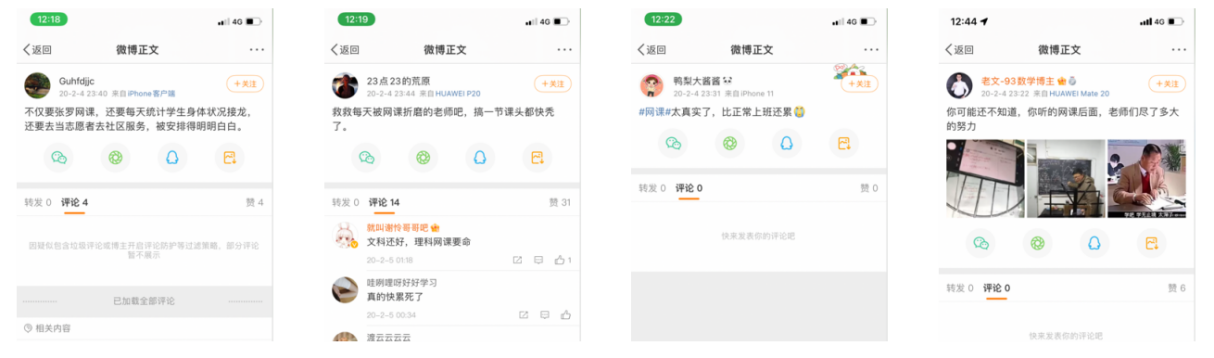
单高斯分布 MLE
posterior 正比例于 likelihood * prior
p ( θ ∣ x ) ∝ p ( x ∣ θ ) ∗ p ( θ ) p(\theta | x) \propto p(x|\theta) * p(\theta) p(θ∣x)∝p(x∣θ)∗p(θ)
参数 θ 的后验分布 ∝ 参数 θ 表示的 x 分布上已知样本有多大概率 ∗ 参数 θ 的先验分布 参数\theta的后验分布 \propto 参数\theta表示的x分布上已知样本有多大概率 * 参数\theta的先验分布 参数θ的后验分布∝参数θ表示的x分布上已知样本有多大概率∗参数θ的先验分布
参数的后验 ∝ 样本的 l i k e l i h o o d ∗ 参数的先验 参数的后验 \propto 样本的likelihood * 参数的先验 参数的后验∝样本的likelihood∗参数的先验
MLE : max log_likelihood estimator
MAP: max a posterior
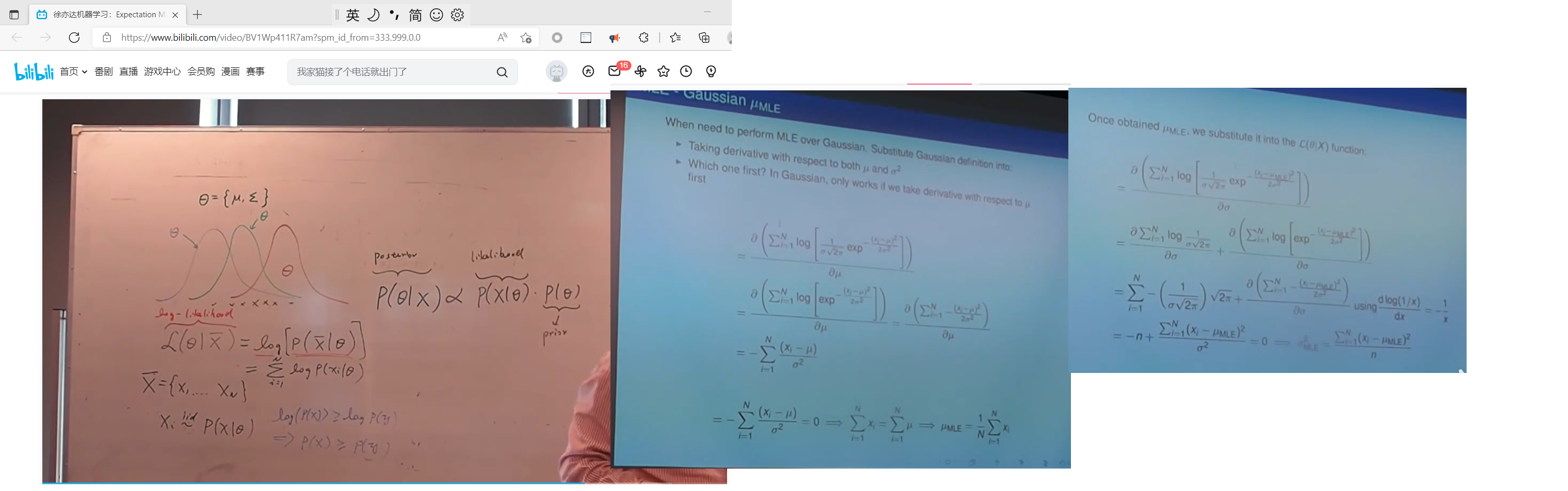
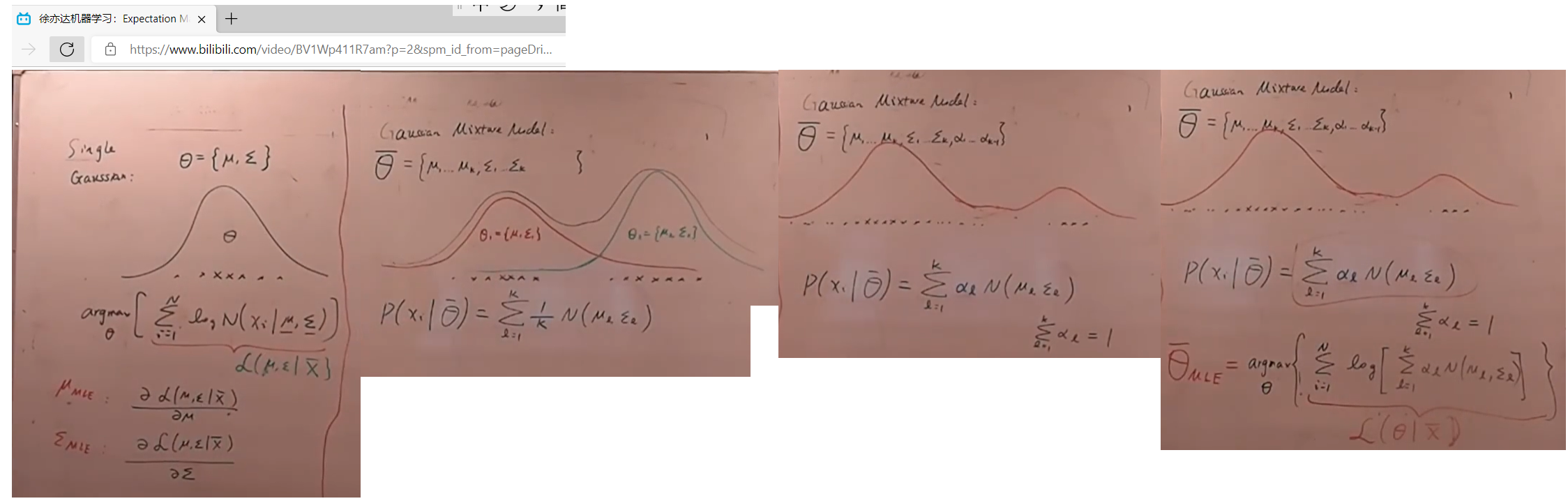
混合高斯分布(多个高斯分布混合在一起) MLE
单高斯混合分布, 只需要令: ∂ L ∂ u = 0 \frac{\partial{L}}{\partial{u}}=0 ∂u∂L=0, ∂ L ∂ Σ = 0 \frac{\partial{L}}{\partial{\Sigma}}=0 ∂Σ∂L=0 ; 即可一步到位的精确的求出 u 和 Σ u和\Sigma u和Σ的值
混合高斯分布,由于L中有log(多个式子求和), 而log(多个式子求和)求出导数是可以的, 但 要解 ∂ L ∂ u = 0 \frac{\partial{L}}{\partial{u}}=0 ∂u∂L=0、 ∂ L ∂ Σ = 0 \frac{\partial{L}}{\partial{\Sigma}}=0 ∂Σ∂L=0 比较难, 所以 没法一步到位精确求解,只能迭代求解 。 此迭代求解方法 即 EM算法
即:
解方程 ∂ l o g ( 多个式子的乘积 ) ∂ 其中一个变量 \frac{\partial{log(多个式子的乘积)}}{\partial{其中一个变量}} ∂其中一个变量∂log(多个式子的乘积) = 0 较难
解方程 ∂ l o g ( 多个式子的和 ) ∂ 其中一个变量 \frac{\partial{log(多个式子的和)}}{\partial{其中一个变量}} ∂其中一个变量∂log(多个式子的和) = 0 较容易
注意:两者的导数都可以求得出来
EM算法(混合高斯分布)
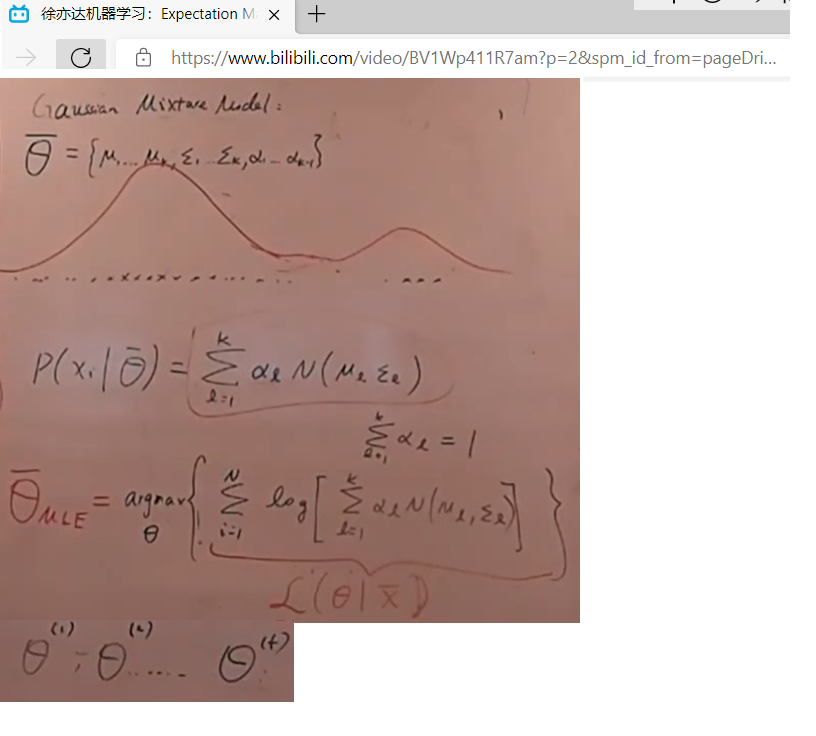
中心点或均值u、形状或协方差矩阵 Σ \Sigma Σ

em算法迭代过程演示
e m 算法参数 Θ 初始化为 Θ ( 1 ) em算法参数\Theta初始化为\Theta^{(1)} em算法参数Θ初始化为Θ(1)
e m 算法第 1 次迭代结果 Θ ( 2 ) em算法第1次迭代结果\Theta^{(2)} em算法第1次迭代结果Θ(2)
e m 算法第 2 次迭代结果 Θ ( 3 ) em算法第2次迭代结果\Theta^{(3)} em算法第2次迭代结果Θ(3)
e m 算法第 f 次迭代结果 ( e m 算法收敛时的结果 ) Θ ( f ) em算法第f次迭代结果(em算法收敛时的结果) \Theta^{(f)} em算法第f次迭代结果(em算法收敛时的结果)Θ(f)

em迭代描述
em算法迭代过程描述:
Θ ( g + 1 ) = Θ ( g ) \Theta^{(g+1)}=\Theta^{(g)} Θ(g+1)=Θ(g)
Θ ( g + 1 ) = a r g m a x Θ ∫ z l o g p ( X , z ∣ Θ ) p ( z ∣ X , Θ ( g ) ) d z \Theta^{(g+1)}={argmax}_{\Theta}\int_{z} {log p(X,z|\Theta) p(z|X,\Theta^{(g)})} dz Θ(g+1)=argmaxΘ∫zlogp(X,z∣Θ)p(z∣X,Θ(g))dz (这里看完后 弄清楚了 回头要明确一下)

em算法引入的隐变量z应该保持边缘分布不变:

这里的 z i z_i zi 就是前面"EM算法(混合高斯分布)" 中的 α l \alpha_l αl
上图 p ( x i ) p(x_i) p(xi) 就是 p ( x i ∣ Θ ) p(x_i|\Theta) p(xi∣Θ)
em算法中 log_likelihood l o g p ( X ∣ Θ ) log p(X|\Theta) logp(X∣Θ) 逐步增加 推导 1
如果 对于任意 Θ \Theta Θ 有 H ( Θ ( g ) , Θ ( g ) ) ≥ H ( Θ , Θ ( g ) ) H(\Theta^{(g)}, \Theta^{(g)} ) \ge H(\Theta, \Theta^{(g)} ) H(Θ(g),Θ(g))≥H(Θ,Θ(g)),
则 H ( Θ ( g ) , Θ ( g ) ) ≥ H ( Θ ( g + 1 ) , Θ ( g ) ) H(\Theta^{(g)}, \Theta^{(g)} ) \ge H(\Theta^{(g+1)}, \Theta^{(g)} ) H(Θ(g),Θ(g))≥H(Θ(g+1),Θ(g))

em算法中 log_likelihood l o g p ( X ∣ Θ ) log p(X|\Theta) logp(X∣Θ) 逐步增加 推导 2
Jensen’s inequality (琴生不等式)

…
sklearn 手写数字数据集 gmm 例子 (图片的一个像素点被当成一个随机变量)
"""sklearn 手写数字数据集 gmm 例子 (图片的一个像素点被当成一个随机变量)
来自 https://jakevdp.github.io/PythonDataScienceHandbook/05.12-gaussian-mixtures.html
或 https://github.com/jakevdp/PythonDataScienceHandbook/blob/master/notebooks/05.12-Gaussian-Mixtures.ipynb
"""import numpy as np
from sklearn.datasets import load_digits
from matplotlib import pyplot as plt
def plot_digits(data):fig, ax = plt.subplots(10, 10, figsize=(8, 8),subplot_kw=dict(xticks=[], yticks=[]))fig.subplots_adjust(hspace=0.05, wspace=0.05)for i, axi in enumerate(ax.flat):im = axi.imshow(data[i].reshape(8, 8), cmap='binary')im.set_clim(0, 16)plt.show()digits = load_digits()
print(digits.data.shape)#(1797, 64)# plot_digits(digits.data)from sklearn.decomposition import PCA
pca = PCA(n_components=0.99, whiten=True)
data = pca.fit_transform(digits.data)
print(data.shape)#(1797, 41)from sklearn.mixture import GaussianMixture
"""
n_components = np.arange(50, 210, 10)
models = [GaussianMixture(n_components=n, covariance_type='full', random_state=0) for n in n_components]
aics = [model.fit(data).aic(data) for model in models]
plt.plot(n_components, aics); plt.show()
"""gmm = GaussianMixture(n_components=150, covariance_type='full', random_state=0)
gmm.fit(data)
print(gmm.converged_)data_new,label_new = gmm.sample(n_samples=100)
print(data_new.shape)digits_new = pca.inverse_transform(data_new)
plot_digits(digits_new)



![[Pyhon疫情大数据分析] 四.微博话题抓取及新冠肺炎疫情文本挖掘和情感分析](https://img-blog.csdnimg.cn/20200321143724497.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)