1.视频教程:
B站、网易云课堂、腾讯课堂
2.代码地址:
Gitee
Github
3.存储地址:
Google云
百度云:
提取码:
DFN-Tensorflow版本
解释一下BorderNetWork是如何起作用的,是如何进行融合的,有问题,欢迎交流
1.先看损失函数
# -*- coding: utf-8 -*-import tensorflow as tfdef pw_softmaxwithloss_2d(y_true, y_pred):exp_pred = tf.exp(y_pred)try:sum_exp = tf.reduce_sum(exp_pred, 3, keepdims=True)except:sum_exp = tf.reduce_sum(exp_pred, 3, keep_dims=True)tensor_sum_exp = tf.tile(sum_exp, tf.stack([1, 1, 1, tf.shape(y_pred)[3]]))softmax_output = tf.div(exp_pred, tensor_sum_exp)ce = - tf.reduce_mean(y_true * tf.log(tf.clip_by_value(softmax_output, 1e-12, 1.0)))return softmax_output, cedef focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0):try:pk = tf.reduce_sum(y_true * y_pred, 3, keepdims=True)except:pk = tf.reduce_sum(y_true * y_pred, 3, keep_dims=True)fl = - alpha * tf.reduce_mean(tf.pow(1.0 - pk, gamma) * tf.log(tf.clip_by_value(pk, 1e-12, 1.0)))return fl
总共有两个损失函数def pw_softmaxwithloss_2d(y_true, y_pred)和def focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0)
# loss1
def pw_softmaxwithloss_2d(y_true, y_pred)
# loss2
def focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0)
2.看网络

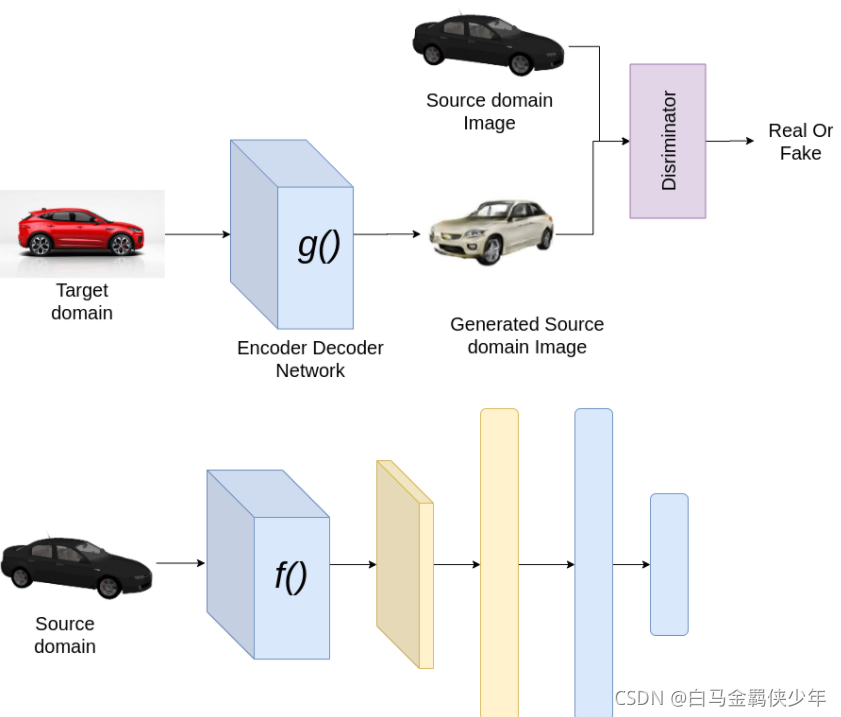
整个DFN网络分Border Network 和 Smooth Network两个子网络
Smooth Network网络用于图像分割,使用的是loss是pw_softmaxwithloss_2d(y_true, y_pred)
Border Network网络用于图像分割,使用的是loss是focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0)
这里我们从两个loss可以看到,Border Network 和 Smooth Network网络的输出一样的特征图y_pred
# 随机生成输入数据
image = torch.randn(1, 3, 512, 512)
# 定义网络
net = DFN(21)
net.eval()
# 前向传播
res1, res2 = net(image)
# 打印输出大小
print('-----'*5)
print(res1.size(), res2.size())
print('-----'*5)
然后两个子网络结合标签y_true计算出loss
下面是真正训练时候的loss设计
def loss(self):######### -*- Softmax Loss -*- #########self.softmax_b1, self.ce1 = pw_softmaxwithloss_2d(self.Y, self.b1)self.softmax_b2, self.ce2 = pw_softmaxwithloss_2d(self.Y, self.b2)self.softmax_b3, self.ce3 = pw_softmaxwithloss_2d(self.Y, self.b3)self.softmax_b4, self.ce4 = pw_softmaxwithloss_2d(self.Y, self.b4)self.softmax_fuse, self.cefuse = pw_softmaxwithloss_2d(self.Y, self.fuse)self.total_ce = self.ce1 + self.ce2 + self.ce3 + self.ce4 + self.cefuse######### -*- Focal Loss -*- #########self.fl = focal_loss(self.Y, self.o, alpha=self.alpha, gamma=self.gamma)######### -*- Total Loss -*- #########self.total_loss = self.total_ce + self.fl_weight * self.fl
可以看到
self.total_loss = self.total_ce + self.fl_weight * self.fl
所以这就是双网络融合,通过loss融合达到双网络的“融合”训练
使用focal loss监督Border Network的输出
Border Network,因为Border Network的网络设计更关注边界,所以叫Border Network
整体解释图

这里再做一个强调
def loss(self):######### -*- Softmax Loss -*- #########1.self.softmax_b1, self.ce1 = pw_softmaxwithloss_2d(self.Y, self.b1)2.self.softmax_b2, self.ce2 = pw_softmaxwithloss_2d(self.Y, self.b2)3.self.softmax_b3, self.ce3 = pw_softmaxwithloss_2d(self.Y, self.b3)4.self.softmax_b4, self.ce4 = pw_softmaxwithloss_2d(self.Y, self.b4)5.self.softmax_fuse, self.cefuse = pw_softmaxwithloss_2d(self.Y, self.fuse)6.self.total_ce = self.ce1 + self.ce2 + self.ce3 + self.ce4 + self.cefuse######### -*- Focal Loss -*- #########7.self.fl = focal_loss(self.Y, self.o, alpha=self.alpha, gamma=self.gamma)######### -*- Total Loss -*- #########self.total_loss = self.total_ce + self.fl_weight * self.fl看上图的loss,我们可以看到1-6行和第7行都是self.Y,所以两个子网络都是用的一样的标签(t_true)
- DFN-Model(pytorch版本)
- DFN-Tensorflow版本
- 1.一 论文导读
- 2.二 论文精读
- 3.三 代码实现
- 4.四 问题思索
- 5.五 实验参数设置
- 6.六 额外补充
《Learning a Discriminative Feature Network for Semantic Segmentation》
—待写
作者:Changqian Yu, etc
单位:华中科技大学&北京大学
发表会议及时间:CVPR 2018
Submission history
From: Changqian Yu [view email]
[v1] Wed, 25 Apr 2018 03:49:30 UTC (3,721 KB)
https://arxiv.org/abs/1804.09337
注意力机制通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。其中重要程度的判断取决于应用场景,具备注意力机制的神经网络可更好的进行自主学习。
注意力机制包含两个步骤:
1.注意力机制需要先决定整段输入的哪个部分需要更加关注
2.从关键的部分进行特征提取,得到重要的信息
按注意力的关注域,可分为:
空间域(spatial domain)
通道域(channel domain)
层域(layer domain)
混合域(mixed domain)
时间域(time domain)
注意力机制可以帮助模型为输入图像的各个部分分配不同的权重,提取更关键、更重要的信息,使模型能够做出更准确的判断,同时不会给模型的计算和存储带来更多的消耗。
- Abstract
Most existing methods of semantic segmentation still suffer from two aspects of challenges: intra-class inconsistency and inter-class indistinction. To tackle these two problems, we propose a Discriminative Feature Network (DFN), which contains two sub-networks: Smooth Network and Border Network. Specifically, to handle the intra-class inconsistency problem, we specially design a Smooth Network withChannel Attention Blockandglobal average poolingto select the more discriminative features. Furthermore, we propose aBorder Networkto make the bilateral features of boundary distinguishable with deep semantic boundary supervision. Based on our proposed DFN, we achieve state-of-the-art performance 86.2% mean IOU on PASCAL VOC 2012 and 80.3% mean IOU on Cityscapes dataset.
微观角度:每一个像素都对应一个具体类别
宏观角度:将语义分割看作一个任务,将一致的语义标签分配给一类事物,而不是每个像素。按照这一角度,语义分割中就会存在类间不一致和类内不一致的问题
宏观应用:以语义地图为例。交通信号灯在点云地图中,它们只是三维形状,有坐标位置、朝向或车道应用范围等信息,这些信息并不足以帮助自动驾驶车辆做出行驶决策,因为交通灯还可能有红灯或绿灯等各种状态。这时语义地图就能够发挥作用,它能够辅助车辆的感知和规划系统判定交通信号灯的状态,这就是语义地图与其他地图的区别所在
一 论文导读
Border Network
- 1.主要思想:利用多监督,使网络学习到的特征具有很强的类间不一致性。利用bottom-up结构,获取更多的语义信息
- 2.优点:该模块可以从低阶网络获得边界信息,从高阶网络获得语义信息,再融合,避免缺失某类信息的情况出现。高阶语义信息具有优化低阶边缘信息的作用
- 3.使用focal loss监督Border Network的输出。
二 论文精读
三 代码实现


损失


Boeder Network
- 1.主要思想:利用多监督,使网络学习到的特征具有很强的类间不一致性。利用bottom-up结构,获取更多的语义信息
- 2.优点:该模块可以从低阶网络获得边界信息,从高阶网络获得语义信息,再融合,避免缺失某类信息的情况出现。高阶语义信息具有优化低阶边缘信息的作用
- 3.使用focal loss 监督Border Network的输出
四 问题思索
五 实验参数设置
- 1.损失函数: loss = CrossEntropy +
λFocalLoss
λ={0.05, 0.1,0.5,0.75,1},论文结论λ =0.1时效果最好 - 2.优化器: SGD + momentum=0.9
- 3.学习率: 0. 0001(“poly",power=0. 9)
- 4.batchsize :32
- 5.数据预处理:mean subtraction, 随机水平翻转,{0. 5,0.75,1,1.5,1.75}比例缩放
六 额外补充
SLAM:同步定位与建图
SLAM (simultaneous localization and mapping),也称为CML (ConcurrentMapping and Localization),即时定位与地图构建,或并发建图与定位。问题可以描述为:将一个机器人放入未知环境中的未知位置,是否有办法让机器人一边移动一边逐步描绘出此环境完全的地图,所谓完全的地图(a consistent map)是指不受障碍行进到房间可进入的每个角落。SLAM的意义是实现机器人的自主定位和导航




![[Tensorflow2] 梯度反转层(GRL)与域对抗训练神经网络(DANN)的实现](https://img-blog.csdnimg.cn/932c68a898d44b0ea80bedd7d2b0bb2a.png)