函数参数run( fetches, feed_dict=None, options=None, run_metadata=None)
feed_dict参数的作用是替换图中的某个tensor的值。例如:
a = tf.add(2, 5)
b = tf.multiply(a, 3)
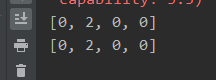
with tf.Session() as sess: sess.run(b)21
replace_dict = {a: 15}
sess.run(b, feed_dict = replace_dict)45
这样做的好处是在某些情况下可以避免一些不必要的计算。
除此之外,feed_dict还可以用来设置graph的输入值,这就引入了
x = tf.placeholder(tf.float32, shape=(1, 2))
w1 = tf.Variable(tf.random_normal([2, 3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3, 1],stddev=1,seed=1))a = tf.matmul(x,w1)
y = tf.matmul(a,w2)with tf.Session() as sess:# 变量运行前必须做初始化操作init_op = tf.global_variables_initializer()sess.run(init_op)print(sess.run(y, feed_dict={x:[[0.7, 0.5]]}))[[3.0904665]]
或者 多输入
x = tf.placeholder(tf.float32, shape=(None, 2))
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))a = tf.matmul(x,w1)
y = tf.matmul(a,w2)with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)print(sess.run(y, feed_dict={x:[[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]}))print(sess.run(w1))print(sess.run(w2))[[3.0904665]
[1.2236414]
[1.7270732]
[2.2305048]]
[[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
[[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
注意:此时的a不是一个tensor,而是一个placeholder。我们定义了它的type和shape,但是并没有具体的值。在后面定义graph的代码中,placeholder看上去和普通的tensor对象一样。在运行程序的时候我们用feed_dict的方式把具体的值提供给placeholder,达到了给graph提供input的目的。
placeholder有点像在定义函数的时候用到的参数。我们在写函数内部代码的时候,虽然用到了参数,但并不知道参数所代表的值。只有在调用函数的时候,我们才把具体的值传递给参数。
这个例子是用Tensorflow构建一个简单的计算图
import tensorflow as tf#使用tensorflow在默认的图中创建节点,这个节点是一个变量,命名为“counter”
state = tf.Variable(0, name="counter")#创建一个常量
one = tf.constant(1)#对常量与变量进行简单的加法操作,这点需要说明的是: 在TensoorFlow中,
#所有的操作op和变量都视为节点,tf.add() 的意思就是在tf的默认图中添加一个op,这个op是用来做加法操作的。
new_value = tf.add(state,one)#赋值操作。将new_value的值赋值给update变量
update = tf.assign(state,new_value)#此处用于初始化变量。但是这句话仍然不会立即执行。需要通过sess来将数据流动起来 。如果有Variable,一定需要写这句话
init = tf.initialize_all_variables()#切记:所有的运算都应该在session中进行,即 with tf.Session() as sess
with tf.Session() as sess:#对变量进行初始化,执行(run)init语句sess.run(init)#循环3次,并且打印输出。for _ in range(3):sess.run(update)# 打印变量时也需要用sess.runprint(sess.run(state))结果如下:

注意:
-
TensorFlow与我们正常的编程思维略有不同:TensorFlow中的语句不会立即执行;而是等到开启会话session的时候,才会执行session.run()中的语句。如果run中涉及到其他的节点,也会执行到。
-
Tesorflow模型中的所有的节点都是可以视为运算操作op或tensor