1.摘要
本文提出了一个简单的神经网络模型来处理目标识别中的域适应问题。该模型将最大均值差异(MMD)度量作为监督学习中的正则化来减少源域和目标域之间的分布差异。从实验中,本文证明了MMD正则化是一种有效的工具,可以为特定图像数据集的SURF特征建立良好的域适应模型。本文代表了在神经网络背景下对MMD度量的初次研究。
2.研究背景及意义
在基于机器学习算法的计算机视觉中,训练样本与测试样本之间的分布存在差异是真实场景下的基本问题。例如,假设本文有一个从包含具有特定视角、背景和变换条件的目标的训练集中学习的目标识别器;然后将其应用于具有类似目标的环境,但其具有不同的视角、背景和变换条件。由于缺乏表示新目标环境的标签数据或者与目标有关的知识不足。如果使用传统学习方法进行训练,则无法保证可以准确的识别,这是因为其不满足机器学习训练集和测试集独立同分布的假设条件。解决领域间分布差异的方法即为迁移学习。迁移学习按照属性集是否相同进行划分,分为同构迁移和异构迁移,则本文所研究的域适应就是同构,即源域和目标域的属性集相同。
域适应问题描述:假设给定一个训练集和测试集分别从分布Ds和Dt中采样,任务目标是关于yt的信息不足,当Ds!= Dt时预测此目标标签yt。
在图像识别中,Office数据集已成为评估域适应模型性能的标准图像集。这个数据集的标准评估协议是基于使用SURF特征描述符作为模型的输入。但是,使用这种描述符通常需要人工仔细设计才能获得良好的判别特征。因此,它可能会在实时特征提取过程中带来更多的复杂性,所以本文使用可自动提取特征的神经网络模型。
在深度学习中,经常在训练模型之前进行利用ImageNet训练参数进行预训练,其对于深度神经网络的成功发挥了重要作用。但是,其并不能解决分布存在差异的问题。
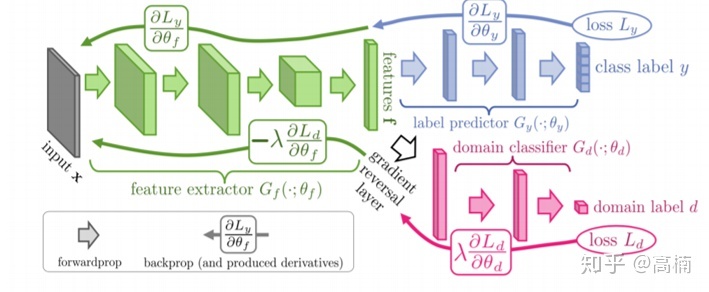
本文提出了一个简单的神经网络域适应模型,利用非参数概率分布距离度量,即最大平均差异(MMD)作为嵌入在监督反向传播训练中的正则化。MMD用于减少由从不同域抽取的样本导致的两个隐藏层之间的分布。本文是当前首次在神经网络中使用MMD。具体而言,本文将研究MMD正则化是否可以提高神经网络的域适应性能。
3.算法框架
3.1最大均值差异度量
最大平均差异(MMD)是来自其样本的两个概率分布之间差异的度量。给定数据集X上的两个概率分布p和q,MMD被定义为:
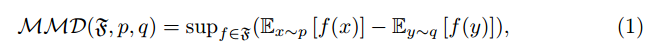
![[Tensorflow2] 梯度反转层(GRL)与域对抗训练神经网络(DANN)的实现](https://img-blog.csdnimg.cn/932c68a898d44b0ea80bedd7d2b0bb2a.png)