一、作业要求
- 编写Apriori算法程序,平台自选。
- 用Apriori 算法找出频繁项集,支持度和置信度根据情况自行设定。
- 找出强关联规则以及相应的支持度和置信度
- 完成挖掘报告
- 数据部分:
数据已上传网盘:
链接:https://wwn.lanzoul.com/iBhis000uiwb
密码:53b2
ID表示每一笔订单,ITEMS表示每笔订单对应的物品,每件物品由一个大写字母表示

二、概要设计
Apriori算法流程:
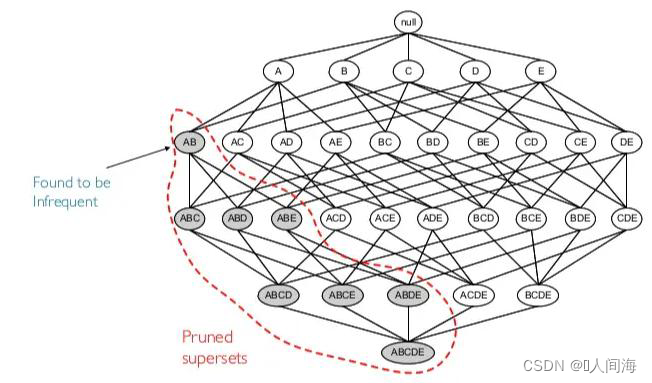
① 扫描数据集,从数据集中生成候选k项集Ck(k从1开始)
② 计算Ck中每个项集的支持度,删除低于阈值的项集,构成频繁项集Lk
③ 将频繁项集Lk中的元素进行组合,生成候选K+1项集Ck+1
④ 重复步骤②③,直到满足以下两个条件之一时,算法结束
i.频繁项集无法组合生成更大的候选项集
ii.所有的候选项集支持度都低于指定阈值(最小支持度),无法生成频繁项集
代码流程:
读取文件数据集,首先对数据进行扫描、切分,生成候选1项集,根据候选1项集生成频繁1项集,接着根据频繁1项集生成候选2项集,以此类推,依次迭代,根据候选k项集生成频繁k项集,接着根据频繁k项集组合成候选K+1项集。依次获取所有的频繁项集,根据所有频繁项集在一定的置信度下得到购物篮数据的强关联规则。
核心函数:
读取文件数据集: loadData(path)
获取候选1项集:buildC1(dataset)
候选k项集生成频繁k项集:ck_to_lk(dataset,ck,min_support)
频繁k项集组合成候选k+1项集:lk_to_ck(lk_list)
获取所有频繁k项集:get_L_all(dataset,min_support)
生成关联规则:rules_from_L_all(L_all,min_confidence)
程序合并,从原始数据生成所有频繁项集和对应置信度下的关联规则:
apriori(dataset,min_support,min_confidence)
三、详细设计及核心代码
传入数据集文件获取数据集,将每一行ID对应的产品逐个分开,存入列表,循环将列表存入数组,每次循环列表置空,返回数组结果。
# 读取文件数据集
def loadData(path):df = pd.read_excel(path,sheet_name='DATASET1', header=1)df=df.iloc[:,1]result=[]for i in range(len(df)):# 每次循环置空dataset = []for row in df:dataset=list(row)result.append(dataset)# print(result)
return result生成候选1项集,通过itertool.chain将数据变成一维,相当于扁平化,此时再将数据放入set()进行去重操作,对于每个项集,使用frozenset进行操作,为了将元素作为字典的key
# 生成候选1项集
def buildC1(dataset):item1=set(itertools.chain(*dataset))return [frozenset([i]) for i in item1]根据候选k项集生成频繁k项集,字典中的key为frozenset类型的对象,字典的value为每个项集对应的支持度。循环记录每一个项集,依次判断项集是否在记录中出现,即判断是不是子集,如果出现,则次数加1,最后计算出现频率,即每个项集的支持度,结果返回每个项集frozenset对象以及对应的支持度。
# 候选k项集->频繁k项集
def ck_to_lk(dataset,ck,min_support):# 定义项集-频数字典,存储每个项集(key)与其对应的频数valuesupport={}for row in dataset:for item in ck:# 判断项集是否在记录中出现(判断是不是子集)if item.issubset(row):support[item]=support.get(item,0)+1total=len(dataset)return {k: v/total for k, v in support.items() if v/total >= min_support}频繁k项集组合成候选k+1项集,参数lk_list为所有频繁k项集构成的列表,通过itertools.combinations获取任意两个元素序号的索引组合,将对应位置的两个频数k项集进行组合,合并成一个新的项集,如果组合之后的项集是k+1项集,则为候选k+1项集,加入到结果set中,函数结果返回所有候选k+1项集构成的set
# 频繁k项集组合成候选k+1项集
def lk_to_ck(lk_list):# 保存所有组合之后的候选k+1项集ck=set()lk_size=len(lk_list)# 如果频繁k项集的数量小于1,则不可能再通过组合生成候选k+1项集if lk_size > 1:# 获取频繁k项集的k值k=len(lk_list[0])# 获取任意两个元素序号的索引组合for i,j in itertools.combinations(range(lk_size),2):# 将对应位置的两个频数k项集进行组合,生成一个新的项集(合并)t=lk_list[i] | lk_list[j]# 如果组合之后的项集是k+1项集,则为候选k+1项集,加入到结果set中if len(t)==k+1:ck.add(t)return ck获取所有频繁k项集,当频繁k项集的数量大于1,才可能再通过组合生成候选k + 1项集,将频繁k项集数量大于1作为循环条件,反复进行操作由频繁k项集生成候选k+1项集,由候选k+1项集组合生成频繁k+1项集。如果频繁k+1项集字典不为空,则将所有频繁k+1项集加入到L_all字典中,否则,频繁k+1项集为空,退出循环,最终结果得到所有频繁k项集。
# 获取所有频繁k项集
def get_L_all(dataset,min_support):c1 = buildC1(dataset)L1 = ck_to_lk(dataset, c1, min_support)# 定义字典,保存所有的频繁k项集L_all=L1Lk=L1# 当频繁k项集的数量大于1,才可能再通过组合生成候选k + 1项集while len(Lk) > 1:lk_key_list=list(Lk.keys())# 由频繁k项集生成候选k+1项集ck=lk_to_ck((lk_key_list))# 由候选k+1项集组合生成频繁k+1项集Lk=ck_to_lk(dataset,ck,min_support)# 如果频繁k+1项集字典不为空,则将所有频繁k+1项集加入到L_all字典中if len(Lk) > 0:L_all.update(Lk)else:# 否则,频繁k+1项集为空,退出循环breakreturn L_all从所有的频繁项集字典中,生成关联规则,参数L_all为所有频繁项集,参数min_confidence为最小置信度,大于最小置信度则保留关联规则。通过条件概率公式计算每个频繁项集的置信度,若大于最小置信度,则通过左侧,右侧,支持度和置信度的方式展示频繁项集的关联规则。
# 从所有的频繁项集字典中,生成关联规则
def rules_from_L_all(L_all,min_confidence):# 保存所有候选的关联规则rules=[]for Lk in L_all:if len(Lk) > 1:rules.extend(rules_from_item(Lk))result=[]for left,right in rules:support=L_all[left | right]confidence=support/L_all[left]if confidence >= min_confidence:result.append({"左侧":left,"右侧":right,"支持度":support,"置信度":confidence})# print(result)return result代码合并,从原始数据根据最小支持度和最小置信度生成所有频繁项集和对应置信度下的关联规则,并格式化打印最终结果
def apriori(dataset,min_support,min_confidence):L_all=get_L_all(dataset,min_support)print(len(L_all))for i in range(len(L_all)):L_all_list=list(L_all)print(L_all_list[i])rules=rules_from_L_all(L_all,min_confidence)return rules四、运行结果截图
根据不同的支持度和置信度做了四组实验,结果展示如下:
① 支持度:0.3,置信度0.4
所有频繁项集:

根据所有频繁项集生成的强关联规则:

② 支持度:0.4,置信度0.5
所有频繁项集:

根据所有频繁项集生成的强关联规则:

③ 支持度:0.5,置信度0.6
所有频繁项集:
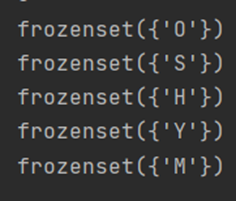
根据所有频繁项集生成的强关联规则:(此时无法产生强关联规则)
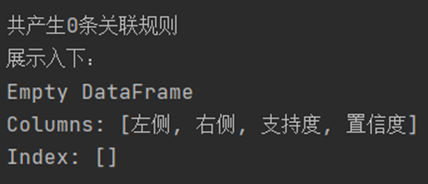
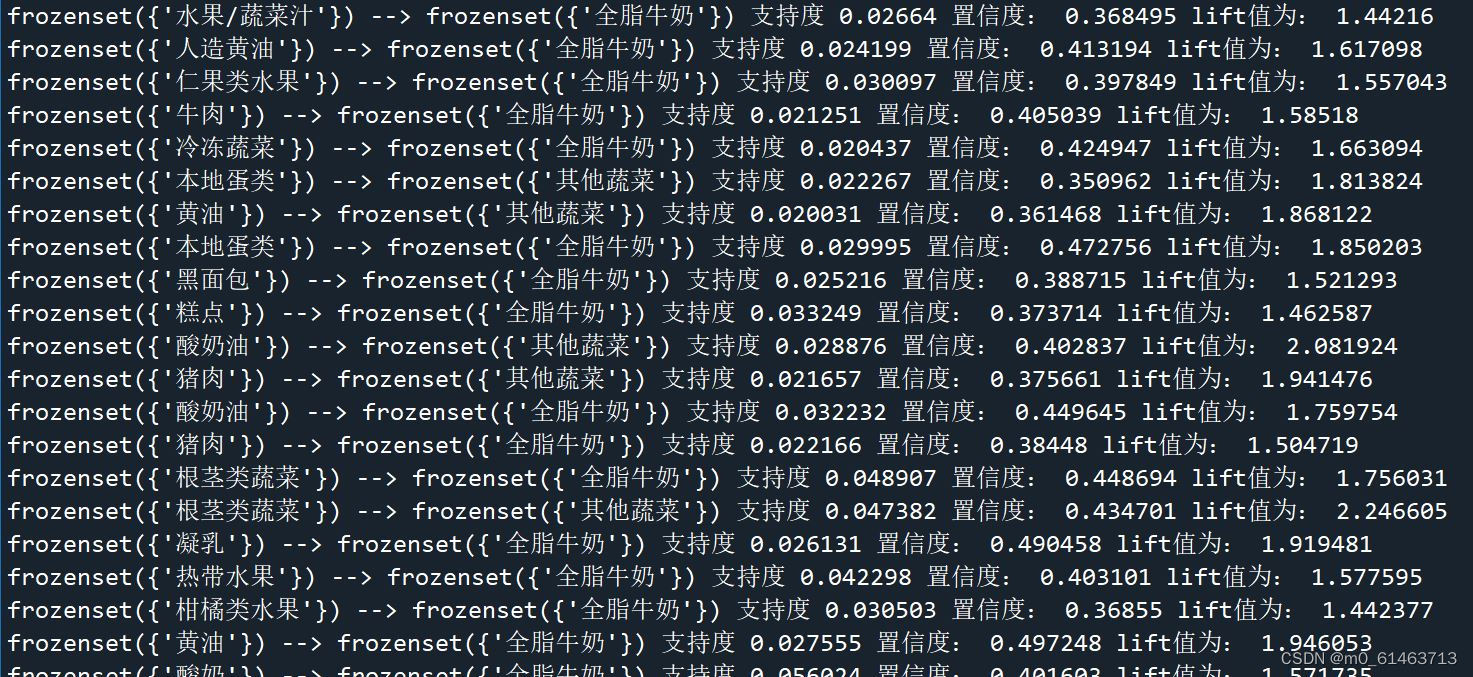
④ 支持度:0.4,置信度0.9
所有频繁项集:

根据所有频繁项集生成的强关联规则:
五、总结
根据上述四组实验可以得出一些结论:在支持度为0.3的条件下,[A,H]->[M],[A,M]->[H]与[H,M]->[A]这三条关联规则的置信度相对高,其中[A,M]->[H]的置信度最高,在购买产品A,M的条件下,购买产品H的概率很高;产品S,O,Y支持度较高,出售情况良好,在支持度为0.4的情况下,[O,S]->[Y],[O,Y]->[S]与[S,Y]->[0]这三条关联关系的置信度最高,在购买产品O,S的条件下,购买产品Y的概率很高;在购买产品O,Y的条件下,购买产品S的概率很高;在购买产品S,Y的条件下,购买产品O的概率很高。因此,这一系列结论可以为超市产品的组合销售等销售方式提供建议。
六、完整代码
# _*_ coding:utf-8 _*_
import pandas as pd
import itertools
# 读取文件数据集
def loadData(path):# df = pd.read_excel('Apriori_1000_Items_DataSet.xls',sheet_name='DATASET1', header=1)df = pd.read_excel(path,sheet_name='DATASET1', header=1)df=df.iloc[:,1]result=[]for i in range(len(df)):# 每次循环置空dataset = []for row in df:# row = row.strip("\n")dataset=list(row)result.append(dataset)# print(result)return result# 候选1项集
def buildC1(dataset):item1=set(itertools.chain(*dataset))return [frozenset([i]) for i in item1]# 根据候选1项集生成频繁1项集,字典中的key为frozenset类型的对象
# 字典的value为每个项集对应的支持度
# 候选k项集->频繁k项集,最小支持度
def ck_to_lk(dataset,ck,min_support):# 定义项集-频数字典,存储每个项集(key)与其对应的频数valuesupport={}for row in dataset:for item in ck:# 判断项集是否在记录中出现(判断是不是子集)if item.issubset(row):support[item]=support.get(item,0)+1total=len(dataset)return {k: v/total for k, v in support.items() if v/total >= min_support}# 频繁k项集组合成候选k+1项集
# lk_list为所有频繁k项集构成的列表
# ck:返回所有候选k+1项集构成的set
def lk_to_ck(lk_list):# 保存所有组合之后的候选k+1项集ck=set()lk_size=len(lk_list)# 如果频繁k项集的数量小于1,则不可能再通过组合生成候选k+1项集if lk_size > 1:# 获取频繁k项集的k值k=len(lk_list[0])# 获取任意两个元素序号的索引组合for i,j in itertools.combinations(range(lk_size),2):# 将对应位置的两个频数k项集进行组合,生成一个新的项集(合并)t=lk_list[i] | lk_list[j]# 如果组合之后的项集是k+1项集,则为候选k+1项集,加入到结果set中if len(t)==k+1:ck.add(t)return ck# 获取所有频繁k项集
def get_L_all(dataset,min_support):c1 = buildC1(dataset)L1 = ck_to_lk(dataset, c1, min_support)# 定义字典,保存所有的频繁k项集L_all=L1Lk=L1# 当频繁k项集的数量大于1,才可能再通过组合生成候选k + 1项集while len(Lk) > 1:lk_key_list=list(Lk.keys())# 由频繁k项集生成候选k+1项集ck=lk_to_ck((lk_key_list))# 由候选k+1项集组合生成频繁k+1项集Lk=ck_to_lk(dataset,ck,min_support)# 如果频繁k+1项集字典不为空,则将所有频繁k+1项集加入到L_all字典中if len(Lk) > 0:L_all.update(Lk)else:# 否则,频繁k+1项集为空,退出循环breakreturn L_all# 生成关联规则
def rules_from_item(item):# 定义规则左侧的列表left=[]for i in range(1,len(item)):left.extend(itertools.combinations(item,i))# 集合的差集return [(frozenset(le),frozenset(item.difference(le))) for le in left]# 从所有的频繁项集字典中,生成关联规则
# min_confidence最小置信度,保留关联规则
def rules_from_L_all(L_all,min_confidence):# 保存所有候选的关联规则rules=[]for Lk in L_all:if len(Lk) > 1:rules.extend(rules_from_item(Lk))result=[]for left,right in rules:support=L_all[left | right]confidence=support/L_all[left]lift=confidence/L_all[right]if confidence >= min_confidence:result.append({"左侧":left,"右侧":right,"支持度":support,"置信度":confidence})# print(result)return resultdef apriori(dataset,min_support,min_confidence):L_all=get_L_all(dataset,min_support)print(len(L_all))for i in range(len(L_all)):L_all_list=list(L_all)print(L_all_list[i])rules=rules_from_L_all(L_all,min_confidence)return rulesdef change(item):li=list(item)# for i in range(len(li)):return lipath='Apriori_1000_Items_DataSet.xls'
dataset=loadData(path)
# rules=apriori(dataset,0.05,0.3)
# print(rules)
# c1=buildC1(dataset)
# print(c1)
# L1=ck_to_lk(dataset,c1,0.05)
# print(L1)
# c2=lk_to_ck(list(L1.keys()))
# print(c2)
# L2=ck_to_lk(dataset,c2,0.05)
# print(L2)
# L_all=get_L_all(dataset,0.2)
# print(L_all)
# 生成项集{1,2,3}的关联规则
# print(rules_from_item(frozenset({1,2,3})))
# rules_from_L_all(L_all,0.3)# 赋予支持度和置信度
rules=apriori(dataset,0.4,0.9)
df=pd.DataFrame(rules)
df=df.reindex(["左侧","右侧","支持度","置信度"],axis=1)
df["左侧"]=df["左侧"].apply(change)
df["右侧"]=df["右侧"].apply(change)
print("\n共产生"+str(len(df))+"条关联规则")
print("展示入下:")
print(df)




![[Python] 电商平台用户的购物篮分析](https://img-blog.csdnimg.cn/20201001091330238.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xhbV95eA==,size_16,color_FFFFFF,t_70#pic_center)








![[windows]修改本机host配置](https://img-blog.csdnimg.cn/20200929161406301.gif#pic_center)