一、实验目的及要求
通过项目的训练学习,了解数据挖掘在零售业中应用状况,掌握数据挖掘在零售业中分析方法及过程。
二、实验仪器设备
系统环境:Windows10
软件环境:SPSS Clementine11.1
三、实验内容
(一)实验相关知识点:
Apriori算法、相关规则、频繁项集
(二)实验原理:
Apriori算法是发现关联规则领域的经典算法。该算法将发现关联规则的过程分为两个阶段:第一阶段,通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;第二阶段,利用频繁项集构造出满足用户最小置信度(或者其他设定的要求)的规则。关联规则挖掘的一个典型例子是购物篮分析。市场分析员要从大量的数据中发现顾客放入其购物篮中的不同商品之间的关系。分析结果可以帮助经理设计不同的商店布局。一种策略是:经常一块购买的商品可以放近一些,以便进一步刺激这些商品一起销售。另一种策略是:将硬件和软件放在商店的两端,可能诱发购买这些商品的顾客一路挑选其他商品。关联分析的目的就是找出数据库中隐藏的关联,并以规则的形式表达出来,这就是关联规则。
(三)实验过程:
1.数据流如下



以小类(ProductSubCategory)做两者变量,即方向设置为双向,再将购物篮号(TransationID)的方向设置为输入,其他变量的方向均设置为无。
2.选择建模的字段
购物篮号作为关联的前项,小类作为关联的后项

3.设置支持度
最小支持度设置为1,最小置信度设置为20,最大前项数设置为5.

4.食品部小类商品关联性网络图

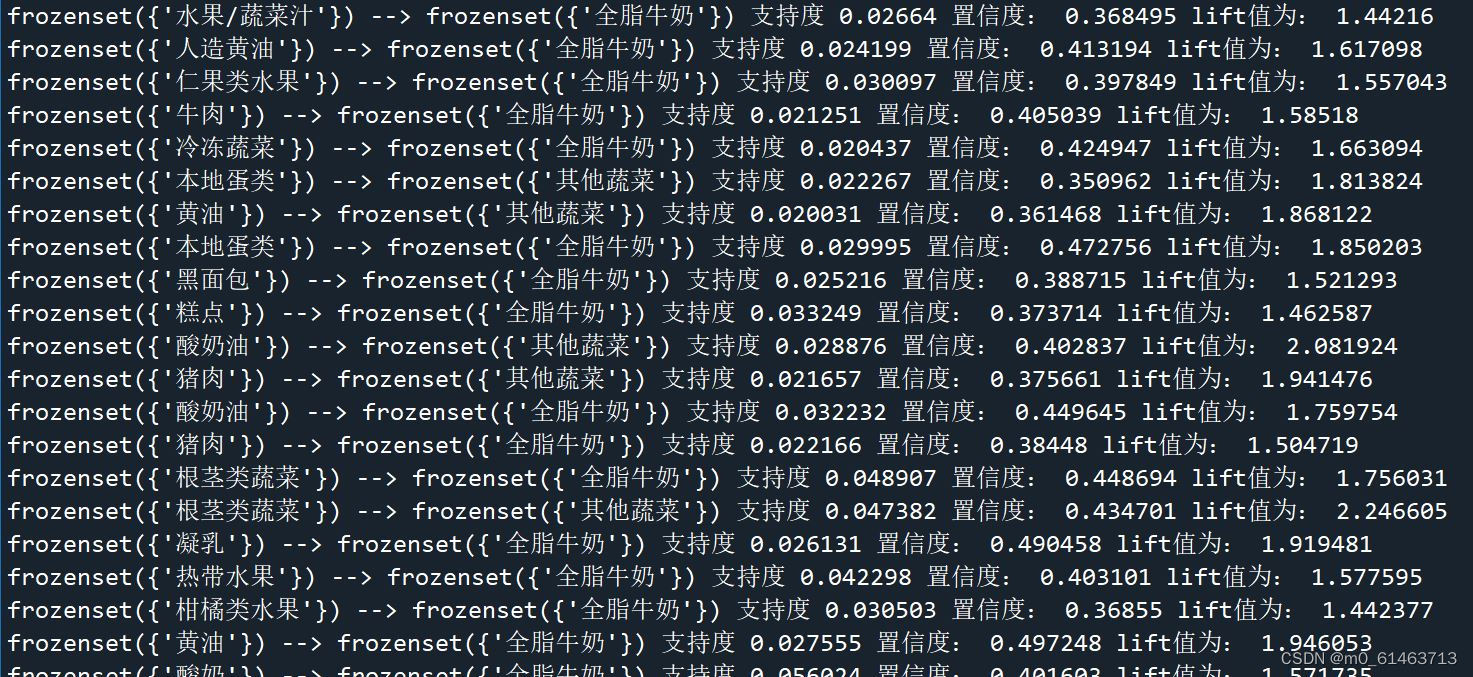
5.食品部小类商品部分关联表

四、实验总结
从食品部小类商品部分关联表中可以由支持度和置信度的大小得出几个较好的强关联规则,如①买水产制品的顾客很有可能买畜肉制品;②客买了进口食品中的任意一中很有可能会其他进口食品;③卤蛋的顾客很有可能会买猪肉火腿。所以表格中的关联规则来看,建议超市将所有进口商品放在一个区域,把肉类制品,水产制品放在相邻的区域。



![[Python] 电商平台用户的购物篮分析](https://img-blog.csdnimg.cn/20201001091330238.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xhbV95eA==,size_16,color_FFFFFF,t_70#pic_center)








![[windows]修改本机host配置](https://img-blog.csdnimg.cn/20200929161406301.gif#pic_center)

