DANN
- Domain-Adversarial Training of Neural Networks in Tensorflow
- 域适配:目标域与源域的数据分布不同但任务相同下的迁移学习。
模型建立
-
DANN假设有两种数据分布:源域数据分布 S ( x , y ) \mathcal{S}(x,y) S(x,y)和目标域数据分布 T ( x , y ) \mathcal{T}(x,y) T(x,y);定义 d i d_i di为第 i i i个训练样本的域标签, d i ∈ { 0 , 1 } d_i\in\{0,1\} di∈{0,1},若 d i = 0 d_i=0 di=0,则 x i ∼ S ( x ) x_i\sim\mathcal{S}(x) xi∼S(x),反之 d i = 1 d_i=1 di=1, x i ∼ T ( x ) x_i\sim\mathcal{T}(x) xi∼T(x)
-
DANN网络的输入 x ∈ X x\in X x∈X, X X X表示图像输入空间;图像分类标签 y ∈ Y y\in Y y∈Y,其中 Y ( Y = { 1 , 2 , 3 , . . . , k } ) Y(Y=\{1,2,3,...,k\}) Y(Y={1,2,3,...,k})表示图像分类标签空间。在输入中,既有带标签的源域数据集也有不带标签的目标域数据集。
-
DANN的目标:准确预测目标域输入图像的分类标签
-
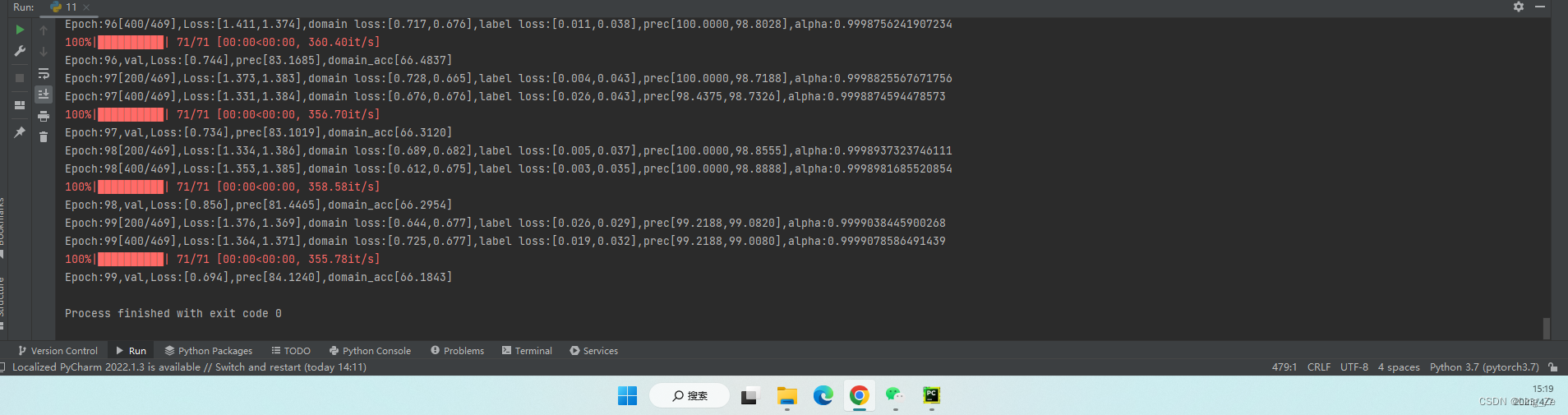
DANN网络构架:

绿色部分:特征提取网络;蓝色部分:图像分类网络;(绿蓝一起构成标准前馈结构)红色部分:域分类网络-
输入 x x x在训练阶段首先经过特征提取网络 f = G f ( x ; θ y ) f=G_f(x;\theta_y) f=Gf(x;θy)的映射转换为一个 D D D维特征向量。
-
分支1:图像分类预测网络 G y ( x ; θ y ) G_y(x;\theta_y) Gy(x;θy)
源域数据对应的特征向量通过预测网络获得对应分类标签预测结果。
-
分支2:域分类网络 G d ( x ; θ d ) G_d(x;\theta_d) Gd(x;θd)
源域和目标域输入对应的特征向量经过域分类网络得到每个输入的域分类结果。
-
-
-
为了实现让DANN将目标域数据看成源域数据,在训练阶段需实现两个任务:
- 源域数据及准确分类,即分类误差最小化
- 混淆源域数据集和目标数据集,实现域分类误差最大化。
由于域分类器与图像分类器的输入都来自于特征提取网络,但分别要求分类损失最小化和最大化。
如果使用随机梯度下降法(SGD)来优化模型损失函数的,会导致特征提取器在进行参数更新时,域分类损失和分类预测损失梯度相反。
- DANN提出了新的梯度反转层(Gradient Reversal Layer,GRL),使得在反向传播的过程中梯度方向自动取反,在前向传播过程中只做恒等变换:
R λ ( x ) = x d R λ d x = − λ I \begin{gathered}R_\lambda(x)=x\\\frac{dR_{\lambda}}{dx}=-\lambda I\end{gathered} Rλ(x)=xdxdRλ=−λI
- 梯度反转层被插在特征提取层和与分类器之间,则在反向传播的过程中,域分类器的域分类损失的梯度反向传播到特征提取器之前会自动取反( λ \lambda λ随迭代次数动态变化)
论文:Unsupervised Domain Adaptation by Backpropagation
参考博客:【深度域适配】一、DANN与梯度反转层(GRL)详解
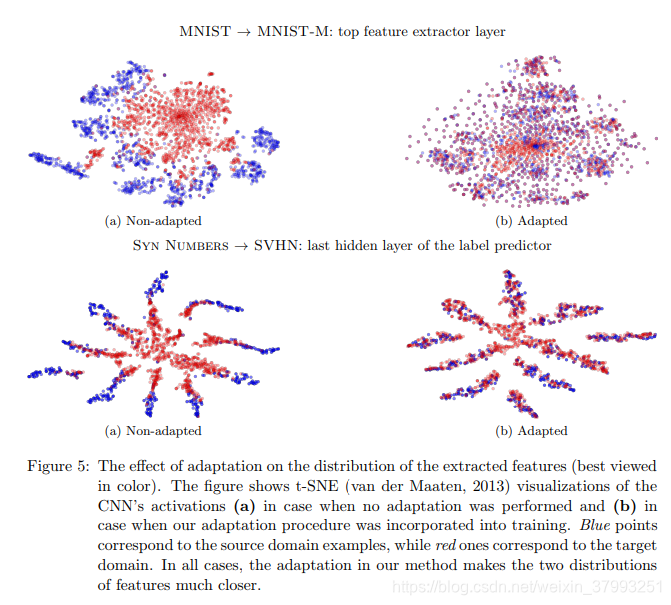
实验:MNIST域与MNIST-M域间的迁移学习
github传送门:https://github.com/pumpikano/tf-dann
运行环境
- tensorflow >=1.0
- Python 3.4
库
- numpy
- scikit-image
- matplotlib
- scikit-learn
- jupyter
- scipy
实验数据
-
MNIST作为源域,MNIST-M作为目标域。
MNIST-M为将从BSDS的彩色照片中随机抽取的原始集合上的数字随机混合到MNIST的patch上——与原始数据及相比,背景和笔画不再恒定,域相当不同,但输出图片对人类来说仍看可区分出数字。
-
样本均为28*28*3的图片,3代表RGB值


![[Tensorflow2] 梯度反转层(GRL)与域对抗训练神经网络(DANN)的实现](https://img-blog.csdnimg.cn/932c68a898d44b0ea80bedd7d2b0bb2a.png)