点击我爱计算机视觉标星,更快获取CVML新技术
本文为作者对AAAI 2020 论文的解读。
作者 | 徐瑞聪
编辑 | Camel
本篇文章介绍上海交通大学 BCMI 实验室在AAAI 2020 上的一项工作,A Proposal-based Approach for Activity Image-to-Video Retrieval。
论文链接:https://arxiv.org/pdf/1911.10531.pdf
代码链接:https://github.com/bcmi/Cross-modal-retrieval
互联网时代技术的迅速发展,推动了图片、文字、视频等多媒体的爆发。当今社会越来越不能满足于单一模态的检索需求,大量跨模态检索的应用在不断发展。其中,基于图片查询的视频检索是一类具有研究意义和价值的应用,例如,利用幻灯片搜索相关视频讲座、推荐与图片相关的视频电影、利用照片去检索新闻视频等。但是,由于图片和视频之间数据分布不同,并且语义信息不一致,这必然导致传统的单模态检索方式不适用于跨模态检索任务。如何挖掘数据内在的联系、如何建立多模态信息特征的统一映射、如何保证检索速度都是跨模态检索面临的巨大的挑战。
在跨模态检索任务中,对图片的特征提取工作已经趋于成熟,基于深度模型的方法已经在大量分类任务中验证具有较好的效果。不同于图片特征提取,由于视频复杂的内容和结构特征,视频特征提取的研究工作在不断探索中。传统的检索方式可以将视频中每一帧进行信息抽取并表达,则图片到视频的检索工作可以看作图片到视频帧的检索工作。但传统方式对视频的表达必然会导致视频表达中存在与主要信息内容无关的冗余背景片段,为后续检索工作造成一定的困难。
为了解决上述问题,基于时序信息的深度网络被大量研究。通过同时从时间和空间维度学习特征,循环神经网络(RNN)和3D卷积网络(3D CNN)被广泛利用在视频领域。作为3D CNN模型的扩展,R-C3D模型被应用于连续视频的行为检测任务。R-C3D模型首先通过一个C3D模型提取特征,再利用区域候选网络(RPN)提取候选的活动序列段,最后在分类子网络中进行分类和活动序列段边界的回归。
针对本任务的需求,我们创新性地采用R-C3D模型来生成候选的活动区域段特征,进一步滤除嘈杂的背景信息片段,从而获得优越的视频活动区域段表示方法来进行跨模态检索任务。
APIVR:基于对抗学习的跨模态检索方法
本文主要针对基于图片查询的视频检索任务,提出一个基于对抗学习方式的跨模态检索方法——APIVR方法。
首先,对于视频数据的表示方法,我们新颖地利用行为分类模型R-C3D来提取出基于时序的活动区域段(proposal-based)特征,并将视频以活动信息包的形式表达。
然后,针对图片到视频包的检索任务,我们创新性地将基于图的多示例学习模块(Graph Multi-Instance Learning)整合到跨模态检索框架中,用以解决检索过程中视频信息包中存在的信息冗余问题。
本文提出的跨模态检索框架是基于对抗学习的方式,其中图片和视频包首先分别通过一个三层全连接网络映射到统一的特征空间中,再由基于几何投影(Geometry-aware)的三元组损失函数、语义分类损失函数、对抗损失函数共同调整特征的学习,优化映射空间中图片和视频之间的模态差异。模型整体的框架如图所示。下面将具体介绍APIVR方法的各个模块。
(1) 映射空间
我们将输入的图片表示为q,输入的视频包为。考虑到在跨模态检索任务中,视频和图像具有不同的统计属性和数据分布。我们分别使用两个映射函数将视频和图像特征投影到一个公共特征空间中。映射函数定义为:
考虑到全连接层具有丰富的参数保证映射的表达能力,所以本文采用三层全连接层来实现空间映射。根据映射空间学习到的视频和图像特征,APIVR方法首先利用基于图的多示例模型学习视频的显著信息,再利用三种类型的损失函数调整映射空间中的图像和视频特征。
(2) 基于图的多示例模块(GMIL)
在本框架中,尽管我们利用R-C3D模型使视频中尽可能包含所有可能的活动信息,但是,视频包的表达不可避免地存在与活动信息无关的冗余信息。如果我们基于整体的视频标签利用这些嘈杂的活动信息,则语义学习的质量将极大地降低。
实际上,我们将此问题转换为多示例学习问题,即,每一个视频都被视为一个示例包,而每个视频包中的活动信息被视为一个示例。多示例问题是基于自我注意机制,通过挑选出显著性示例来更好表达整体的信息。同时我们将图卷积结构结合到多示例框架中,可以进一步优化每个包中的图结构信息。
最后,我们得到视频包中活动信息的加权值作为整体视频的特征表达。通过对视频包中不同的活动信息分配不同的权重值,我们可以将目标更好地放在干净的示例上,进一步获得具有可区别性的视频特征表达。
(3) 基于几何投影(Geometry-aware)的三元组损失函数
本方法采用三元组损失函数来训练映射空间中的特征向量,进一步保证不同模态下相似的训练样本具有语义相关性。对于一批训练样本视频-图像对,令每张图片为样例,对应的视频为正样例,其他类别的视频为负样例,则我们得到三元组损失函数为:
其中,m用来约束正负样例之间的距离,d(x,y)表示x和y之间的距离。在我们任务中,图像和视频之间数据结构上的差异使得传统的相似度度量方法不能直接利用,因此,本方法采用图像点与其在视频子空间上的正交投影之间的欧几里得距离来描述图像与视频之间的相似性,进而也保证视频的结构信息未被丢失。
由于视频中的冗余信息会干扰图像点到视频子空间的投影准确性,因此,我们提出利用挑选后的视频活动信息来代替完整的视频表达。
(4) 语义分类损失函数
为了确保每个模态中的训练样本在语义上的区别性,我们还使用语义分类器将模态内训练样本从不同类别中分离出来。为了最大程度地减少模态差异,我们对图像和视频应用了相同的分类器。但是,将分类器应用于视频时,视频中的活动信息存在噪音问题。
因此,我们对分类器的定义会基于我们提出来的基于图的多示例模块,视频表达经过多示例模块的学习后,可以生成较为干净的信息表达。给定一组视频-图像对,则语义分类损失函数写为:
(5) 对抗损失函数
前面介绍的三元组损失函数和语义损失函数的目的是学习语义可区分性的特征表达,为了进一步保证特征表达的模态一致性,我们设计一个模态分类器来辨别模态。通过将辨别模态的过程与映射空间中特征学习的过程相互对抗,进一步缩小图像和视频表达之间的差异。
在本方法中,模态分类器通过一个二分类器来实现,用以区分图像和视频两种模态。在映射空间特征学习的过程中,我们希望在映射空间学习出来的图像和视频特征可以消除模态的差异,只保留语义上的一致性,这样在模态分类时候会对模态分类器进行混淆,以对抗的方式进行学习。
同时,考虑到在视频表达中,干净的活动信息具有更具表达性的特征分布,而噪音背景则会分散在整个特征空间中。因此,我们将模态分类器应用于视频的加权表达。类似于语义分类损失函数,最后我们得到的对抗损失函数为:
其中,是针对视频的预测概率模型。由于对抗学习是辨别模态过程和特征学习过程之间的相互作用,因此,在辨别模态的过程中,我们通过调整模态分类器的参数来最小化对抗损失函数。
相反,在映射空间的特征学习过程中,我们通过调整全连接层参数和基于图的多示例模块参数来最大化对抗损失函数。我们通过极小-极大的训练方式交替分辨不同的模态和学习映射空间中的特征表达,训练目标如下:
实验结果
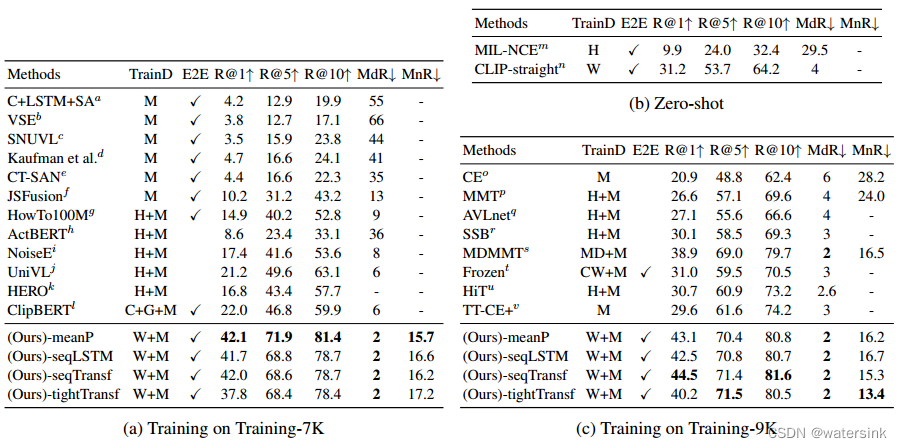
我们在三个公共数据集上做了对比实验,通过和一些通用方法的比较,实验结果表明我们的模型具有显著的优越性和良好的通用性。同时,我们对各个模块进行了定量分析,实验结果如下:
其中,具体来说,我们设定APIVR (w/o TL), APIVR (w/o AL)和APIVR (w/o CL)分别表示为APIVR方法中消除三元组损失、对抗损失、语义分类损失的三种情况,进一步研究三种类型损失函数的效果和贡献。并且,为了验证基于几何投影相似性方法在三元组损失函数中的效果,我们用向量间的欧式距离来代替点面投影间的距离,并且命名这种情况为APIVR (w/o GA)。
此外,为了验证我们提出的基于图的多示例模块(GMIL)的有效性,我们将GMIL模块替换成MIL模块,并且用APIVR(w/o Graph)来表示这种情况。同时,我们还为视频中每一个活动信息特征分配统一的权重值,进而代替GMIL模块学习出来的权重值,命名为APIVR(w/o GMIL)。
从实验结果可以看出,与对抗损失和三元组损失相比,语义分类损失对性能的影响更大,这证明了语义分类器在我们的模型框架中的重要性。当使用传统的三元组损失而不是基于几何投影的三元组损失时,APIVR (w/o GA)的性能会有所下降,这表明保留视频活动信息的结构信息和几何属性对相似性学习是有益的。
此外,我们还可以注意到,APIVR (w/o GMIL)的结果要比完整的APIVR方法效果要差,这证明了我们提出的基于GMIL模块可以更加关注干净的活动信息,并对检索过程具有好处。最后,我们可以观察到APIVR(w/o Graph)的性能不及完整的APIVR方法,这表明了将图卷积层插入MIL模块的优势。
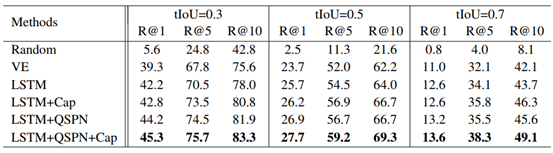
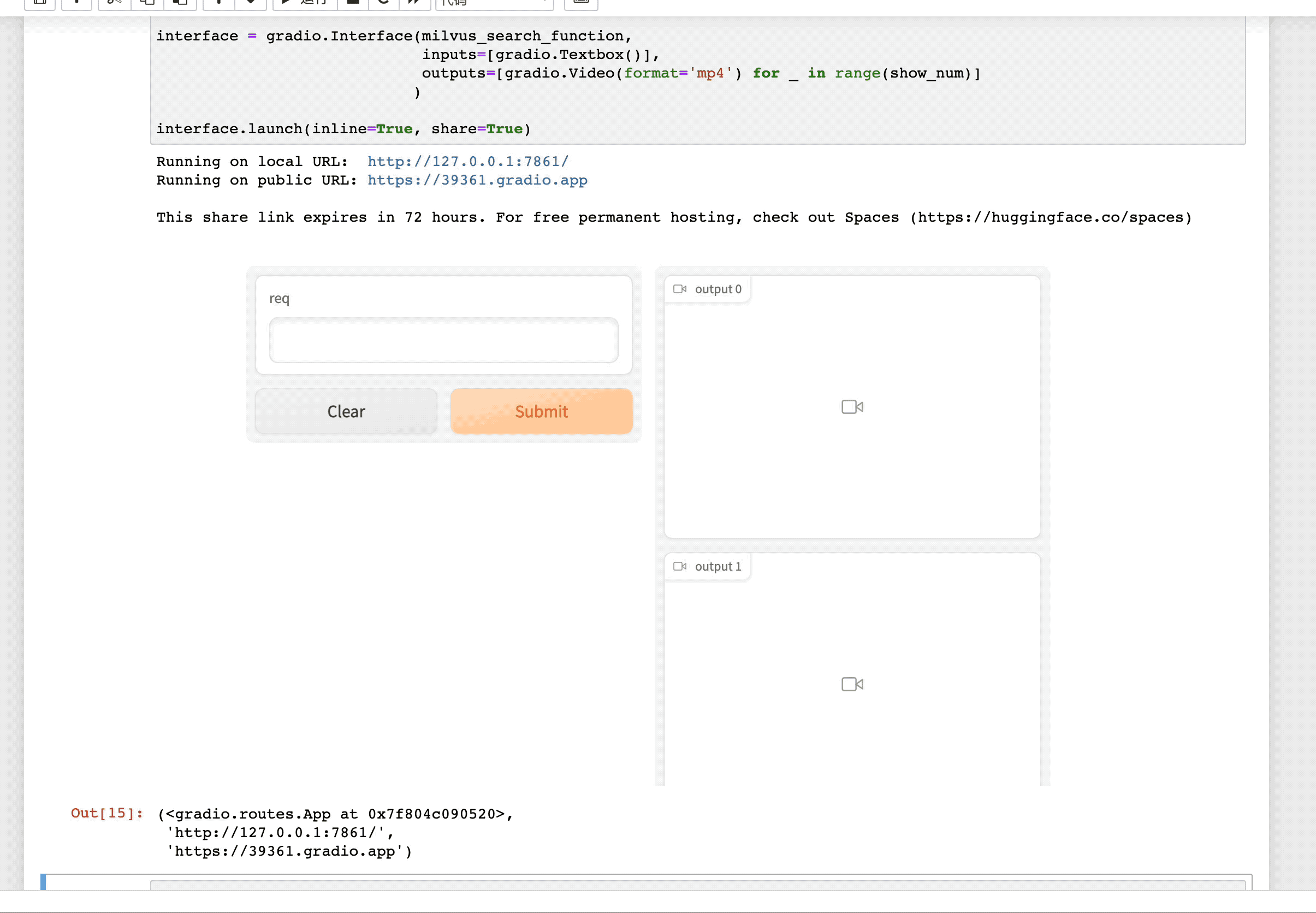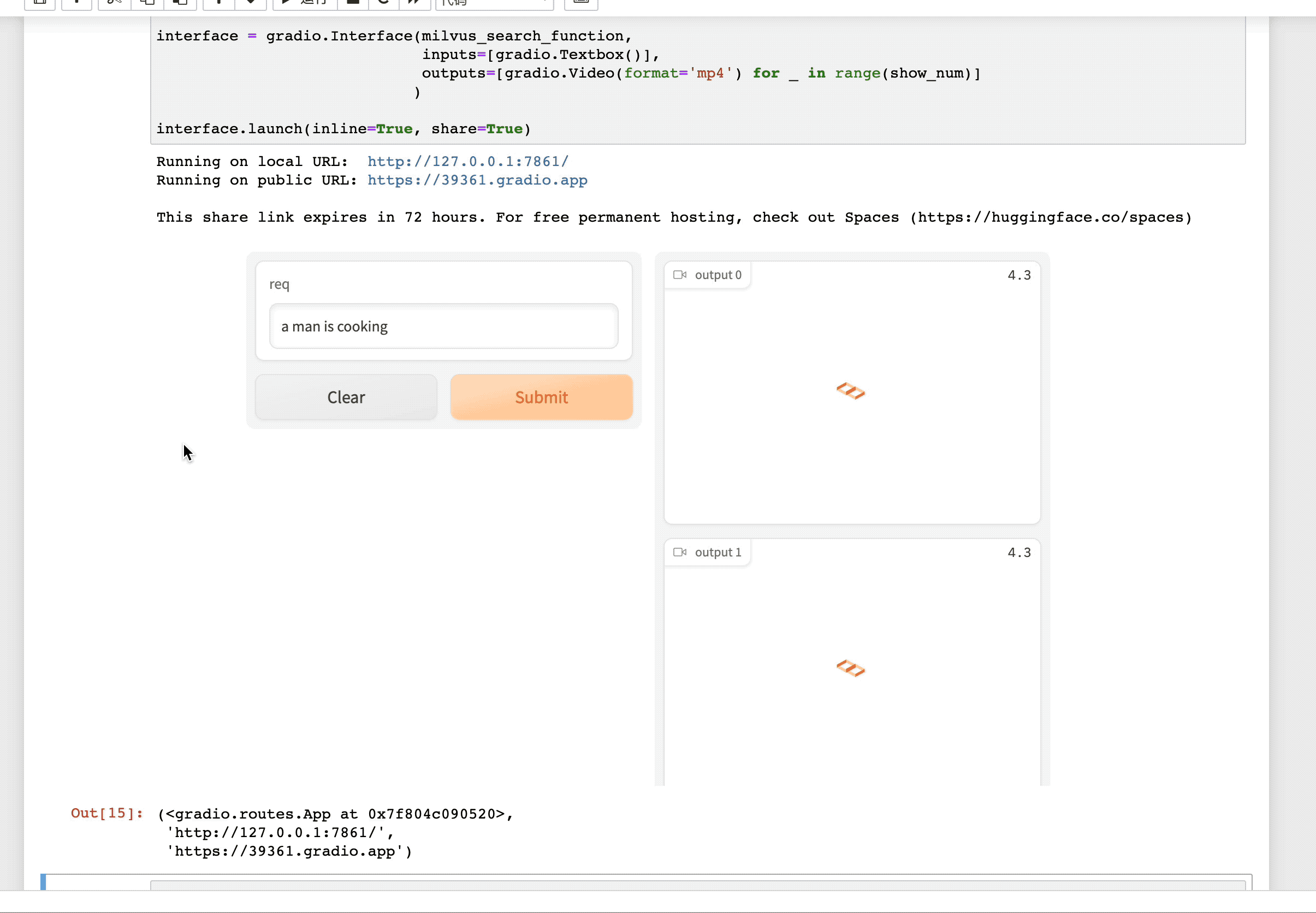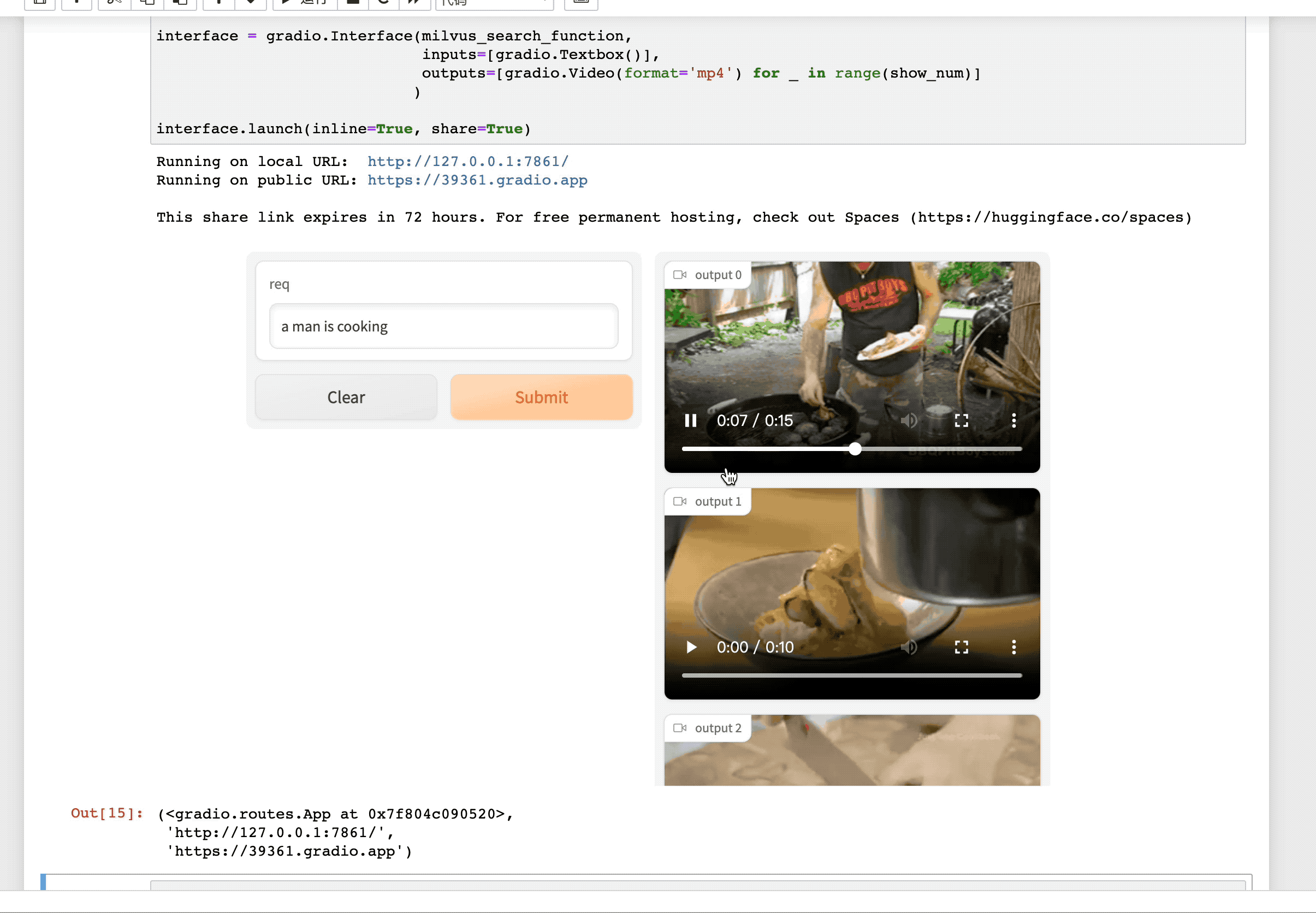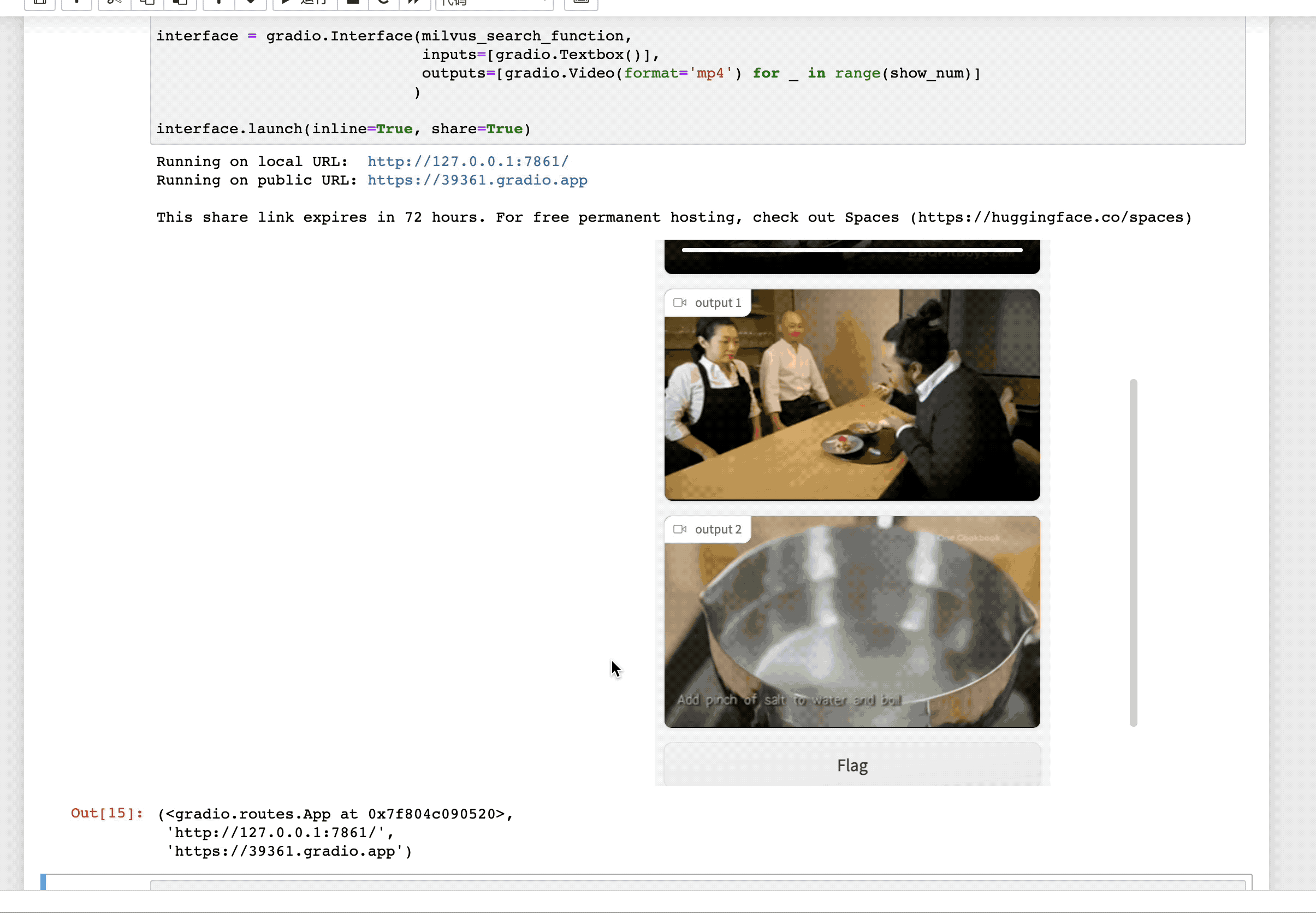
为了进一步验证我们GMIL模块对挑选有用视频活动信息的有效性,我们提供了可视化的检索效果图如下:
其中,上面的图为查询图片属于“冲浪”这一类别,下面的图为查询图片属于“踢球”这一类别。我们为每个查询图片列出了前2个检索到的视频。对于每个检索到的视频,我们将显示一个由GMIL模块学习出来的权重最高的图片序列,和另外两个权重最低的图片序列。
显然,我们可以看出权重最高的图片可以较好捕获到查询图片上相关活动内容,而其他两个图片序列的关联程度较低,甚至只是包含大量背景内容。由此表明,我们所提出来的GMIL模块在识别干净的视频信息方面上存在着巨大的优势。
总结
在本文中,我们提出了一种基于视频活动区域段表达的跨模态检索方法,特别地,图像特征和基于视频活动区域段的视频特征被投影到由基于几何投影的三元组损失函数,语义分类损失函数和对抗损失函数共同调整的特征空间中。
我们创新性地将基于图的多示例学习模块整合到跨模态检索框架中,以解决视频包信息的噪声问题,并利用基于几何投影的相似度度量方法。实验在基于行为和事件的三个数据集上进行,实验结果也证明了对比其他方法,我们的方法具有优越性。
图像与视频检索交流群
关注最新最前沿的图像、视频检索技术,扫码添加CV君拉你入群,(如已为CV君其他账号好友请直接私信)
(请务必注明:检索)
喜欢在QQ交流的童鞋,可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过验证还请见谅)
长按关注我爱计算机视觉