第一层级的节点是没有父节点的,所以我们需要虚拟出一个值作为根节点,也就是第一层级所有节点的父节点。
删除:删除只需要根据节点id就可以直接进行删除。
修改:修改也只需要根据节点id就可以进行更新。
查询:查询分两部分。第一部分是查询某个节点的子节点,也就是展开操作,可以直接查询父节点id为xxx的节点,因此父节点id是必要的;第二部分是查询某个层级的所有节点,此时光有父节点id是不够的,因此必须引入一个层级id的字段。
综上,我们只需要在数据库中存储父类别的id和分类层级,即可以完成对整棵分类树的所有操作。
至于为什么是存储父类别id,而不是子类别id。可以思考一下,因为父和子之间的关系其实是一对多的关系,所以如果存储子类别id,每一个节点的信息是需要存储多条记录的,并且数据存在大量冗余;如果存储的是父类别id,子和父之间的关系是多对一,因此每一节点只需要存储一条记录,即可表征父子关系,且整个数据库不存在数据冗余。
经过一通分析,最终我们定义出如下数据库:
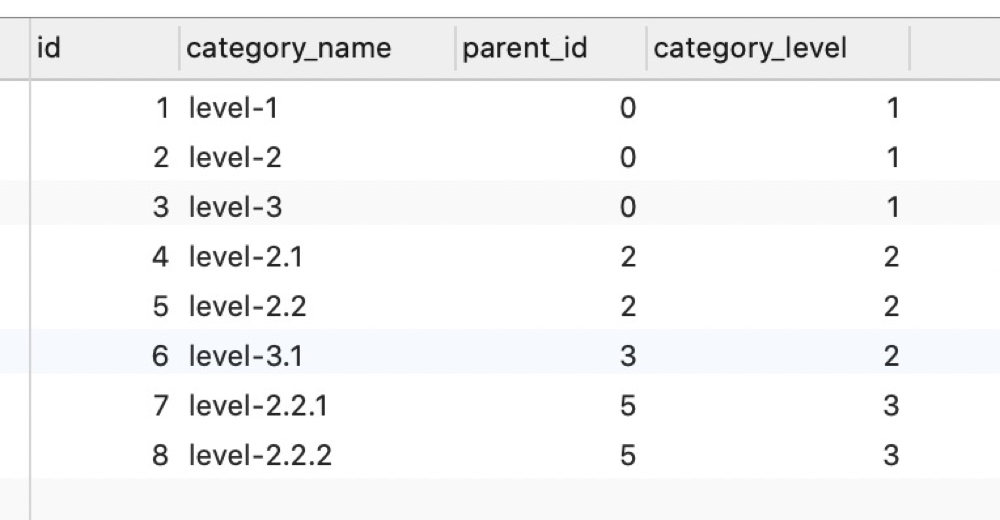
其中parent_id代表父类别的id,第一层级的父类别id为0;category_level是代表当前类别所在层级,从1开始计数。
建表语句如下:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for category_info
-- ----------------------------
DROP TABLE IF EXISTS `category_info`;
CREATE TABLE `category_info` (`id` int NOT NULL AUTO_INCREMENT,`category_name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '分类名称',`parent_id` int NOT NULL DEFAULT '0' COMMENT '当前分类父类的id,如果无父类则为0',`category_level` int NOT NULL COMMENT '分类层级',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3 COMMENT='分类信息表';-- ----------------------------
-- Records of category_info
-- ----------------------------
BEGIN;
INSERT INTO `category_info` VALUES (1, 'level-1', 0, 1);
INSERT INTO `category_info` VALUES (2, 'level-2', 0, 1);
INSERT INTO `category_info` VALUES (3, 'level-3', 0, 1);
INSERT INTO `category_info` VALUES (4, 'level-2.1', 2, 2);
INSERT INTO `category_info` VALUES (5, 'level-2.2', 2, 2);
INSERT INTO `category_info` VALUES (6, 'level-3.1', 3, 2);
INSERT INTO `category_info` VALUES (7, 'level-2.2.1', 5, 3);
INSERT INTO `category_info` VALUES (8, 'level-2.2.2', 5, 3);
COMMIT;SET FOREIGN_KEY_CHECKS = 1;
树形结构生成
数据库的数据有了,那么我们该怎么返回什么样的数据给前端进行渲染呢?众所周知,json是一种常见的,用于前后端交互的数据格式,因此我们可以构造出一棵json树,交由前端同学进行数据绑定。代码如下:
# -*- coding: utf-8 -*-
import json# categories_list从db获取,此处是为了方便展示
category_list = [{'id': 1, 'category_name': 'level-1', 'parent_id': 0, 'category_level': 1},{'id': 2, 'category_name': 'level-2', 'parent_id': 0, 'category_level': 1},{'id': 3, 'category_name': 'level-3', 'parent_id': 0, 'category_level': 1},{'id': 4, 'category_name': 'level-2.1', 'parent_id': 2, 'category_level': 2},{'id': 5, 'category_name': 'level-2.2', 'parent_id': 2, 'category_level': 2},{'id': 6, 'category_name': 'level-3.1', 'parent_id': 3, 'category_level': 2},{'id': 7, 'category_name': 'level-2.2.1', 'parent_id': 5, 'category_level': 3},{'id': 8, 'category_name': 'level-2.2.2', 'parent_id': 6, 'category_level': 3}]def get_categories_tree():# 从db读取category数据# categories_list = db.get_all_categories()# 构建map: category_id -> category对象categories_map = {}for category in category_list:category["sub_categories"] = []categories_map[category["id"]] = category# 将父子类别连接形成树结构categories_tree = []for category in category_list:# 第一层级类别直接加入数组if category["parent_id"] == 0 and category["category_level"] == 1:categories_tree.append(category)# 如果是其它层级的类别,则将当前类别添加到父类别中的sub_categories中else:categories_map[category["parent_id"]]["sub_categories"].append(category)return categories_treeif __name__ == '__main__':category_tree = get_categories_tree()print(json.dumps(category_tree))
构造树的整体思想是:先建立好id->对象的映射关系,并增加用于存储子类别对象的数组;然后遍历数据,将当前节点添加到父类别的子类别数组中。其实就是我们在数据库存储阶段讨论到的,为何不存储子类别id而是父类别id。从存储角度而言,存储父类别id是更优的方案;但是从可视化角度而言,给每个类别加上子类别数组更容易渲染。因此我们通过以上转化,达成了存储和可视化两者皆优的目标。
最后我们查看一下输出的json树是长什么样的:

符合预期,任务完成~
更新
有序目录树的构造一文基于此问题进行了优化总结。