自然文本检测主要模型
CTPN模型
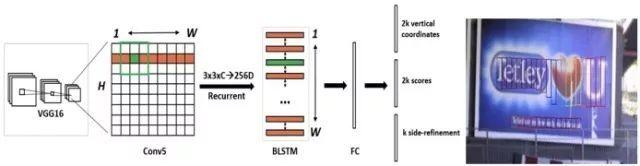
CTPN是目前流传最广、影响最大的开源文本检测模型,可以检测水平或微斜的文本行。文本行可以被看成一个字符sequence,而不是一般物体检测中单个独立的目标。同一文本行上各个字符图像间可以互为上下文,在训练阶段让检测模型学习图像中蕴含的这种上下文统计规律,可以使得预测阶段有效提升文本块预测准确率。CTPN模型的图像预测流程中,前端使用当时流行的VGG16做基础网络来提取各字符的局部图像特征,中间使用BLSTM层提取字符序列上下文特征,然后通过FC全连接层,末端经过预测分支输出各个文字块的坐标值和分类结果概率值。在数据后处理阶段,将合并相邻的小文字块为文本行。
RRPN模型
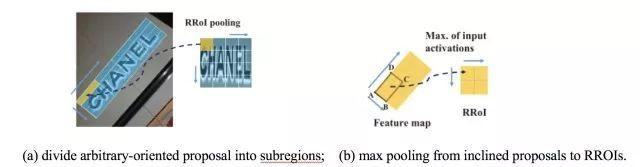
基于旋转区域候选网络(RRPN, Rotation Region Proposal Networks)的方案,将旋转因素并入经典区域候选网络(如Faster RCNN)。这种方案中,一个文本区域的ground truth被表示为具有5元组(x,y,h,w,θ)的旋转边框, 坐标(x,y)表示边框的几何中心, 高度h设定为边框的短边,宽度w为长边,方向是长边的方向。训练时,首先生成含有文本方向角的倾斜候选框,然后在边框回归过程中学习文本方向角。

RRPN中方案中提出了旋转感兴趣区域(RRoI,Rotation Region-of-Interest)池化层,将任意方向的区域建议先划分成子区域,然后对这些子区域分别做max pooling、并将结果投影到具有固定空间尺寸小特征图上。
FTSN模型
FTSN(Fused Text Segmentation Networks)模型使用分割网络支持倾斜文本检测。它使用Resnet-101做基础网络,使用了多尺度融合的特征图。标注数据包括文本实例的像素掩码和边框,使用像素预测与边框检测多目标联合训练。

基于文本实例间像素级重合度的Mask-NMS, 替代了传统基于水平边框间重合度的NMS算法。下图左边子图是传统NMS算法执行结果,中间白色边框被错误地抑制掉了。下图右边子图是Mask-NMS算法执行结果, 三个边框都被成功保留下来。

DMPNet模型
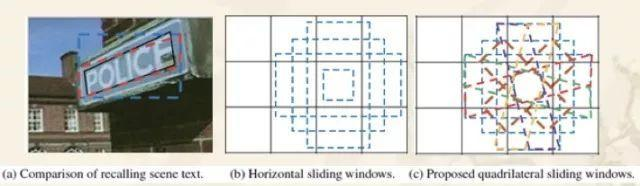
DMPNet(Deep Matching Prior Network)中,使用四边形(非矩形)来更紧凑地标注文本区域边界,其训练出的模型对倾斜文本块检测效果更好。
如下图所示,它使用滑动窗口在特征图上获取文本区域候选框,候选框既有正方形的、也有倾斜四边形的。接着,使用基于像素点采样的Monte-Carlo方法,来快速计算四边形候选框与标注框间的面积重合度。然后,计算四个顶点坐标到四边形中心点的距离,将它们与标注值相比计算出目标loss。文章中推荐用Ln loss来取代L1、L2 loss,从而对大小文本框都有较快的训练回归(regress)速度。
EAST模型
EAST(Efficient and Accuracy Scene Text detection pipeline)模型中,首先使用全卷积网络(FCN)生成多尺度融合的特征图,然后在此基础上直接进行像素级的文本块预测。该模型中,支持旋转矩形框、任意四边形两种文本区域标注形式。对应于四边形标注,模型执行时会对特征图中每个像素预测其到四个顶点的坐标差值。对应于旋转矩形框标注,模型执行时会对特征图中每个像素预测其到矩形框四边的距离、以及矩形框的方向角。
根据开源工程中预训练模型的测试,该模型检测英文单词效果较好、检测中文长文本行效果欠佳。或许,根据中文数据特点进行针对性训练后,检测效果还有提升空间。
上述过程中,省略了其他模型中常见的区域建议、单词分割、子块合并等步骤,因此该模型的执行速度很快。

SegLink模型
SegLink模型的标注数据中,先将每个单词切割为更易检测的有方向的小文字块(segment),然后用邻近连接(link )将各个小文字块连接成单词。这种方案方便于识别长度变化范围很大的、带方向的单词和文本行,它不会象Faster-RCNN等方案因为候选框长宽比例原因检测不出长文本行。相比于CTPN等文本检测模型,SegLink的图片处理速度快很多。

如下图所示,该模型能够同时从6种尺度的特征图中检测小文字块。同一层特征图、或者相邻层特征图上的小文字块都有可能被连接入同一个单词中。换句话说,位置邻近、并且尺寸接近的文字块都有可能被预测到同一单词中。
PixelLink模型
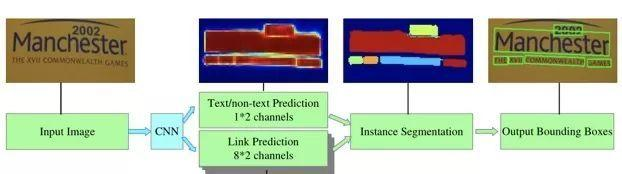
自然场景图像中一组文字块经常紧挨在一起,通过语义分割方法很难将它们识别开来,所以PixelLink模型尝试用实例分割方法解决这个问题。
该模型的特征提取部分,为VGG16基础上构建的FCN网络。模型执行流程如下图所示。首先,借助于CNN 模块执行两个像素级预测:一个文本二分类预测,一个链接二分类预测。接着,用正链接去连接邻居正文本像素,得到文字块实例分割结果。然后,由分割结果直接就获得文字块边框, 而且允许生成倾斜边框。
上述过程中,省掉了其他模型中常见的边框回归步骤,因此训练收敛速度更快些。训练阶段,使用了平衡策略,使得每个文字块在总LOSS中的权值相同。训练过程中,通过预处理增加了各种方向角度的文字块实例。
Textboxes/Textboxes++模型
Textboxes是基于SSD框架的图文检测模型,训练方式是端到端的,运行速度也较快。如下图所示,为了适应文字行细长型的特点,候选框的长宽比增加了1,2,3,5,7,10这样初始值。为了适应文本行细长型特点,特征层也用长条形卷积核代替了其他模型中常见的正方形卷积核。为了防止漏检文本行,还在垂直方向增加了候选框数量。为了检测大小不同的字符块,在多个尺度的特征图上并行预测文本框, 然后对预测结果做NMS过滤。

Textboxes++是Textboxes的升级版本,目的是增加对倾斜文本的支持。为此,将标注数据改为了旋转
WordSup模型
如下图所示,在数学公式图文识别、不规则形变文本行识别等应用中,字符级检测模型是一个关键基础模块。由于字符级自然场景图文标注成本很高、相关公开数据集稀少,导致现在多数图文检测模型只能在文本行、单词级标注数据上做训练。WordSup提出了一种弱监督的训练框架, 可以文本行、单词级标注数据集上训练出字符级检测模型。

如下图所示,WordSup弱监督训练框架中,两个训练步骤被交替执行:给定当前字符检测模型,并结合单词级标注数据,计算出字符中心点掩码图; 给定字符中心点掩码图,有监督地训练字符级检测模型.

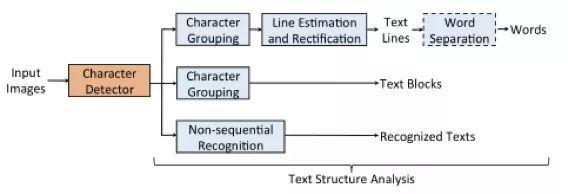
如下图,训练好字符检测器后,可以在数据流水线中加入合适的文本结构分析模块,以输出符合应用场景格式要求的文本内容。该文作者例举了多种文本结构分析模块的实现方式。
CRNN模型
CRNN(Convolutional Recurrent Neural Network)是目前较为流行的图文识别模型,可识别较长的文本序列。它包含CNN特征提取层和BLSTM序列特征提取层,能够进行端到端的联合训练。 它利用BLSTM和CTC部件学习字符图像中的上下文关系, 从而有效提升文本识别准确率,使得模型更加鲁棒。预测过程中,前端使用标准的CNN网络提取文本图像的特征,利用BLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC rule)进行预测得到文本序列。

RARE模型
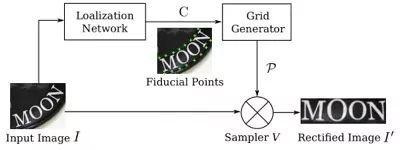
RARE(Robust text recognizer with Automatic Rectification)模型在识别变形的图像文本时效果很好。如下图所示,模型预测过程中,输入图像首先要被送到一个空间变换网络中做处理,矫正过的图像然后被送入序列识别网络中得到文本预测结果。

如下图所示,空间变换网络内部包含定位网络、网格生成器、采样器三个部件。经过训练后,它可以根据输入图像的特征图动态地产生空间变换网格,然后采样器根据变换网格核函数从原始图像中采样获得一个矩形的文本图像。RARE中支持一种称为TPS(thin-plate splines)的空间变换,从而能够比较准确地识别透视变换过的文本、以及弯曲的文本.