数据处理
import polars as pltrain = pl.read_parquet('../input/otto-train-and-test-data-for-local-validation/test.parquet')
train_labels = pl.read_parquet('../input/otto-train-and-test-data-for-local-validation/test_labels.parquet')def add_action_num_reverse_chrono(df):return df.select([pl.col('*'),pl.col('session').cumcount().reverse().over('session').alias('action_num_reverse_chrono')])def add_session_length(df):return df.select([pl.col('*'),pl.col('session').count().over('session').alias('session_length')])def add_log_recency_score(df):linear_interpolation = 0.1 + ((1-0.1) / (df['session_length']-1)) * (df['session_length']-df['action_num_reverse_chrono']-1)return df.with_columns(pl.Series(2**linear_interpolation - 1).alias('log_recency_score')).fill_nan(1)def add_type_weighted_log_recency_score(df):type_weights = {0:1, 1:6, 2:3}type_weighted_log_recency_score = pl.Series(df['log_recency_score'] / df['type'].apply(lambda x: type_weights[x]))return df.with_column(type_weighted_log_recency_score.alias('type_weighted_log_recency_score'))def apply(df, pipeline):for f in pipeline:df = f(df)return dfpipeline = [add_action_num_reverse_chrono, add_session_length, add_log_recency_score, add_type_weighted_log_recency_score]train = apply(train, pipeline)train.head()看看数据先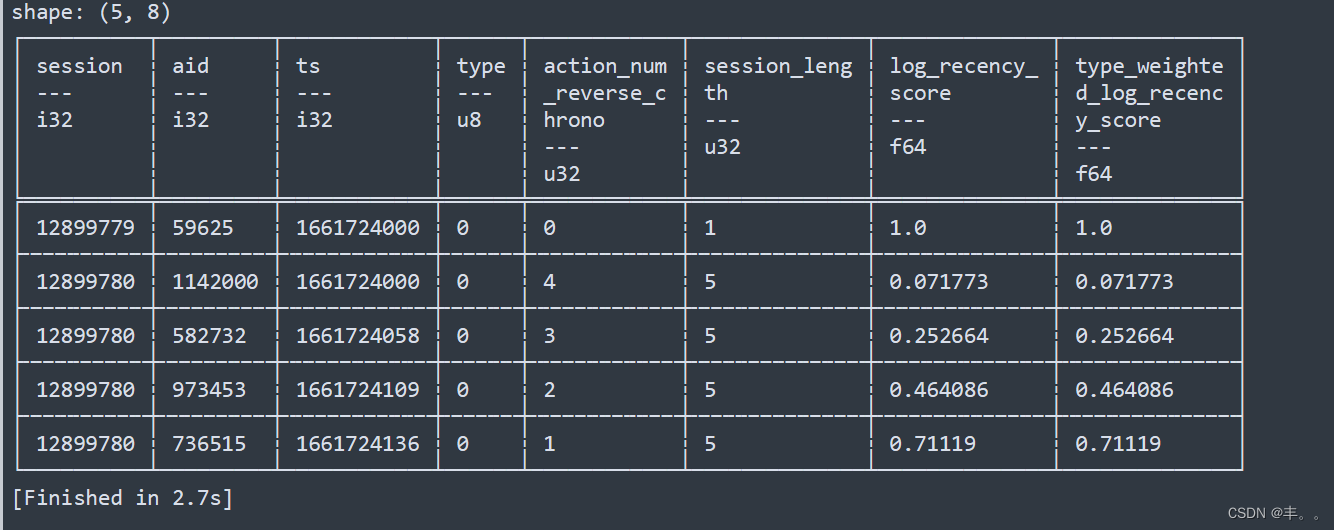
现在我们需要稍微处理一下我们的标签,并将它们合并到我们的训练集中。
type2id = {"clicks": 0, "carts": 1, "orders": 2}
train_labels = train_labels.explode('ground_truth').with_columns([pl.col('ground_truth').alias('aid'),pl.col('type').apply(lambda x: type2id[x])
])[['session', 'type', 'aid']]train_labels = train_labels.with_columns([pl.col('session').cast(pl.datatypes.Int32),pl.col('type').cast(pl.datatypes.UInt8),pl.col('aid').cast(pl.datatypes.Int32)
])train_labels = train_labels.with_column(pl.lit(1).alias('gt'))
train = train.join(train_labels, how='left', on=['session', 'type', 'aid']).with_column(pl.col('gt').fill_null(0))train.head()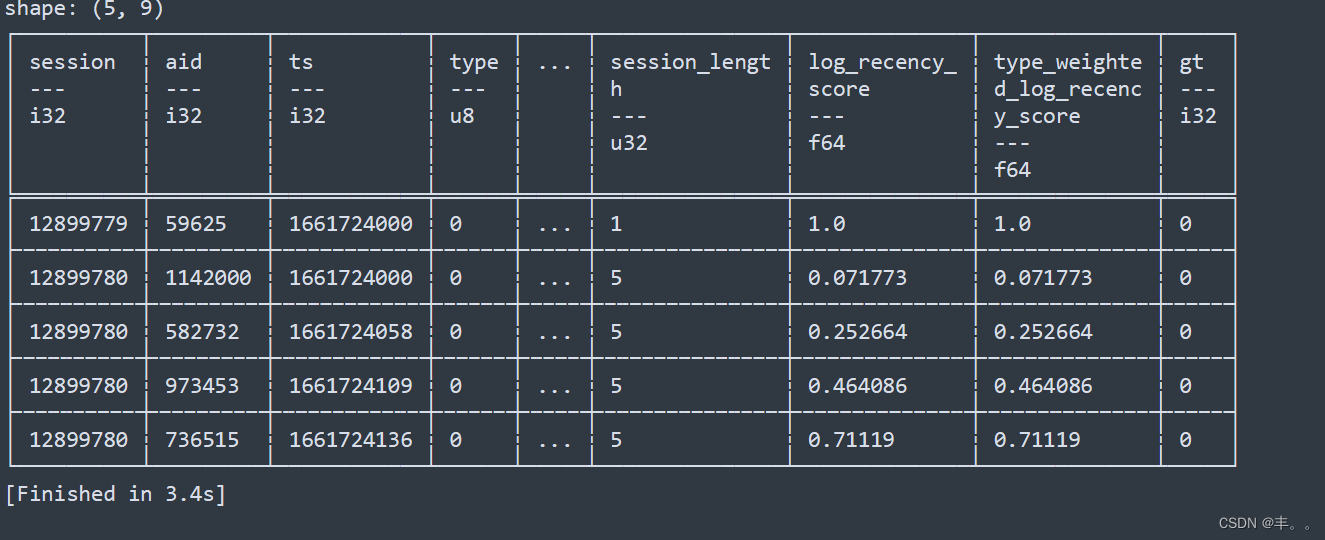
我们现在有了预处理的数据集,一个具有基本信息的列,这意味着我们的 Ranker 唯一缺少的是…如何将各个行分组到会话中的信息
def get_session_lenghts(df):return df.groupby('session').agg([pl.col('session').count().alias('session_length')])['session_length'].to_numpy()session_lengths_train = get_session_lenghts(train)
模型训练
from lightgbm.sklearn import LGBMRanker
ranker = LGBMRanker(objective="lambdarank",metric="ndcg",boosting_type="dart",n_estimators=20,importance_type='gain',
)train.columnsfeature_cols = ['aid', 'type', 'action_num_reverse_chrono', 'session_length', 'log_recency_score', 'type_weighted_log_recency_score']
target = 'gt'ranker = ranker.fit(train[feature_cols].to_pandas(),train[target].to_pandas(),group=session_lengths_train,
)
在测试数据上进行预测
test = pl.read_parquet('../input/otto-full-optimized-memory-footprint/test.parquet')
test = apply(test, pipeline)
scores = ranker.predict(test[feature_cols].to_pandas())创建提交版本的CSV文件
test = test.with_columns(pl.Series(name='score', values=scores))
test_predictions = test.sort(['session', 'score'], reverse=True).groupby('session').agg([pl.col('aid').limit(20).list()
])session_types = []
labels = []for session, preds in zip(test_predictions['session'].to_numpy(), test_predictions['aid'].to_numpy()):l = ' '.join(str(p) for p in preds)for session_type in ['clicks', 'carts', 'orders']:labels.append(l)session_types.append(f'{session}_{session_type}')
submission = pl.DataFrame({'session_type': session_types, 'labels': labels})
submission.write_csv('submission.csv')



![[机器学习] 模型融合GBDT(xgb/lgbm/rf)+LR 的原理及实践](https://img-blog.csdn.net/201810091707037?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Fuc2h1YWlfYXcx/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
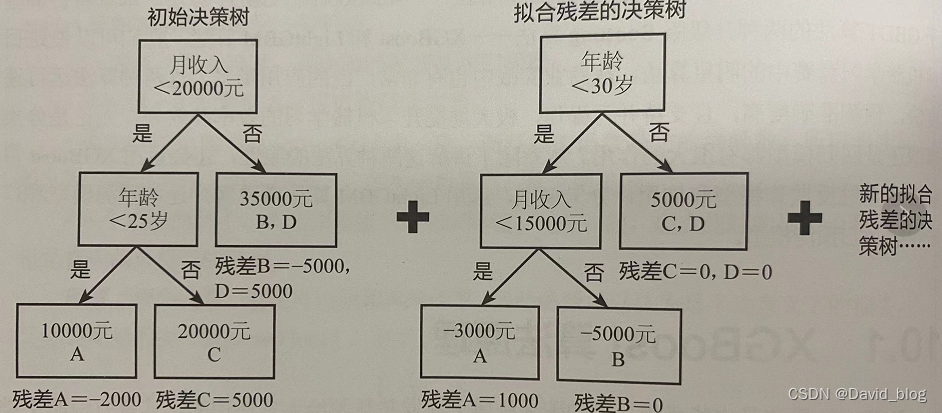

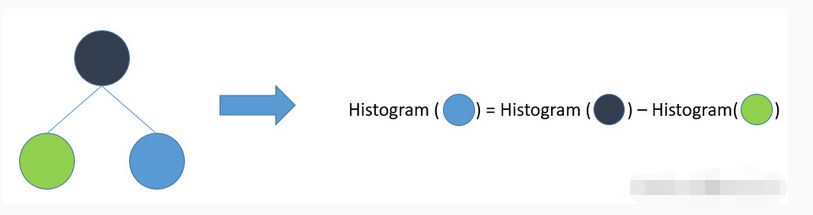

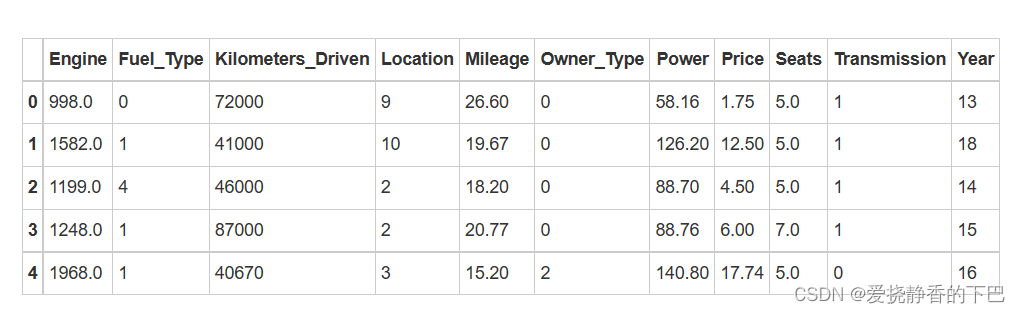

![[C++] OpenCasCade空间几何库的模型展现](https://img-blog.csdnimg.cn/20190104124903515.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzM4MTI1Mjc4,size_16,color_FFFFFF,t_70)