知乎专栏链接:https://zhuanlan.zhihu.com/p/109057360
CSDN链接:https://daipuweiai.blog.csdn.net/article/details/104495520
前言
在前一篇文章【深度域适配】一、DANN与梯度反转层(GRL)详解中,我们主要讲解了DANN的网络架构与梯度反转层(GRL)的基本原理,接下来这篇文章中我们将主要复现DANN论文:Unsupervised Domain Adaptation by Backpropagation(文章链接:https://arxiv.org/abs/1409.7495)中MNIST和MNIST-M数据集的迁移训练实验。
该项目的github地址为:https://github.com/Daipuwei/DANN-MNIST
一、MNIST和MNIST-M介绍
为了利用DANN实现MNIST和MNIST-M数据集的迁移训练,我们首先需要获取到MNIST和MNIST-M数据集。其中MNIST数据集很容易获取,官网下载链接为:MNSIT。需要下载的文件如下图所示蓝色的4个文件。
同时MNSIT数据集的加载,tensorflow框架已经给出相关的读取接口,因此我们不需要自行编写,读取MNIST数据集的代码如下:
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets(os.path.abspath('./dataset/mnist'), one_hot=True)
# Process MNIST
mnist_train = (mnist.train.images > 0).reshape(55000, 28, 28, 1).astype(np.uint8) * 255
mnist_train = np.concatenate([mnist_train, mnist_train, mnist_train], 3)
mnist_test = (mnist.test.images > 0).reshape(10000, 28, 28, 1).astype(np.uint8) * 255
mnist_test = np.concatenate([mnist_test, mnist_test, mnist_test], 3)
MNIST-M数据集由MNIST数字与BSDS500数据集中的随机色块混合而成。那么要生成MNIST-M数据集,请首先下载BSDS500数据集。BSDS500数据集的官方下载地址为:BSDS500。以下是BSDS500数据集官方网址相关截图,点击下图中蓝框的连接即可下载数据。
下载好BSDS500数据集后,我们必须根据MNIST和BSDS500数据集来生成MNIST-M数据集,生成数据集的脚本create_mnistm.py如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport tarfile
import os
import pickle as pkl
import numpy as np
import skimage
import skimage.io
import skimage.transform
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./dataset/mnist')BST_PATH = os.path.abspath('./dataset/BSR_bsds500.tgz')rand = np.random.RandomState(42)f = tarfile.open(BST_PATH)
train_files = []
for name in f.getnames():if name.startswith('BSR/BSDS500/data/images/train/'):train_files.append(name)print('Loading BSR training images')
background_data = []
for name in train_files:try:fp = f.extractfile(name)bg_img = skimage.io.imread(fp)background_data.append(bg_img)except:continuedef compose_image(digit, background):"""Difference-blend a digit and a random patch from a background image."""w, h, _ = background.shapedw, dh, _ = digit.shapex = np.random.randint(0, w - dw)y = np.random.randint(0, h - dh)bg = background[x:x+dw, y:y+dh]return np.abs(bg - digit).astype(np.uint8)def mnist_to_img(x):"""Binarize MNIST digit and convert to RGB."""x = (x > 0).astype(np.float32)d = x.reshape([28, 28, 1]) * 255return np.concatenate([d, d, d], 2)def create_mnistm(X):"""Give an array of MNIST digits, blend random background patches tobuild the MNIST-M dataset as described inhttp://jmlr.org/papers/volume17/15-239/15-239.pdf"""X_ = np.zeros([X.shape[0], 28, 28, 3], np.uint8)for i in range(X.shape[0]):if i % 1000 == 0:print('Processing example', i)bg_img = rand.choice(background_data)d = mnist_to_img(X[i])d = compose_image(d, bg_img)X_[i] = dreturn X_print('Building train set...')
train = create_mnistm(mnist.train.images)
print('Building test set...')
test = create_mnistm(mnist.test.images)
print('Building validation set...')
valid = create_mnistm(mnist.validation.images)# Save dataset as pickle
mnistm_dir = os.path.abspath("./dataset/mnistm")
if not os.path.exists(mnistm_dir):os.mkdir(mnistm_dir)
with open(os.path.join(mnistm_dir,'mnistm_data.pkl'), 'wb') as f:pkl.dump({ 'train': train, 'test': test, 'valid': valid }, f, pkl.HIGHEST_PROTOCOL)
二、参数配置类config
由于整个DANN-MNIST网络的训练过程中涉及到很多超参数,因此为了整个项目的编程方便,我们利用面向对象的思想将所有的超参数放置到一个类中,即参数配置类config。这个参数配置类config的代码如下:
# -*- coding: utf-8 -*-
# @Time : 2020/2/15 15:05
# @Author : Dai PuWei
# @Email : 771830171@qq.com
# @File : config.py
# @Software: PyCharmimport osclass config(object):__defualt_dict__ = {"pre_model_path":None,"checkpoints_dir":os.path.abspath("./checkpoints"),"logs_dir":os.path.abspath("./logs"),"config_dir":os.path.abspath("./config"),"dataset_dir": os.path.abspath("./dataset"),#"dataset_dir": os.path.abspath("/input0"),"result_dir": os.path.abspath("./result"),"image_input_shape":(28,28,3),"image_size":28,"init_learning_rate": 1e-2,"momentum_rate": 0.9,"batch_size":64,"epoch":500,}def __init__(self,**kwargs):"""这是参数配置类的初始化函数:param kwargs: 参数字典"""# 初始化相关配置参数self.__dict__.update(self. __defualt_dict__)# 根据相关传入参数进行参数更新self.__dict__.update(kwargs)if not os.path.exists(self.checkpoints_dir):os.mkdir(self.checkpoints_dir)if not os.path.exists(self.logs_dir):os.mkdir(self.logs_dir)if not os.path.exists(self.result_dir):os.mkdir(self.result_dir)def set(self,**kwargs):"""这是参数配置的设置函数:param kwargs: 参数字典:return:"""# 根据相关传入参数进行参数更新self.__dict__.update(kwargs)def save_config(self,time):"""这是保存参数配置类的函数:param time: 时间点字符串:return:"""# 更新相关目录self.checkpoints_dir = os.path.join(self.checkpoints_dir,time)self.logs_dir = os.path.join(self.logs_dir,time)self.config_dir = os.path.join(self.config_dir,time)self.result_dir = os.path.join(self.result_dir,time)if not os.path.exists(self.config_dir):os.mkdir(self.config_dir)if not os.path.exists(self.checkpoints_dir):os.mkdir(self.checkpoints_dir)if not os.path.exists(self.logs_dir):os.mkdir(self.logs_dir)if not os.path.exists(self.result_dir):os.mkdir(self.result_dir)config_txt_path = os.path.join(self.config_dir,"config.txt")with open(config_txt_path,'a') as f:for key,value in self.__dict__.items():if key in ["checkpoints_dir","logs_dir","config_dir"]:value = os.path.join(value,time)s = key+": "+value+"\n"f.write(s)
三、梯度反转层(GradientReversalLayer)
在DANN中比较重要的模块就是梯度反转层(Gradient Reversal Layer, GRL)的实现。GRL的tf1.0代码实现如下:
# -*- coding: utf-8 -*-
# @Time : 2020/2/14 20:59
# @Author : Dai PuWei
# @Email : 771830171@qq.com
# @File : GRL.py
# @Software: PyCharmimport tensorflow as tf
from tensorflow.python.framework import opsclass GradientReversalLayer(object):def __init__(self):self.num_calls = 0def __call__(self, x, l=1.0):grad_name = "FlipGradient%d" % self.num_calls@ops.RegisterGradient(grad_name)def _flip_gradients(op, grad):return [tf.negative(grad) * l]g = tf.get_default_graph()with g.gradient_override_map({"Identity": grad_name}):y = tf.identity(x)self.num_calls += 1return y
在上述代码中@ops.RegisterGradient(grad_name)修饰 _flip_gradients(op, grad)函数,即自定义该层的梯度取反。同时gradient_override_map函数主要用于解决使用自己定义的函数方式来求梯度的问题,gradient_override_map函数的参数值为一个字典。即字典中value表示使用该值表示的函数代替key表示的函数进行梯度运算。
四、 DANN类代码
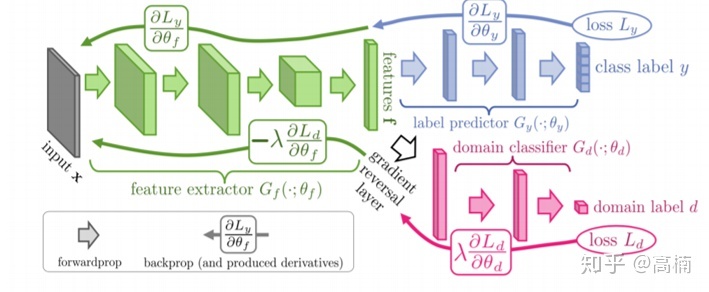
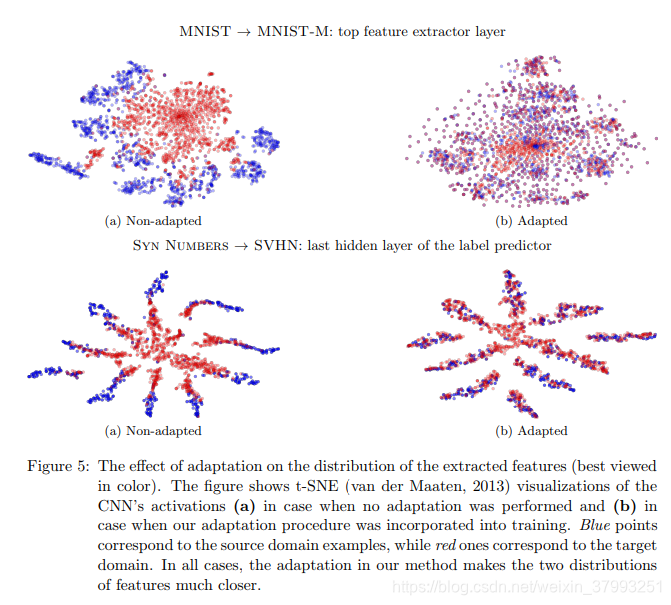
DANN论文Unsupervised Domain Adaptation by Backpropagation(文章链接为:https://arxiv.org/abs/1409.7495)中给出MNIST和MNIST-M数据集的迁移训练实验的网络,网络架构图如下图所示。
# -*- coding: utf-8 -*-
# @Time : 2020/2/14 20:27
# @Author : Dai PuWei
# @Email : 771830171@qq.com
# @File : MNIST2MNIST_M.py
# @Software: PyCharmimport os
import cv2
import datetime
import numpy as np
import tensorflow as tffrom tensorflow import keras as K
from tensorflow.train import MomentumOptimizerfrom utils.utils import plot_loss
from utils.utils import plot_accuracy
from utils.utils import AverageMeter
from utils.utils import make_summary
from utils.utils import grl_lambda_schedule
from utils.utils import learning_rate_schedulefrom model.GRL import GradientReversalLayer as GRLclass MNIST2MNIST_M_DANN(object):def __init__(self,config):"""这是MNINST与MNIST_M域适配网络的初始化函数:param config: 参数配置类"""# 初始化参数类self.cfg = config# 定义相关占位符self.grl_lambd = tf.placeholder(tf.float32, []) # GRL层参数self.learning_rate = tf.placeholder(tf.float32, []) # 学习率self.source_image_labels = tf.placeholder(tf.float32, shape=(None, 10))self.domain_labels = tf.placeholder(tf.float32, shape=(None, 2))# 搭建深度域适配网络self.build_DANN()# 定义损失self.image_cls_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.source_image_labels,logits=self.image_cls))self.domain_cls_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=self.domain_labels,logits=self.domain_cls))self.loss = self.image_cls_loss+self.domain_cls_loss# 定义精度correct_label_pred = tf.equal(tf.argmax(self.source_image_labels, 1), tf.argmax(self.image_cls, 1))self.acc = tf.reduce_mean(tf.cast(correct_label_pred, tf.float32))# 定义模型保存类与加载类self.saver_save = tf.train.Saver(max_to_keep=100) # 设置最大保存检测点个数为周期数# 初始化优化器self.global_step = tf.Variable(tf.constant(0), trainable=False)self.optimizer = MomentumOptimizer(self.learning_rate, momentum=self.cfg.momentum_rate)self.train_op = self.optimizer.minimize(self.loss,global_step=self.global_step)def featur_extractor(self,image_input,name):"""这是特征提取子网络的构建函数:param image_input: 图像输入张量:param name: 输出特征名称:return:"""x = K.layers.Conv2D(filters=32,kernel_size=5,kernel_initializer=K.initializers.TruncatedNormal(stddev=0.1),bias_initializer = K.initializers.Constant(value=0.1), activation='relu')(image_input)x = K.layers.MaxPool2D(pool_size=(2,2),strides=2)(x)x = K.layers.Conv2D(filters=48, kernel_size=5, kernel_initializer=K.initializers.TruncatedNormal(stddev=0.1),bias_initializer = K.initializers.Constant(value=0.1), activation='relu')(x)x = K.layers.MaxPool2D(pool_size=(2, 2),strides=2,name=name)(x)return xdef build_image_classify_model(self,image_classify_feature):"""这是搭建图像分类器模型的函数:param image_classify_feature: 图像分类特征张量:return:"""# 搭建图像分类器x = K.layers.Lambda(lambda x:x,name="image_classify_feature")(image_classify_feature)x = K.layers.Flatten()(x)x = K.layers.Dense(100,kernel_initializer=K.initializers.TruncatedNormal(stddev=0.1),bias_initializer = K.initializers.Constant(value=0.1), activation='relu')(x)#x = K.layers.Dropout(0.5)(x)x = K.layers.Dense(10,kernel_initializer=K.initializers.TruncatedNormal(stddev=0.1),bias_initializer = K.initializers.Constant(value=0.1), activation='softmax',name = "image_classify_pred")(x)return xdef build_domain_classify_model(self,domain_classify_feature):"""这是搭建域分类器的函数:param domain_classify_feature: 域分类特征张量:return:"""# 搭建域分类器x = GRL(domain_classify_feature,self.grl_lambd)x = K.layers.Flatten()(x)x = K.layers.Dense(100,kernel_initializer=K.initializers.TruncatedNormal(stddev=0.01),bias_initializer = K.initializers.Constant(value=0.1), activation='relu')(x)#x = K.layers.Dropout(0.5)(x)x = K.layers.Dense(2,kernel_initializer=K.initializers.TruncatedNormal(stddev=0.01),bias_initializer = K.initializers.Constant(value=0.1), activation='softmax',name="domain_classify_pred")(x)return xdef build_DANN(self):"""这是搭建域适配网络的函数:return:"""# 定义源域、目标域的图像输入和DANN模型图像输入self.source_image_input = K.layers.Input(shape=self.cfg.image_input_shape,name="source_image_input")self.target_image_input = K.layers.Input(shape=self.cfg.image_input_shape,name="target_image_input")self.image_input = K.layers.Concatenate(axis=0,name="image_input")([self.source_image_input,self.target_image_input])self.image_input = (self.image_input - self.cfg.pixel_mean) / 255.0# 域分类器与图像分类器的共享特征share_feature = self.featur_extractor(self.image_input,"image_feature")# 均等划分共享特征为源域数据特征与目标域数据特征source_feature,target_feature = \K.layers.Lambda(tf.split, arguments={'axis': 0, 'num_or_size_splits': 2})(share_feature)source_feature = K.layers.Lambda(lambda x:x,name="source_feature")(source_feature)# 获取图像分类结果和域分类结果张量self.image_cls = self.build_image_classify_model(source_feature)self.domain_cls = self.build_domain_classify_model(share_feature)def eval_on_val_dataset(self,sess,val_datagen,val_batch_num,ep):"""这是评估模型在验证集上的性能的函数:param val_datagen: 验证集数据集生成器:param val_batch_num: 验证集数据集批量个数"""epoch_loss_avg = AverageMeter()epoch_image_cls_loss_avg = AverageMeter()epoch_domain_cls_loss_avg = AverageMeter()epoch_accuracy = AverageMeter()for i in np.arange(1, val_batch_num + 1):# 获取小批量数据集及其图像标签与域标签batch_mnist_m_image_data, batch_mnist_m_labels = val_datagen.__next__()#val_datagen.next_batch()batch_domain_labels = np.tile([0., 1.], [self.cfg.batch_size * 2, 1])# 在验证阶段只利用目标域数据及其标签进行测试,计算模型在验证集上相关指标的值val_loss, val_image_cls_loss, val_domain_cls_loss, val_acc = \sess.run([self.loss, self.image_cls_loss, self.domain_cls_loss, self.acc],feed_dict={self.source_image_input: batch_mnist_m_image_data,self.target_image_input: batch_mnist_m_image_data,self.source_image_labels: batch_mnist_m_labels,self.domain_labels: batch_domain_labels})# 更新损失与精度的平均值epoch_loss_avg.update(val_loss, 1)epoch_image_cls_loss_avg.update(val_image_cls_loss, 1)epoch_domain_cls_loss_avg.update(val_domain_cls_loss, 1)epoch_accuracy.update(val_acc, 1)self.writer.add_summary(make_summary('val/val_loss', epoch_loss_avg.average),global_step=ep)self.writer.add_summary(make_summary('val/val_image_cls_loss', epoch_image_cls_loss_avg.average),global_step=ep)self.writer.add_summary(make_summary('val/val_domain_cls_loss', epoch_domain_cls_loss_avg.average),global_step=ep)self.writer.add_summary(make_summary('accuracy/val_accuracy', epoch_accuracy.average),global_step=ep)return epoch_loss_avg.average,epoch_image_cls_loss_avg.average,\epoch_domain_cls_loss_avg.average,epoch_accuracy.averagedef train(self,train_source_datagen,train_target_datagen,val_datagen,pixel_mean,interval,train_iter_num,val_iter_num,pre_model_path=None):"""这是DANN的训练函数:param train_source_datagen: 源域训练数据集生成器:param train_target_datagen: 目标域训练数据集生成器:param val_datagen: 验证数据集生成器:param interval: 验证间隔:param train_iter_num: 每个epoch的训练次数:param val_iter_num: 每次验证过程的验证次数:param pre_model_path: 预训练模型地址,与训练模型为ckpt文件,注意文件路径只需到.ckpt即可。"""# 初始化相关文件目录路径time = datetime.datetime.now().strftime("%Y%m%d%H%M%S")checkpoint_dir = os.path.join(self.cfg.checkpoints_dir,time)if not os.path.exists(checkpoint_dir):os.mkdir(checkpoint_dir)log_dir = os.path.join(self.cfg.logs_dir, time)if not os.path.exists(log_dir):os.mkdir(log_dir)result_dir = os.path.join(self.cfg.result_dir, time)if not os.path.exists(result_dir):os.mkdir(result_dir)self.cfg.save_config(time)# 初始化训练损失和精度数组train_loss_results = [] # 保存训练loss值train_image_cls_loss_results = [] # 保存训练图像分类loss值train_domain_cls_loss_results = [] # 保存训练域分类loss值train_accuracy_results = [] # 保存训练accuracy值# 初始化验证损失和精度数组,验证最大精度val_ep = []val_loss_results = [] # 保存验证loss值val_image_cls_loss_results = [] # 保存验证图像分类loss值val_domain_cls_loss_results = [] # 保存验证域分类loss值val_accuracy_results = [] # 保存验证accuracy值val_acc_max = 0 # 最大验证精度with tf.Session() as sess:# 初始化变量sess.run(tf.global_variables_initializer())# 加载预训练模型if pre_model_path is not None: # pre_model_path的地址写到.ckptsaver_restore = tf.train.import_meta_graph(pre_model_path+".meta")saver_restore.restore(sess,pre_model_path)print("restore model from : %s" % (pre_model_path))self.merged = tf.summary.merge_all()self.writer = tf.summary.FileWriter(log_dir, sess.graph)print('\n----------- start to train -----------\n')total_global_step = self.cfg.epoch * train_iter_numfor ep in np.arange(self.cfg.epoch):# 初始化每次迭代的训练损失与精度平均指标类epoch_loss_avg = AverageMeter()epoch_image_cls_loss_avg = AverageMeter()epoch_domain_cls_loss_avg = AverageMeter()epoch_accuracy = AverageMeter()# 初始化精度条progbar = K.utils.Progbar(train_iter_num)print('Epoch {}/{}'.format(ep+1, self.cfg.epoch))batch_domain_labels = np.vstack([np.tile([1., 0.], [self.cfg.batch_size // 2, 1]),np.tile([0., 1.], [self.cfg.batch_size // 2, 1])])for i in np.arange(1,train_iter_num+1):# 获取小批量数据集及其图像标签与域标签batch_mnist_image_data, batch_mnist_labels = train_source_datagen.__next__()#train_source_datagen.next_batch()batch_mnist_m_image_data, batch_mnist_m_labels = train_target_datagen.__next__()#train_target_datagen.next_batch()# 计算学习率和GRL层的参数lambdaglobal_step = (ep-1)*train_iter_num + iprocess = global_step * 1.0 / total_global_stepleanring_rate = learning_rate_schedule(process,self.cfg.init_learning_rate)grl_lambda = grl_lambda_schedule(process)# 前向传播,计算损失及其梯度op,train_loss,train_image_cls_loss,train_domain_cls_loss,train_acc = \sess.run([self.train_op,self.loss,self.image_cls_loss,self.domain_cls_loss,self.acc],feed_dict={self.source_image_input:batch_mnist_image_data,self.target_image_input:batch_mnist_m_image_data,self.source_image_labels:batch_mnist_labels,self.domain_labels:batch_domain_labels,self.learning_rate:leanring_rate,self.grl_lambd:grl_lambda})self.writer.add_summary(make_summary('learning_rate', leanring_rate),global_step=global_step)self.writer1.add_summary(make_summary('learning_rate', leanring_rate), global_step=global_step)# 更新训练损失与训练精度epoch_loss_avg.update(train_loss,1)epoch_image_cls_loss_avg.update(train_image_cls_loss,1)epoch_domain_cls_loss_avg.update(train_domain_cls_loss,1)epoch_accuracy.update(train_acc,1)# 更新进度条progbar.update(i, [('train_image_cls_loss', train_image_cls_loss),('train_domain_cls_loss', train_domain_cls_loss),('train_loss', train_loss),("train_acc",train_acc)])# 保存相关损失与精度值,可用于可视化train_loss_results.append(epoch_loss_avg.average)train_image_cls_loss_results.append(epoch_image_cls_loss_avg.average)train_domain_cls_loss_results.append(epoch_domain_cls_loss_avg.average)train_accuracy_results.append(epoch_accuracy.average)self.writer.add_summary(make_summary('train/train_loss', epoch_loss_avg.average),global_step=ep+1)self.writer.add_summary(make_summary('train/train_image_cls_loss', epoch_image_cls_loss_avg.average),global_step=ep+1)self.writer.add_summary(make_summary('train/train_domain_cls_loss', epoch_domain_cls_loss_avg.average),global_step=ep+1)self.writer.add_summary(make_summary('accuracy/train_accuracy', epoch_accuracy.average),global_step=ep+1)if (ep+1) % interval == 0:# 评估模型在验证集上的性能val_ep.append(ep)val_loss, val_image_cls_loss,val_domain_cls_loss, \val_accuracy = self.eval_on_val_dataset(sess,val_datagen,val_iter_num,ep+1)val_loss_results.append(val_loss)val_image_cls_loss_results.append(val_image_cls_loss)val_domain_cls_loss_results.append(val_domain_cls_loss)val_accuracy_results.append(val_accuracy)str = "Epoch {:03d}: val_image_cls_loss: {:.3f}, val_domain_cls_loss: {:.3f}, val_loss: {:.3f}" \", val_accuracy: {:.3%}".format(ep+1,val_image_cls_loss,val_domain_cls_loss,val_loss,val_accuracy)print(str)if val_accuracy > val_acc_max: # 验证精度达到当前最大,保存模型val_acc_max = val_accuracyself.saver_save.save(sess,os.path.join(checkpoint_dir,str+".ckpt"))# 保存训练与验证结果path = os.path.join(result_dir, "train_loss.jpg")plot_loss(np.arange(1,len(train_loss_results)+1), [np.array(train_loss_results),np.array(train_image_cls_loss_results),np.array(train_domain_cls_loss_results)],path, "train")path = os.path.join(result_dir, "val_loss.jpg")plot_loss(np.array(val_ep)+1, [np.array(val_loss_results),np.array(val_image_cls_loss_results),np.array(val_domain_cls_loss_results)],path, "val")train_acc = np.array(train_accuracy_results)[np.array(val_ep)]path = os.path.join(result_dir, "accuracy.jpg")plot_accuracy(np.array(val_ep)+1, [train_acc, val_accuracy_results], path)# 保存最终的模型model_path = os.path.join(checkpoint_dir,"trained_model.ckpt")self.saver_save.save(sess,model_path)print("Train model finshed. The model is saved in : ", model_path)print('\n----------- end to train -----------\n')def test_image(self,image_path,model_path):"""这是测试一张图像的函数:param image_path: 图像路径:param model_path: 模型路径:return:"""# 读取图像数据,并进行数组维度扩充image = cv2.imread(image_path)image = np.expand_dims(image,axis=0)image = (image - self.cfg.val_image_mean) / 255.0with tf.Session() as sess:# 初始化变量sess.run(tf.global_variables_initializer())# 加载预训练模型saver_restore = tf.train.import_meta_graph(model_path+".meta")saver_restore.restore(sess, model_path)# 进行测试img_cls_pred = sess.run([self.image_cls],feed_dict={self.source_image_input: image})pred_label = np.argmax(img_cls_pred[0])+1print("%s is %d" %(image_path,pred_label))def test_batch_images(self, image_paths, model_path):"""这是测试一张图像的函数:param image_paths: 图像路径数组:param model_path: 模型路径:return:"""# 批量读取图像数据images = np.array([cv2.imread(image_path) for image_path in image_paths])images = (images - self.cfg.val_image_mean) / 255.0with tf.Session() as sess:# 初始化变量sess.run(tf.global_variables_initializer())# 加载预训练模型saver_restore = tf.train.import_meta_graph(model_path+".meta")saver_restore.restore(sess, model_path)# 进行测试img_cls_pred = sess.run([self.image_cls], feed_dict={self.source_image_input: images})pred_label = np.argmax(img_cls_pred,axis=0) + 1for i,image_path in enumerate(image_paths):print("%s is %d" % (image_path, pred_label[i]))
五、工具脚本utilis
在训练过程中,需要各种小工具函数来辅助训练过程。例如学习率、GRL参数是根据迭代进程变化,数据集生成器的定义和各种结果绘制函数。工具脚本utilis.py如下:
# -*- coding: utf-8 -*-
# @Time : 2020/2/15 16:10
# @Author : Dai PuWei
# @Email : 771830171@qq.com
# @File : utils.py
# @Software: PyCharmimport numpy as np
import matplotlib.pyplot as plt
from tensorflow.core.framework import summary_pb2class AverageMeter(object):def __init__(self):self.reset()def reset(self):self.val = 0self.average = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.average = self.sum / float(self.count)def make_summary(name, val):return summary_pb2.Summary(value=[summary_pb2.Summary.Value(tag=name, simple_value=val)])def plot_accuracy(x,y,path):"""这是绘制精度的函数:param x: x坐标数组:param y: y坐标数组:param path: 结果保存地址:param mode: 模式,“train”代表训练损失,“val”为验证损失"""lengend_array = ["train_acc", "val_acc"]train_accuracy,val_accuracy = yplt.plot(x, train_accuracy, 'r-')plt.plot(x, val_accuracy, 'b--')plt.grid(True)plt.xlim(0, x[-1]+2)plt.xlabel("epoch")plt.ylabel("accuracy")plt.legend(lengend_array,loc="best")plt.savefig(path)plt.close()def plot_loss(x,y,path,mode="train"):"""这是绘制损失的函数:param x: x坐标数组:param y: y坐标数组:param path: 结果保存地址:param mode: 模式,“train”代表训练损失,“val”为验证损失"""if mode == "train":lengend_array = ["train_loss","train_image_cls_loss","train_domain_cls_loss"]else:lengend_array = ["val_loss", "val_image_cls_loss", "val_domain_cls_loss"]loss_results,image_cls_loss_results,domain_cls_loss_results = yloss_results_min = np.max([np.min(loss_results) - 0.1,0])image_cls_loss_results_min = np.max([np.min(image_cls_loss_results) - 0.1,0])domain_cls_loss_results_min =np.max([np.min(domain_cls_loss_results) - 0.1,0])y_min = np.min([loss_results_min,image_cls_loss_results_min,domain_cls_loss_results_min])plt.plot(x, loss_results, 'r-')plt.plot(x, image_cls_loss_results, 'b--')plt.plot(x, domain_cls_loss_results, 'g-.')plt.grid(True)plt.xlabel("epoch")plt.ylabel("loss")plt.xlim(0,x[-1]+2)plt.ylim(ymin=y_min)plt.legend(lengend_array,loc="best")plt.savefig(path)plt.close()def shuffle_aligned_list(data):"""这是是随机打乱数据的函数:param data: 输入数据:return:"""num = data[0].shape[0]p = np.random.permutation(num)return [d[p] for d in data]def batch_generator(data, batch_size, shuffle=True):"""这是构造数据生成器的函数:param data: 输入:param batch_size: 小批量大小:param shuffle: 是否打乱随机数据集的标志:return:"""if shuffle: # 随机打乱数据集标志为True,则随机打乱数据集data = shuffle_aligned_list(data)batch_count = 0 # 小批量数据集批次计数器while True:# 遍历完整个数据集,全部重置if batch_count * batch_size + batch_size >= len(data[0]):batch_count = 0if shuffle: # 随机打乱数据集标志为True,则随机打乱数据集data = shuffle_aligned_list(data)# 构造小批量数据集start = batch_count * batch_sizeend = start + batch_sizebatch_count += 1yield [d[start:end] for d in data] # 构造数据生成器def learning_rate_schedule(process,init_learning_rate = 0.01,alpha = 10.0 , beta = 0.75):"""这个学习率的变换函数:param process: 训练进程比率,值在0-1之间:param init_learning_rate: 初始学习率,默认为0.01:param alpha: 参数alpha,默认为10:param beta: 参数beta,默认为0.75"""return init_learning_rate /(1.0 + alpha * process)**betadef grl_lambda_schedule(process,gamma=10.0):"""这是GRL的参数lambda的变换函数:param process: 训练进程比率,值在0-1之间:param gamma: 参数gamma,默认为10"""return 2.0 / (1.0+np.exp(-gamma*process)) - 1.0
六、训练过程与实验结果
最后是训练DANN的脚本train.py,代码如下:
# -*- coding: utf-8 -*-
# @Time : 2020/2/15 16:36
# @Author : Dai PuWei
# @Email : 771830171@qq.com
# @File : train.py
# @Software: PyCharmimport os
import numpy as np
import pickle as pklfrom config.config import config
from model.MNIST2MNIST_M import MNIST2MNIST_M_DANN
from tensorflow.examples.tutorials.mnist import input_data
from utils.utils import batch_generatordef run_main():"""这是主函数"""# 初始化参数配置类cfg = config()mnist = input_data.read_data_sets(os.path.abspath('./dataset/mnist'), one_hot=True)# Process MNISTmnist_train = (mnist.train.images > 0).reshape(55000, 28, 28, 1).astype(np.uint8) * 255mnist_train = np.concatenate([mnist_train, mnist_train, mnist_train], 3)mnist_test = (mnist.test.images > 0).reshape(10000, 28, 28, 1).astype(np.uint8) * 255mnist_test = np.concatenate([mnist_test, mnist_test, mnist_test], 3)# Load MNIST-Mmnistm = pkl.load(open(os.path.abspath('./dataset/mnistm/mnistm_data.pkl'), 'rb'))mnistm_train = mnistm['train']mnistm_test = mnistm['test']mnistm_valid = mnistm['valid']# Compute pixel mean for normalizing datapixel_mean = np.vstack([mnist_train, mnistm_train]).mean((0, 1, 2))cfg.set(pixel_mean = pixel_mean)# 构造数据生成器train_source_datagen = batch_generator([mnist_train,mnist.train.labels],cfg.batch_size // 2)train_target_datagen = batch_generator([mnistm_train,mnist.train.labels],cfg.batch_size // 2)val_datagen = batch_generator([mnistm_test,mnist.test.labels],cfg.batch_size)# 初始化每个epoch的训练次数和每次验证过程的验证次数train_source_batch_num = int(len(mnist_train) // (cfg.batch_size // 2))train_target_batch_num = int(len(mnistm_train) // (cfg.batch_size // 2))train_iter_num = int(np.max([train_source_batch_num,train_target_batch_num]))val_iter_num = int(len(mnistm_test) / cfg.batch_size)# 初始化相关参数interval = 2 # 验证间隔train_num = len(mnist_train) + len(mnistm_train)# 训练集样本数val_num = len(mnistm_test) # 验证集样本数print("train on %d training samples with batch_size %d ,validation on %d val samples"% (train_num, cfg.batch_size, val_num))# 初始化DANN,并进行训练dann = MNIST2MNIST_M_DANN(cfg)#pre_model_path = os.path.abspath("./pre_model/trained_model.ckpt")pre_model_path = Nonedann.train(train_source_datagen,train_target_datagen,val_datagen,pixel_mean,interval,train_iter_num,val_iter_num,pre_model_path)if __name__ == '__main__':run_main()
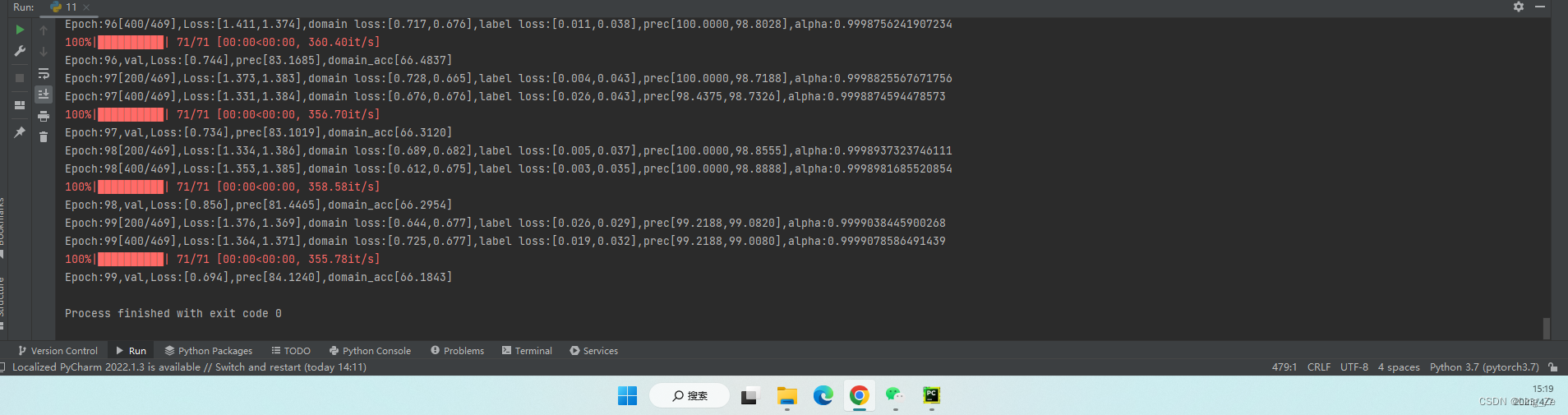
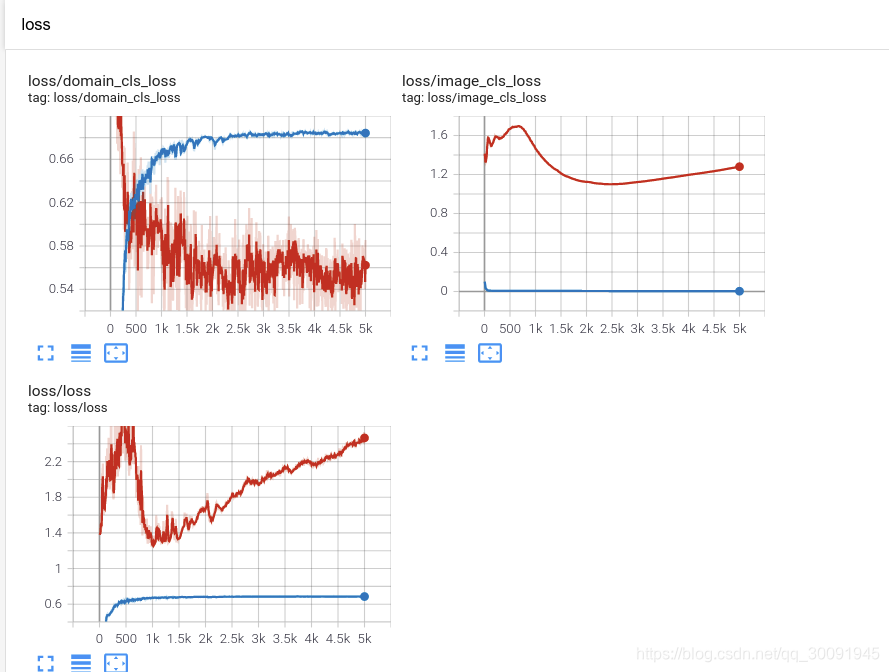
下面是训练过程中的相关tensorboard的相关指标在训练过程中的走势图。首先是训练误差的走势图,主要包括训练域分类误差、训练图像分类误差和训练总误差。
接下来是验证误差的走势图,主要包括验证域分类误差、验证图像分类误差和验证总误差。
然后是训练过程中学习率的走势图
最后是精度走势图,主要包括训练精度和测试精度。 其中训练精度是在源域数据集即MNIST数据集上的统计结果,验证精度是在目标域数据集即MNIST-M数据集上的统计结果。从图中可以看出,DANN在训练MNIST-M数据集时没有使用对应的标签,MNSIT-M数据集上的精度最终收敛到75.4%,效果相比于81.49%还有一定距离,但鉴于没有使用任何数据增强和dropout,这个结果可以接受。
公众号近期荐读:
GAN整整6年了!是时候要来捋捋了!
新手指南综述 | GAN模型太多,不知道选哪儿个?
数百篇GAN论文已下载好!搭配一份生成对抗网络最新综述!
有点夸张、有点扭曲!速览这些GAN如何夸张漫画化人脸!
天降斯雨,于我却无!GAN用于去雨如何?
脸部转正!GAN能否让侧颜杀手、小猪佩奇真容无处遁形?
容颜渐失!GAN来预测?
强数据所难!SSL(半监督学习)结合GAN如何?
弱水三千,只取你标!AL(主动学习)结合GAN如何?
异常检测,GAN如何gan ?
虚拟换衣!速览这几篇最新论文咋做的!
脸部妆容迁移!速览几篇用GAN来做的论文
【1】GAN在医学图像上的生成,今如何?
01-GAN公式简明原理之铁甲小宝篇
GAN&CV交流群,无论小白还是大佬,诚挚邀您加入!
一起讨论交流!长按备注【进群】加入:
更多分享、长按关注本公众号:




![[Tensorflow2] 梯度反转层(GRL)与域对抗训练神经网络(DANN)的实现](https://img-blog.csdnimg.cn/932c68a898d44b0ea80bedd7d2b0bb2a.png)