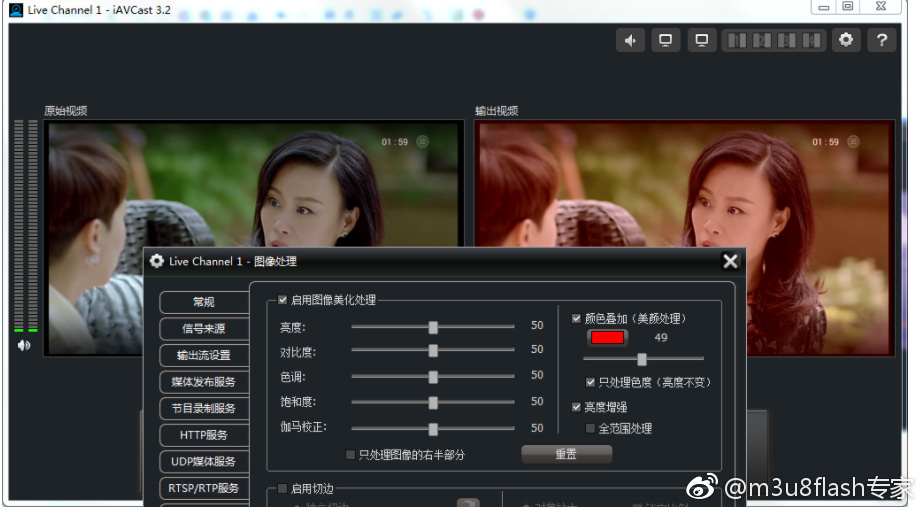
拉流(播放)
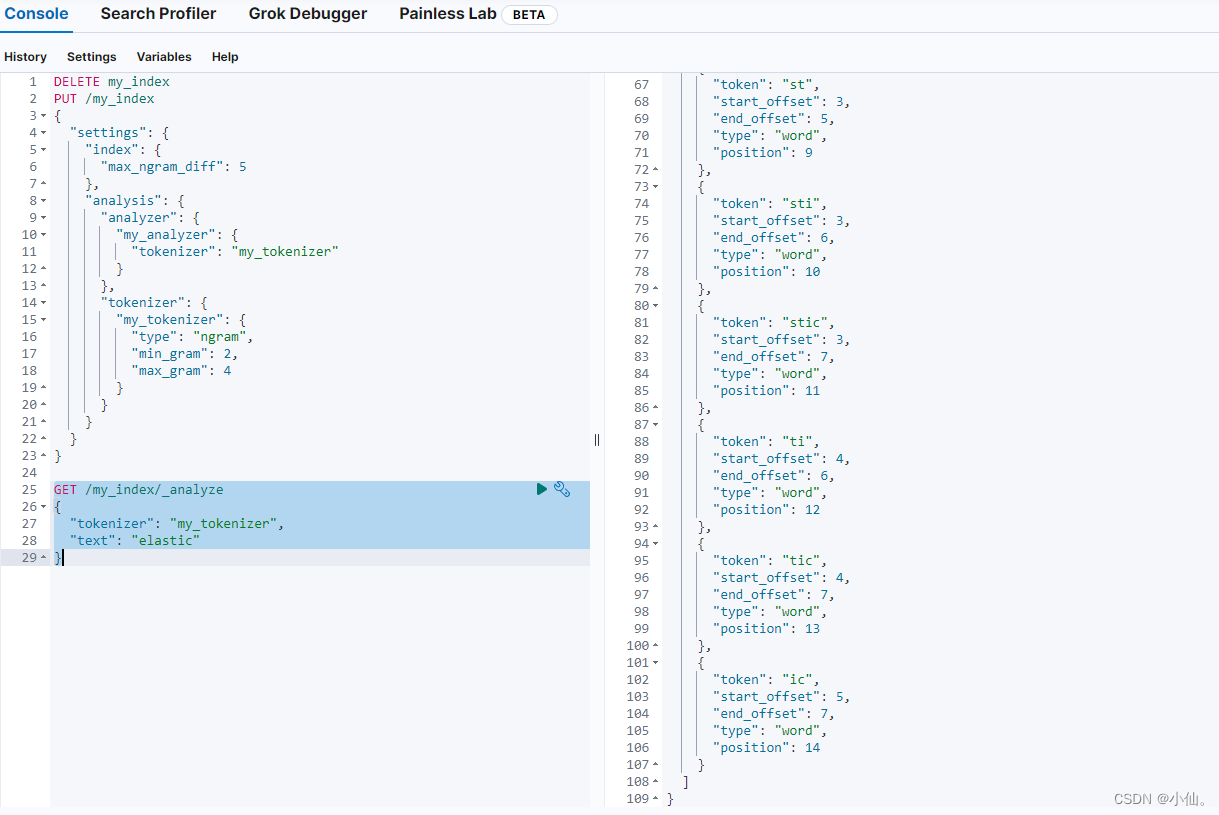
根据协议类型(如RTMP、RTP、RTSP、HTTP等),与服务器建立连接并接收数据;
- 解析二进制数据,从中找到相关流信息;
- 根据不同的封装格式(如FLV、TS)解复用(demux);
- 分别得到已编码的H.264视频数据和AAC音频数据;
- 使用硬解码(对应系统的API)或软解码(FFMpeg)来解压音视频数据;
- 经过解码后得到原始的视频数据(YUV)和音频数据(AAC);
- 因为音频和视频解码是分开的,所以我们得把它们同步起来,否则会出现音视频不同步的现象,比如别人说话会跟口型对不上;
- 最后把同步的音频数据送到耳机或外放,视频数据送到屏幕上显示。
了解了播放器的播放流程后,我们可以优化以下几点:
- 首屏时间优化
从步骤2入手,通过预设解码器类型,省去探测文件类型时间;
从步骤5入手,缩小视频数据探测范围,同时也意味着减少了需要下载的数据量,特别是在网络不好的时候,减少下载的数据量能为启动播放节省大量的时间,当检测到I帧数据后就立马返回并进入解码环节。
推流

- 经过输出设备(AVCaptureVideoDataOutput)得到原始的采样数据–视频数据(YUV)和音频数据(AAC);
- 使用硬编码(对应系统的API)或软编码(FFMpeg)来编码压缩音视频数据;
- 分别得到已编码的H.264视频数据和AAC音频数据;
- 根据不同的封装格式(如FLV、TS、MPEG-TS);
- 使用HLS协议的时候加上这一步(HLS分段生成策略及m3u8索引文件);
- 通过流上传到服务器;
- 服务器进行相关协议的分发;
推流步骤说明:很容易看出推流跟播放其实是逆向的,具体流程就不多说了。
- 优化一:适当的Qos(Quality of Service,服务质量)策略。
推流端会根据当前上行网络情况控制音视频数据发包和编码,在网络较差的情况下,音视频数据发送不出去,造成数据滞留在本地,这时,会停掉编码器防止发送数据进一步滞留,同时会根据网络情况选择合适的策略控制音视频发送。
比如网络很差的情况下,推流端会优先发送音频数据,保证用户能听到声音,并在一定间隔内发关键帧数据,保证用户在一定时间间隔之后能看到一些画面的变化。 - 优化二:合理的关键帧配置。
合理控制关键帧发送间隔(建议2秒或1秒一个),这样可以减少后端处理过程,为后端的缓冲区设置更小创造条件。
软硬编解选择
- 网上有不少关于选择软解还是硬解的分析文章,这里也介绍一些经验,但根本问题是,没有一个通用方案能最优适配所有操作系统和机型;
- 推流编码: 推荐Andorid4.3(API18)或以上使用硬编,以下版本使用软编;iOS使用全硬编方案;
- 播放解码:Andorid、iOS播放器都使用软解码方案,经过我们和大量客户的测试以及总结,虽然牺牲了功耗,但是在部分细节方面表现会较优,且可控性强,兼容性也强,出错情况少,推荐使用。
- 附软硬编解码优缺点对比:
| 编解码器类型 | 优点 | 缺点 |
|---|---|---|
| 软编解码 | 各平台兼容性强;解码色彩较硬编码好;编解码可操控空间大,自由度高,更容易定制 | cpu消耗比较大 |
| 硬编解码 | 功耗低,执行效率比较高 | 不同机型的芯片对编解码的实现不同,兼容性比较差;可控性比较差 |
采集
采集的步骤:
- 创建AVCaptureSession
- 输入对象AVCaptureDeviceInput
- 输出对象AVCaptureVideoDataOutput
- 输出代理方法captureOutput(_:didOutputSampleBuffer:fromConnection:)
相关内容
采集数据:iOS平台上采集音视频数据,需要使用AVFoundation.Framework框架,从captureSession会话的回调中获取音频,视频数据。
传输层协议:主要采用RTMP协议居多(默认端口1935,采用TCP协议),也有部分使用HLS协议
音/视频编码解码:FFmpeg编码解码
视频编码格式:H.265、H.264、MPEG-4等,封装容器有TS、MKV、AVI、MP4等
音频编码格式:G.711μ、AAC、Opus等,封装有MP3、OGG、AAC等
渲染工具:采用OpenGL渲染YUV数据,呈现视频画面。将PCM送入设备的硬件资源播放,产生声音。iOS播放流式音频,使用Audio Queue 的方式,即,利用AudioToolbox.Framework 框架。