本文适合有集成学习与XGBoost基础的读者了解LightGBM算法。
序
LightGBM是基于XGBoost的改进版,在处理样本量大、特征纬度高的数据时,XGBoost效率和可扩展性也不够理想,因为其在对树节点分裂时,需要扫描每一个特征的每一个特征值来寻找最优切分点,耗时较大。而LightGBM则提出了GOSS(Gradient-based One-Side Sampling,基于梯度的单边采样)和EFB(Exclusive Feature Bundling,互斥特征捆绑)来分别进行样本采样和降低特征维度。同时,使用Histogram来加速寻找切分点。因此可以简单点说,可以简单点说,LightGBM = XGBoost + Histogram + GOSS + EFB。在此提一句,XGBoost原始版本使用pre-sorted的方法对每个特征根据特征值进行排序,下面将会对Histogram和GOSS、EFB分别介绍,并介绍Level-wise和Leaf-wise、离散特征的处理。
Histogram与pre-sorted比较
Pre-sorted方式无论在内存占用还是寻找最优切分点的时间效率上都不如Histogram算法。XGBoost原来也使用的Pre-sorted算法,但后来改成了Histogram。
内存占用比较
Pre-sorted方式是根据样本中所有特征的特征值进行排序,其形式为:维持一个原始数据样本矩阵,并对每一个特征分别保持一个排好序的索引,因此其所占内存空间为(2 * data_row * feature_num * 4Bytes)。需要注意的是,Pre-sorted方法是对每个特征维持排序后的索引,且同时要保留原始数据的值,而由于原始数据量较大,因此索引也需要4Byte来保存。
Histogram通过分bin的方式将特征离散化,比方说将(0, 0.3)映射到第0个桶,将(0.3, 0.6)映射到第1个桶。因而从此节点分裂与该特征的特征值无关(梯度的计算与特征的取值无关,只与特征对应的分类结果有关),而只与此次分裂后在左右子树的样本有关。因此Histogram所占用的内存为(data_row * feature_num * 1Byte),仅为pre-sorted算法的1/8,其中1Byte指该样本的该特征存在哪个桶中,而桶的数量往往远少于样本数量,因此若桶的数量在256个以内,即0-255,则只需1Byte即可存储。
计算效率比较
Pre-sorted需要对每一个特征的每一个取值都计算一次增益,因此时间需要(feature_num * distinct_value_of_the_feature)。
Histogram每个桶内所有样本只对应一个值,因此每次分裂是针对桶的,只需要(feature_num * bin_num)。
Cache-Miss问题
Pre-sorted还会存在cache-miss问题。其有两个操作频繁的地方会造成cache miss。
第一,是对梯度的访问。Pre-sorted算法在计算增益时需要利用梯度,而不同特征访问梯度的顺序不一样(它是通过索引的),且是随机的,因此该部分会造成严重的cache-miss。
第二,是与Level-wise的结合。Pre-sorted中每个样本都有一个编号对应了其属于哪一个叶子节点,而同一个level上的每个叶子节点都要切分数据,这也导致了cache-miss。
而Histogram算法,在生成直方图的过程中,已经统计好了直方图中每个bin的梯度,因此计算gain时直接对bin进行访问,可以将梯度连续存储,减小了cache-miss的情况。
Histogram的缺点
Histogram不能找到精确的切分点,训练误差不如pre-sorted。但是实验结果上Histogram效果不比pre-sorted差,因为较“粗”的切分点自带正则化的效果,而且boosting算法本身也是弱学习器的集成。
Histogram算法简介

- 对于所有的叶子节点(Leaf-wise),分别遍历所有的特征;
- 对每一个叶子的每个特征,生成一个直方图(Histogram);
- 【第三个for循环中】每个样本属于直方图的一个bin,统计这个bin里的一节梯度的和(代码中的g),和二阶梯度的和/样本个数(代码中的n。解释一下:上述代码是基于SSE损失函数而言的,该损失函数的二阶导数为1(其实是2,不过各乘以1/2不影响),故直接统计该bin内样本个数)。这里每个直方图的梯度都是连续存储的,可以一定程度上减轻cache-miss问题;
- 对该直方图中每一个bins,分别以该bin为划分点进行划分,计算loss(这里其实不叫loss,应该叫gain,即增益,增益最大的点作为切分点最好)(这个loss的计算公式其实和XGBoost一样,只不过令γ和λ都为0),这里用到了下面提到的加速小trick。
Loss计算
下图为XGBoost的Gain,上面的Loss也就是Gain的意思,去掉1/2,下面的GL对应SL,下面的HL对应nL,下面的λ和γ都设为0,则和LGBM一模一样。
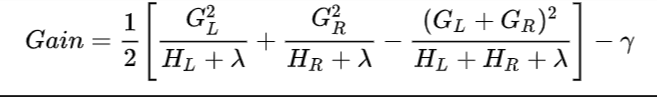
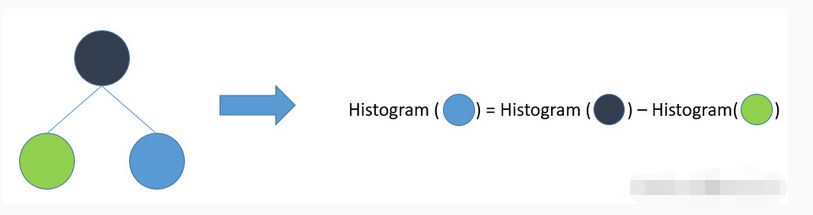
Histogram的加速小trick
可以通过用父节点的梯度减去兄弟节点的梯度计算该节点的梯度,可以节省一半的计算量。

Leaf-wise与Level-wise
大部分决策树通过level-wise生长树,即一次分裂全部同一层的叶子(类似广度遍历),而Leaf-wise则是同时考虑所有的叶子节点,从所有叶子节点中选取能带来最大增益的叶子进行分裂。LGBM采用的是Leaf-wise的方式。
Level-wise以相同的方式对待同一层的叶子,但实际上有些叶子的分裂增益较低可能已经没必要继续分裂了,继续分裂会增加不必要的开销。而Leaf-wise则每次都选最佳增益的叶子进行分裂,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差。但是Leaf-wise也更容易导致树的深度较深,这会导致过拟合。因此可以利用设置max_depth超参数来限制树的深度以避免过拟合。

GOSS (Gradient-based One-Side Sampling)
GOSS,基于梯度的单边采样,这是一种样本采样方法,减少样本量以加速叶子节点分裂时的增益的计算。该方法认为,梯度大的样本在信息增益的计算上更加重要,会贡献更多的信息增益(相当于AdaBoost中给样本加权重)。因此,GOSS提出保留全部梯度大的样本,而对梯度小的样本按比例进行随机采样。

GOSS简要算法描述
- 用前一个基学习器计算出来的每个样本的梯度进行降序排序(如果这是第一个基学习器,则预测值取平均或投票等),假设样本量共为len(I);
- 对排序后的样本,选取前a*len(I)个样本作为大梯度样本集;
- 对剩下(1-a)len(I)个样本,从中选取blen(I)个样本作为小梯度样本集;
- 将大梯度样本集和小梯度样本集合并作为此次GOSS采样的总样本集;
- 其中小梯度样本中每个样本需要乘以一个权重,权重为(1-a)/b;
- 使用上述思想不断迭代生成新的弱学习器,计算带权重的损失的思想类似AdaBoost,不断重复直至达到最大迭代次数或收敛为止。
GOSS对于类别特征的采样策略补充
对于类别特征,则每一个类别作为一个bin即可。对于那些类别特别多的类型(多到大于max_bin的限制),则会忽略那些包含的样本特别少的类别(默认max_bin为255,即够1Byte存储)。
EFB(Exclusive Feature Bundling)
EFB,互斥特征绑定。这是一个列采样(特征采样)方式。由于常用的数据往往维度较高且较稀疏(如one-hot编码的数据),因此考虑将互斥特征绑定在一起以减少特征维度。本方法提出了一种与Histogram的方法实现互斥特征的绑定。

将特征完全互斥地进行绑定是一个NP难问题,因此这里允许特征间存在一定少量的不互斥的样本,允许小部分的冲突以提高计算的有效性(所谓冲突,在我看来就是两个特征在样本中同时出现了非零值,就算冲突)。而方法很简单:
- 以特征为节点,构造一个无向带权图,权值为特征之间的总冲突;
- 根据特征的度降序排序特征;
- 依次检查每个特征,将其分配给具有小冲突的bundle(冲突的上限为提前设置的超参数)或者新建一个bundle。
上述算法在建立无向带权图的时间复杂度为 O ( n 2 ) O(n^2) O(n2),其中n为特征数。若特征数量过多,时间复杂度较高。因此作者也提出了一个按非零值排序的算法。
EFB合并互斥特征
上面讲了哪些特征可以被用于合并成一个bundle,那么该如何合并呢?
LGBM结合了Histogram来解决这个问题。Histogram将特征离散化为若干个bins,因而可以将需要合并的特征分布在不同的bins中,即可达到互不干扰的效果。而为实现这个效果,只需对特征的取值范围进行平移即可。
如下图为一个合并的例子,feature1的取值范围为0-4,因此将feature2的所有值加上4后进行合并(相加):

LGBM中类别特征的处理方式
对于类别特征,此前的GBDT、XGBoost等都用的是one-hot编码,即one vs rest,但是这种方法对于类别特别多的类别特征容易导致过拟合,会生成极不平衡树(GBDT和XGB没这个问题,但是Leaf-wise的LGBM会),并且会导致树会 比较深才能达到较好的效果(XGB也有这个问题)。而LGBM则提出不使用one vs rest,而是采用 many-vs-many的方式,即将分类变量划分为2个类别,若有k个类别,则一共有种 2 k − 1 − 1 2^{k-1}-1 2k−1−1分类方式。
关于 2 k − 1 − 1 2^{k-1}-1 2k−1−1的计算来由:一共k个类别,假使从中选0-k个样本,则每个样本有被选与不被选两种选择,即 2 k 2^k 2k种选项,而由于这种选择是非此即彼的,即abc全被选和全不被选是相同的,因此除以2,为 2 k − 1 2^{k-1} 2k−1,而又由于不能出现所有都不被选的情况,所以减一,为 2 k − 1 − 1 2^{k-1}-1 2k−1−1。
而实际上的many-vs-many分裂方式,在LGBM中,操作如下:
- 统计该特征上各取值的样本数,根据样本数从大到小排序,去除样本占比小于1%的类别值(因此在实际操作中对于特别稀疏的特征最好先进行尾部取值合并,否则会被算法自动抹除);
- 对于剩余的特征值(一个特征值一个bin),统计其统计量:(一阶导数和)的平方 / (二阶导数 + 正则化系数);
- 根据该统计量对桶从大到小排序;
- 在排序好的桶上,寻找最佳切分点,以这个顺序将特征分成左右两子树,得到many-vs-many的结果。而且LGBM还可以设置参数max_cat_threshold,其意为一个组中最多可存在多少个不同的特征值。
LGBM调参
下面介绍常用的LGBM可用的可以调的参数:
• bagging_fraction和bagging_freq:设置样本采样比例和频率,降低采样比例可以加快训练速率;
• feature_fraction:特征采样率,降低可提高训练速率;
• max_bin:最大桶数;
• learning_rate:学习率;
• num_iteration:训练轮数 = 基学习器的个数;
• num_leaves:叶子节点个数;
• min_data_in_leaf:叶子节点中包含的样本量少于这个量就不进行分裂;
• max_depth:控制树深度,避免过拟合;
参考资料
- https://www.bilibili.com/video/BV1JK4y1L7ow?from=search&seid=6048732175579034628
- https://medium.com/@pushkarmandot/https-medium-com-pushkarmandot-what-is-lightgbm-how-to-implement-it-how-to-fine-tune-the-parameters-60347819b7fc
- https://blog.csdn.net/xwnxf123go/article/details/110734731
- https://blog.csdn.net/anshuai_aw1/article/details/83040541
- https://blog.csdn.net/anshuai_aw1/article/details/83659932
- https://blog.csdn.net/qq_24519677/article/details/82811215
- https://www.jianshu.com/p/d07f0b0726da?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
- https://www.zhihu.com/question/386888889
- https://zhuanlan.zhihu.com/p/137847395
- https://blog.csdn.net/anshuai_aw1/article/details/83275299
- https://blog.csdn.net/gangyin5071/article/details/82591553
- https://www.pianshen.com/article/886263472/
- https://www.zhihu.com/question/51644470/answer/130946285
- https://lightgbm.readthedocs.io/en/latest/Features.html
- https://cloud.tencent.com/developer/article/1661208
- https://zhuanlan.zhihu.com/p/296607160
- https://blog.csdn.net/mingxiaod/article/details/86233309


![[C++] OpenCasCade空间几何库的模型展现](https://img-blog.csdnimg.cn/20190104124903515.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzM4MTI1Mjc4,size_16,color_FFFFFF,t_70)