系列文章目录
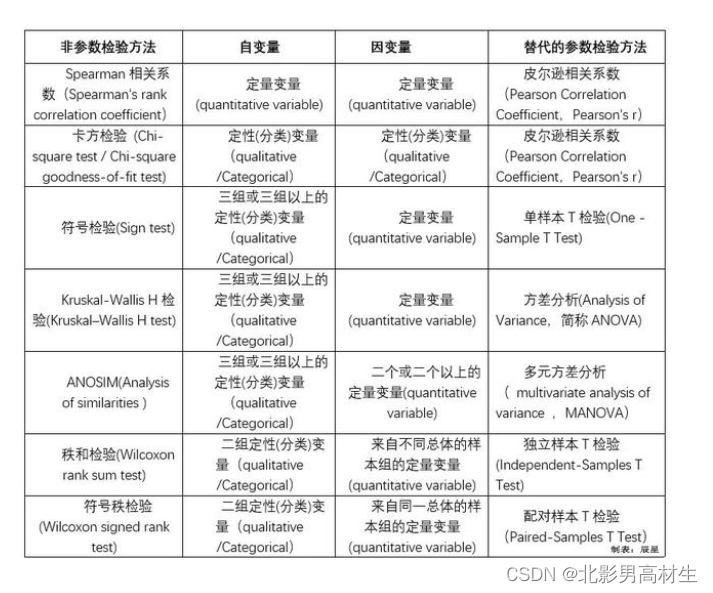
SPSS描述统计
SPSS均值检验
SPSS方差分析
文章目录
- 系列文章目录
- 前言
- 1 非参数检验提出的背景与特点
- 1.1 背景
- 1.2 特点
- 2 SPSS分析-非参数检验菜单中的相关功能
- 2.1 卡方检验
- 2.1.1 概述
- 2.1.2 操作流程
- 2.1.3 实例操作
- 2.2 二项分布检验
- 2.2.1 概述
- 2.2.2 操作流程
- 2.2.3 实例操作
- 2.3 游程检验
- 2.3.1 概述
- 2.3.2 操作流程
- 2.3.3 实例操作
- 2.4 单样本K-S检验
- 2.4.1 概述
- 2.4.2 操作流程
- 2.4.3 实例操作
- 2.5 两独立样本非参数检验
- 2.5.1 概述
- 2.5.2SPSS操作流程
- 2.5.3 实例介绍
- 2.6 多独立样本非参数检验
- 2.6.1 概述
- 2.6.2 SPSS操作流程
- 2.6.3 实例介绍
- 2.7 两配对样本非参数检验
- 2.7.1 概述
- 2.7.2 SPSS操作流程
- 2.7.3 实例介绍
- 2.8 多配对样本非参数检验
- 2.8.1 概述
- 2.8.2 SPSS操作流程
- 2.8.3 实例介绍
- 总结
前言
在实践中我们常常会遇到一些问题的总体分布并不明确,或者总体参数的假设条件不成立,不能使用参数检验。这一类问题的检验应该采用统计学中的另一类方法,即非参数检验。
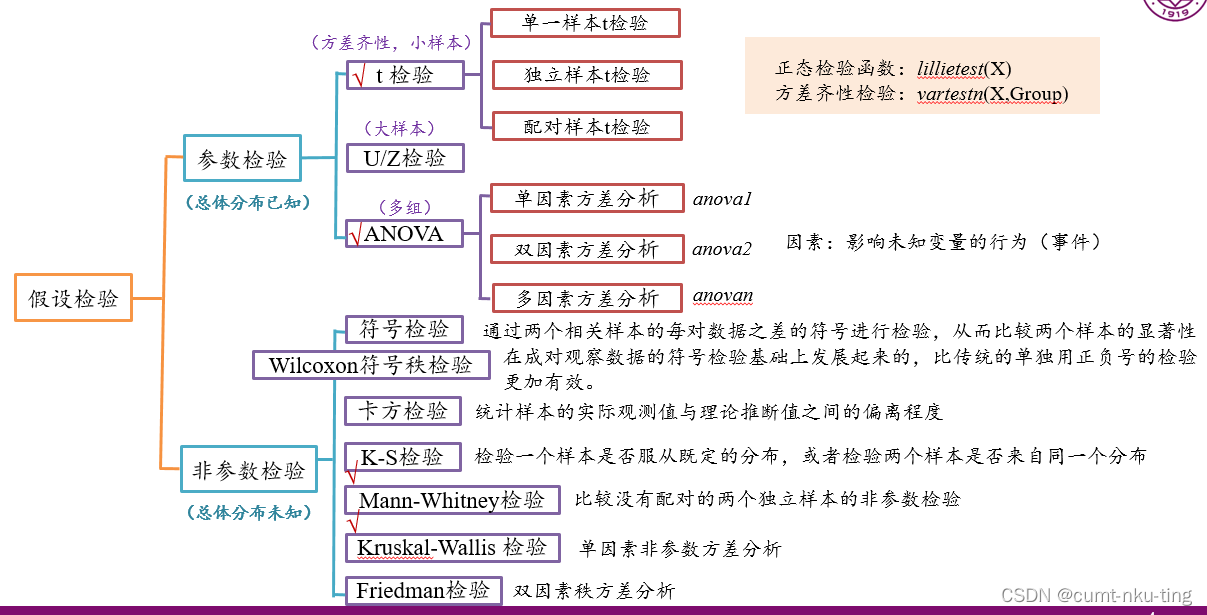
1 非参数检验提出的背景与特点
1.1 背景
非参数检验是不依赖总体分布的统计推断方法。它是指在总体不服从正态分布且分布情况不明时,用来检验数据资料是否来自同一个总体假设的一类检验方法。由于这些方法一般不涉及总体参数而得名。这类方法的假定前提比参数假设检验方法少得多,也容易满足,适用于计量信息较弱的资料且计算方法也简便易行,所以在实际中有广泛的应用。
1.2 特点
和参数方法相比,非参数检验方法的优势如下:
- 1.2.1稳健性。因为对总体分布的约束条件大大放宽,不至于因为对统计中的假设过分理想化而无法切合实际情况,从而对个别偏离较大的数据不至于太敏感。
- 1.3.2 对数据的测量尺度无约束,对数据的要求也不严格,什么数据类型都可以做。
- 1.3.3 适用于小样本、无分布样本、数据污染样本、混杂样本等。
- 参数检验和非参数检验的效率比较

2 SPSS分析-非参数检验菜单中的相关功能
SPSS 中进行非参数检验由分析菜单中的非参数检验菜单项导出。其中包括以下命令。
● Chi-square test: 卡方检验。
● Binomial test: 二项分布检验。
● Runs test: 游程检验。
● 1-Simple K-S test: 单样本K-S检验。
● 2 Independent Sample test: 两个独立样本非参数检验。
● K Independent Samples test: 多个独立样本非参数检验。
● 2 Related Sample test: 两个相关样本非参数检验。
● K Related Sample test: 多个相关样本非参数检验。
2.1 卡方检验
2.1.1 概述
1.使用目的
卡方检验(Chi-Squar Test)也称为卡方拟合优度检验,是K.Pearson给出的一种最常用的非参数检验方法。它用于检验观测数据是否与某种概率分布的理论数值相符合,进而推断观测数据是否是来自于该分布的样本的问题。
2.基本原理
进行卡方检验时,首先提出零假设 : 样本X来自的总体分布服从期望分布或某一理论分布。接着,利用实际观测值的频数与理论的期望频数之间的差异来构造检验统计量,它描述了观察值和理论值之间的偏离程度。
3.软件使用方法
SPSS会自动计算出χ2统计量及对应的相伴概率P值。
2.1.2 操作流程
- Step01:打开主菜单
选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Chi-Square(卡方)】命令,弹出【Chi-Square Test(卡方检验)】对话框。 - Step02:选择检验变量
在【Chi-Square Test(卡方检验)】对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,表示需要进行进行卡方检验的变量。 - Step03:确定检验范围
在【Expected Range(期望全距)】选项组中可以确定检验值的范围,对应有两个单选项。 - Step04:选择期望值
在【Expected Values(期望值)】选项组中可以指定期望值 ,对应有两个单选项。
2.1.3 实例操作
1.实例内容
某公司经营多年,形成了一套成熟的企业文化和管理体系,例如根据多年的运营经验,经理层、监察员、办事员三种职务类别人员比例大约在15:5:80为宜,这样运行效率最高。目前公司进行人事调整,公司人员结构发生变动,有员工担心是否人事调整已经导致职务类型比例的失调。
三种职务的期望构成比为15%、5%和80%。而目前样本中观察到的三种职务的人数比为84:27:363,构成比分别是17.7%、5.7%和76.6%,和理论值有差异。那么这种差异是由随机误差造成的,还是真的构成比和以前有所变化?该问题就可以用χ2检验来实现。相应的假设检验如下。
H0:目前三个职业的总体构成比仍然是15%、5%和80%。
H1:目前三个职业的总体构成比不再是15%、5%和80% 。
2.操作
- Step01:打开对话框
打开数据文件,选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Chi-Square(卡方)】命令,弹出【Chi-Square Test(卡方检验)】对话框。其中,“jobcat”变量表示职业类型, “1”表示办事员,“2”表示监察员,“3”表示经理。 - Step02:选择检验变量
在左侧的候选变量列表框中选择“jobcat”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
Step03:选择期望值
在【Expected Values(期望值)】选项组中点选【Values】单选钮,以指定期望概率值。接着在Values的文本框中分别输入0.8、0.05和0.15这三个数值,并且单击【Add】按钮加以确定。
Step04:完成操作
最后,单击【OK(确定)】按钮,操作完成。
3.结果分析
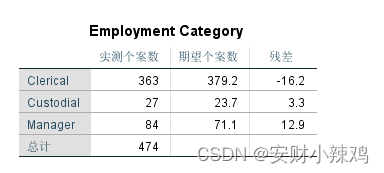
(1)频数表
SPSS的结果报告中列出了期望频数和实际频数。显然残差值越小,说明实际频数与期望频数越接近。
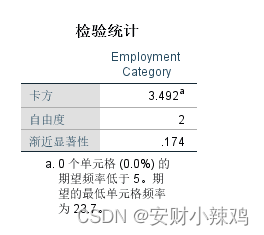
(2)卡方检验表
具体包括 统计量(Chi-Square)、自由度(df)和近似概率P值(Asymp. Sig.)。可见, 统计量等于3.492,自由度等于2,对应的概率P值0.174大于显著性水平0.05。因此接受零假设,认为目前三个职业的总体构成比仍然是15%、5%和80%,人数的调动只是随机误差造成的,公司人员结构没有显著性改变。
2.2 二项分布检验
2.2.1 概述
事件要服从二项分布,则应该具备下列基本的条件。
(1)各观察单位只能具有相互对立的一种结果。
(2)已知发生某一结果(阳性)的概率为π,其对立结果的概率为1-π。
(3)n次试验在相同条件下进行,且各个观察单位的观察结果相互独立,即每个观察单位的观察结果不会影响到其他观察单位的结果。
SPSS二项分布检验过程是推断总体的分布是否等于指定的某个二项分布。其假设检验过程如下。
H0:样本来自的总体与某个指定的二项分布无显著性差异。
H1:样本来自的总体与某个指定的二项分布有显著性差异。
SPSS会自动计算出二项分布检验相应的检验统计量及对应的概率P值。如果概率P值小于或等于用户设定的显著性水平,则拒绝零假设,认为总体与某个指定的二项分布有显著性差异;相反的,如果概率P值大于显著性水平,则接受零假设。
需要注意的是,二项分布检验过程要求变量必须是数值型的二元变量(只取两个可能值的变量)。假如变量是字符型的,可以使用重编码功能将其转化为数值型变量;假如变量不是二元变量,需要设置断点将数据分为两个部分,将大于断点值的归为一组,其余归为另一组。
2.2.2 操作流程
Step01:打开主菜单
选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Binomial(二项式)】命令 ,弹出【Binomial Test(二项式检验)】对话框。
Step02:选择检验变量
在【Binomial Test(二项式检验)】对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,表示需要进行进行二项分布检验的变量。
Step03:定义二元变量
在【Define Dichotomy(定义二分法)】选项组中可以定义二元变量。
Step04:指定检验概率值
在【Test Proportion(检验比例)】选项组中可以指定二项分布的检验概率值。系统默认的检验概率值是0.5,这意味着要检验的二项是服从均匀分布的。如果所要检验的二项分布不是同概率分布,参数框中要键入第一组变量所对应的检验概率值。
Step05:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法。
Step06:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step07:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.2.3 实例操作
1.实例内容
题目:灯泡是否合格
内容:某灯泡厂生产的一种特制灯泡按照工艺技术标准的要求,其合格灯泡的寿命必须大于960小时。通常在生产稳定的时候,该厂的这种产品合格品率为95%,为检验产品质量,今从新生产的一大批产品中随机抽查了30只灯泡,测得它们的寿命的数据资料,试根据这些样品数据检验该批产品的合格率是否等于95%。

2.操作
Step01:打开对话框
打开数据文件6-2.sav,选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Binomial(二项式)】命令,弹出【Binomial Test(二项式检验)】对话框。
Step02:选择检验变量
在左侧的候选变量列表框中选择“time”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
Step03:定义二元变量
在【Define Dichotomy(定义二分法)】选项组中点选
【Cut point(割点)】,以指定断点。接着在其文本框中输入“960”,表示以它作为分界点将原始样本分为两组。
Step04:指定检验概率值
在【Test Proportion(检验比例)】文本框中输入指定概率值“0.05”。
Step05:描述性统计量输出
单击【Options】按钮,弹出【Options(选项)】对话框。在【Statistics(统计量)】选项组中勾选【Descriptive(描述性)】和【Quartiles(四分位数)】复选框,表示输出基本统计量。再单击【Continue】按钮,返回【Binomial Test(二项式检验)】对话框。
3.结果分析
(1)基本统计量
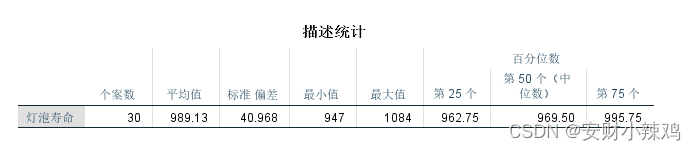
SPSS首先输出了样本的描述性统计量表。这里共选择了30个灯泡寿命样本作二项分布检验,灯泡的平均寿命等于989.13小时,标准差等于40.968小时,灯泡寿命最小值等于947小时,寿命最大值等于1084小时。同时其25%、50%和75%分位点等于 962.75、969.50和996.75小时。
(2)二项分布检验表
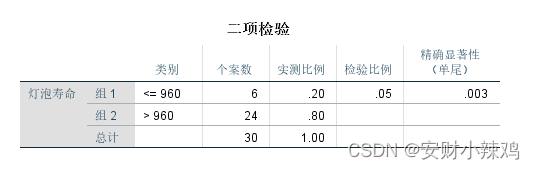
首先根据断点“960”将原始数据划分为两部分:“Group 1” 和“Group 2”,它们各自的样本容量等于6和24,所占总体的比例为20%和80%。由于这里要检验合格率是否等于95%,也就是要检验“Group 1”组所占比例是否等于0.05。但根据单尾概率P值(0.003)小于显著性水平 (0.05),可以判断这批样本的合格率不等于95%,即这批产品没有合格。
2.3 游程检验
2.3.1 概述
1.方法概述
游程检验是一种利用游程数所作的单样本随机性的检验方法,它可以用来判断观察值的顺序是否为随机。许多统计模型的假设中都要求观察值都是独立的,也就是说,收集到的数据样本的顺序是不相关的。如果样本顺序影响到统计结果,那么样本就可能不是随机的,这将使研究者不能得出关于抽样总体的准确结论。因此,研究者可以使用游程检验来检验数据的随机性。
2.3.2 操作流程
Step01:打开对话框
选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Runs(游程)】命令,弹出【Runs Test(游程检验)】对话框。
Step02:选择检验变量
在【Runs Test(游程检验)】对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,表示需要进行游程检验的变量。
Step03:确定断点
在【Cut point(割点)】选项组中指定计算游程数的分界值。小于分界值的观察值归为一组,其余的归为另一组,然后计算游程数。
Step04:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法,它的功能和卡方检验中的相应按钮相同的。
Step05:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.3.3 实例操作
- 实例内容
已知某企业在过去20年的盈亏情况为“0 0 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1”。其中“0”表示亏损,“1”表示盈利。现根据财务统计预测今年该企业盈利,请问这个结果对企业明年的经营状况有无影响? - 实例操作
根据过去20年的经营情况看到该企业的盈亏情况经常逐年发生变化。已知今年企业盈利,要判断明年企业的盈亏状态,其实就是要分析今年企业的盈利是否会对明年它的盈亏带来一定的影响。也就是说,要判断不同年份之间的盈亏情况有无影响性,即盈亏情况是否是随机的。这样就可以通过游程检验来分析历史数据。如果历史数据是随机的,说明今年的盈利不会对明年企业的生产产生影响;反之,表明今年的盈利会对明年生产有影响。所以采用SPSS具体操作步骤如下。
Step01:打开对话框打开数据文件,选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【Runs Test(游程检验)】命令,弹出【Runs Test(游程检验)】对话框。其中“x”变量表示企业盈亏状态,“0”表示亏损,“1”表示盈利。
Step02:选择检验变量
在候选变量列表框中选择“x”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
Step03:确定断点
在【Cut point(割点)】选项组中取消勾选【Median(中位数)】复选框,勾选【Mean(均值)】复选框。
3 .实例结果及分析
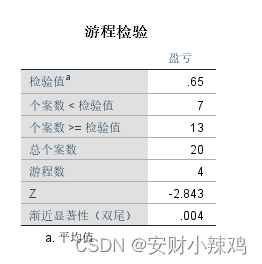
首先“Test Value=0.65”表示游程检验以0.65作为断点将原始数据分为两组。在过去20年中,企业亏损的年份数共有7年,而在剩下的13年里该企业都是盈利的。整个历史数据的游程数等于4。接着计算游程检验的Z统计量等于-2.843,相伴概率P值0.004显然小于显著性水平0.05。所以,认为企业盈亏历史数据并不是随机的,其中有一定的规律性。因此,今年企业的盈利会对明年企业的经营状况产生显著影响。
2.4 单样本K-S检验
2.4.1 概述
1.方法概述
K-S检验是以两位前苏联数学家柯尔莫哥(Kolmogorov)和斯米诺夫(Smirnov)命名的,是一种拟和优度的非参数检验方法。单样本K-S检验是利用样本数据推断总体是否服从某一理论分布,一般来说它是比卡方检验更精确的非参数检验法。
2.基本原理
K-S检验的理论分布可以为正态分布、均匀分布、指数分布和泊松分布等。其零假设是:样本来自的总体与指定的理论分布无显著差异。它的基本思想是:根据样本数据和用户的指定构造出理论分布,查分布表得到相应的理论累计概率分布函数F0(x);利用样本数据计算各样本数据点的累计概率,得到经验累计概率分布函数S0(x);计算S0(x)和F0(x)在相同变量值点x上的差D(x),得到差值序列D。单样本K-S检验主要对差值D序列进行研究。
3.软件使用方法
SPSS将自动计算K-S检验中的Z统计量,依据K-S分布表(小样本)或正态分布表(大样本)给出相应的相伴概率P值。如果P值小于或等于用户指定的显著性水平α,则拒绝原假设H0;反之,不能拒绝H0,可以认为样本来自的总体与指定的分布无显著差异。
2.4.2 操作流程
Step01:打开对话框
选择菜单栏中的【Analyze(分析)】→【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【1-samples K-S(1样本K-S(1))】命令,弹出 【One-Sample K-S Test(单样本K-S检验)】对话框,这是K-S检验的主操作窗口。
Step02:选择检验变量
在【One-Sample Kolmogorov-Smirnov Test(单样本K-S检验)】对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,表示需要进行K-S检验的变量。
Step03:选择待检验理论分布
在【Test Distribution(检验分布)】选项组中,用户需要选择待检验的理论分布。系统提供了四种统计中常见的分布。
Step04:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法,它的功能和卡方检验中相关按钮是相同的。
Step05:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.4.3 实例操作
1 .实例内容
零售商希望了解某商品销售收益(Revenue)的大致分布情况。依据其他销售商已有的资料,他认为其销售收益可能服从正态分布。为了检验其假设,考虑是否与其他零售商一样,销售收益服从正态分布,收集到相关的销售收益数据,请使用SPSS软件分析样本数据是否服从正态分布。
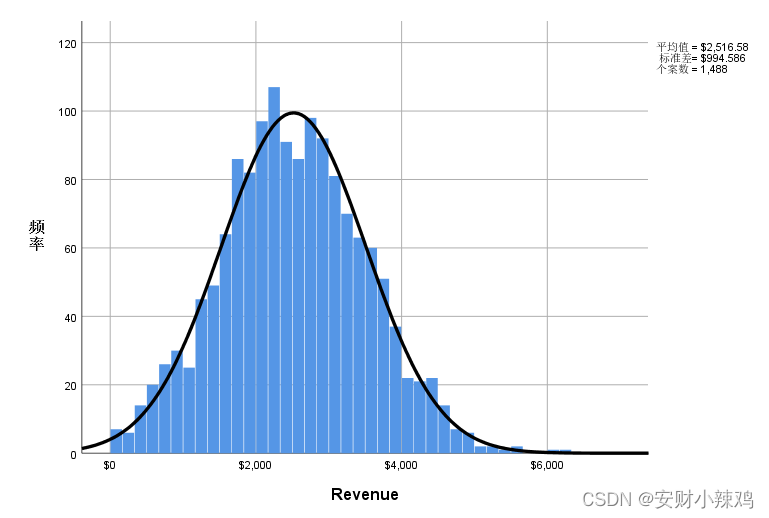
Step01: 本案例的目的就是要检验文件中的“revenue”变量是否服从正态部分,因此可以采用非参数K-S检验来判断。首先,通过描述性统计功能绘制了“revenue”变量的直方图及其拟合的正态曲线。从图形特征看到,“revenue”变量的分布非常接近正态分布,但需要采用K-S检验来诊断。
Step02:选择检验变量
在候选变量列表框中选择“revenue”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
提示:可以在【Test Distribution(检验分布)】选项组中选择检验分布类型;系统默认为正态分布。
Step03:确定断点
单击【Options】按钮,在弹出的对话框的【Statistics(统计量)】选项组中勾选【Descriptive(描述性)】和【Quartiles(四分位数)】复选框,表示输出基本统计量。单击【Continue】按钮返回主对话框。
3. 实例结果及分析
(1)曲线拟合
(2)描述统计
SPSS首先给出了“revenue”变量的基本统计量。样本总数N等于1488,收益均值等于$2,516.58,收益标准差等于$994.586,收益最小值和最大值分别是$13和$6,213,收益25%、50%和75%的分位数是$1,830.96、$2,490.68和$3,183.54。
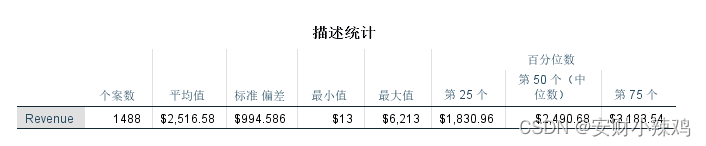
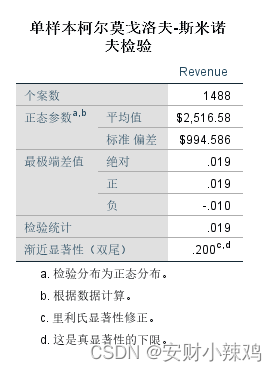
(3)K-S检验结果表
给出了原假设:销售收益服从均值为2516.58、标准差为994.586的正态分布。给出了K-S检验关键结果:实际分布和检验分布之间的正向最大频数差为0.019,负向最大频数差为-0.010,因此用于计算统计量的绝对值最大频数差为0.019。随后的K-S统计量Z值等于0.75,相应的概率P值为0.627,大于显著性水平0.05。所以接受零假设,认为该厂商的销售收益服从正态分布。
2.5 两独立样本非参数检验
2.5.1 概述
1.方法概述
两独立样本的非参数检验是在对总体分布不甚了解的情况下,通过分析样本数据,推断样本来自的两个独立总体的分布是否存在显著差异。这种检验方法一般通过独立总体的均值或中位数是否存在显著差异来推断。关于样本之间是否独立,主要看在一个总体中抽取样本对在另一个总体中抽取样本有无影响。如果没有影响,则可以认为这两个总体是独立的。
2.基本原理
SPSS提供了四种相关的非参数检验方法:曼-惠特尼U检验、K-S检验、极端反应检验、游程检验。
2.5.2SPSS操作流程
Step01:打开主菜单
选择菜单栏中的【Analyze(分析)】→【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【2 Independent Samples(2个独立样本)】命令,弹出【Two-Independent-Samples Tests(两个独立样本检验)】对话框。
Step02:选择检验变量
在【Two-Independent-Samples Tests(两个独立样本检验)】对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,这里表示需要进行两独立样本检验的变量。
Step03:选择分组变量
在【Two-Independent-Samples Tests(两个独立样本检验)】对话框左侧的候选变量中选择分组变量,将其添加至【Grouping Variable(s)(分组变量)】文本框中,目的是要区分检验变量的不同组别。单击 【Grouping Variables】按钮,在弹出的对话框的【Group1(组1)】和【Group2(组2)】文本框中分别输入整数值,这两个值确定的分组将选择的检验变量的观测值分为两组或者分成两个样本,并将检验变量的其他数值排除在检验分析之外。设置完成后,单击【Continue】按钮,返回主对话框。
Step04:选择检验方法
在【Test Type(检验类型)】选项组中,用户需要选择两独立样本检验的方法。系统提供了四种常用方法: Mann-Whitney U(曼-惠特尼U检验)、 Kolmogorov-Smirnov Z(K-S检验)、Moses Extreme Reactions(极端反应检验)和Wald-Wolfwitz Runs(游程检验)。
Step05:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法。
Step06:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step07:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.5.3 实例介绍
- 实例内容
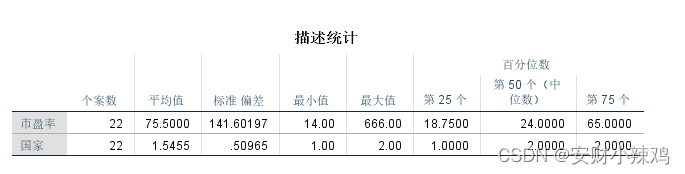
一个公司的市盈率是指这家公司股票的当前价格除以最近12个月的每股收益。下表列出了10家日本公司和12家美国公司的市盈率,这两个国家公司的市盈率之间是否存在显著差异?

本案例的目的就是要检验日本和美国公司的市盈率是否有显著差异。由于这里样本量较少,难以确定这两个总体的分布,因此可以引入非参数的检验方法。由于讨论的两个样本相互独立,故引入两独立样本非参数检验方法。于是建立如下假设检验。
H0 :日本公司和美国公司的市盈率没有显著差异。
H1 :日本公司和美国公司的市盈率存在显著差异。
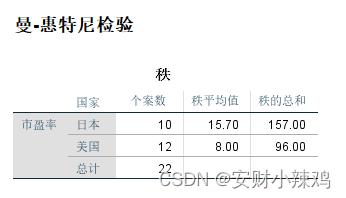
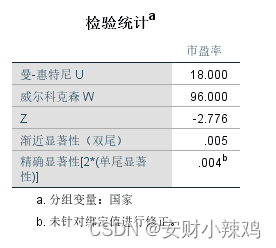
主要是比较日本和美国公司的平均市盈率是否相同,所以采用曼-惠特尼U检验方法。
2.操作步骤
Step01:打开对话框
打开数据文件6-6.sav,选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【2 Independent Samples(2个独立样本)】命令,弹出如下图所示的对话框。
Step02:选择检验变量
在左侧的候选变量列表框中选择“PE”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
Step03:选择分组变量
选择分组变量x,将其添加至【Grouping Variable(s)(分组变量)】文本框中。
Step04:确定分组标号
单击【Grouping Variables】按钮,弹出相应对话框,在【Group1(组1)】文本框中输入“1”,在【Group2(组2)】文本框中输入“2”,分别表示分组的标号。输入完成后,单击【Continue】按钮返回主对话框。
3.结果分析
(1)描述性统计量
(2)曼-惠特尼U检验的秩统计表
2.6 多独立样本非参数检验
2.6.1 概述
1.方法概述
多独立样本的非参数检验是通过分析多组独立样本数据,推断样本来自的多个总体的分布是否存在显著差异。这里样本间的独立是指在一个总体中抽取样本对在其他总体中抽取样本无影响。
2.基本原理
SPSS提供的多独立样本非参数检验的方法主要包括:Kruskal-Wallis H检验、中位数检验(Median检验、Joneckheere-Terpstra检验。
2.6.2 SPSS操作流程
Step01:打开对话框
选择菜单栏中的【Analyze(分析)】→【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【K Independent Samples(K个独立样本)】命令,弹出【Tests for Several Independent Samples(多个独立样本检验)】对话框,这是多独立样本非参数检验的主操作窗口。
Step02:选择检验变量
在主对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Variable List(检验变量列表)】列表框中,这里表示需要进行多独立样本检验的变量。
Step03:选择分组变量
在主对话框左侧的候选变量中选择分组变量,将其添加至【Grouping Variable(s)(分组变量)】文本框中,目的是要区分检验变量的不同组别。单击【Grouping Variables】按钮,弹出如下图所示的对话框。在【Minimum(最小值)】和【Maximum(最大值)】文本框中分别键入最小值和最大值,这两个值之间的整数值将检验变量的观测值分为若干个样本,并将其他数值排除在检验分析之外。设置完成后,单击【Continue】按钮,返回主对话框。
Step04:选择检验方法
在【Test Type(检验类型)】选项组中,用户需要选择多独立样本检验的方法。系统提供了三种常用方法: Kruskal-Wallis H(克鲁斯凯-沃里斯 H检验)、Median(中位数检验)和Joneckheere-Terpstra(J-T检验)。
Step05:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法。
Step06:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step07:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.6.3 实例介绍
实例分析:糖果中的卡路里
1 .实例内容
畅销的糖果往往含有较高的卡路里。假设下表中的数据为三种不同糖果样本中的卡路里含量,检验这三种糖果中的卡路里含量的显著差异。
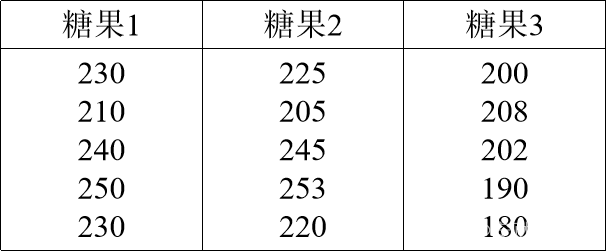
本案例的目的就是要检验这三种糖果中的卡路里含量有没有显著性差异。由于这里样本量较少,难以确定总体的分布,因此可以引入非参数的检验方法。由于三种糖果的卡路里含量独立,故引入多独立样本非参数检验方法。于是建立如下假设检验。
H0 :三种糖果的卡路里含量没有显著差异。
H1 :三种糖果的卡路里含量存在显著差异。
2 步骤
Step01:打开数据文件6-7sav,其中“calories”变量表示糖果中卡路里的含量;“x”变量表示糖果类型,分别用1-3表示。选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【K Independent Samples(K个独立样本)】命令,弹出如下图所示的对话框。提示:可以在【Test Type(检验类型)】选项组中选择检验方法。
Step02:选择检验变量
在左侧的候选变量列表框中选择“calories”变量作为检验变量,将其添加至【Test Variable List(检验变量列表)】列表框中。
Step03:选择分组变量
选择分组变量x,将其添加至【Grouping Variable(s)(分组变量)】文本框中。
Step04:确定分组标号。单击【Grouping Variables】按钮,弹出相应对话框,如图6-35所示。在【Minimum(最小值)】文本框中输入“1”,在【Maximum(最大值)】文本框中输入“3”,分别表示分组的最小标号和最大标号。输入完成后,单击【Continue】按钮返回。
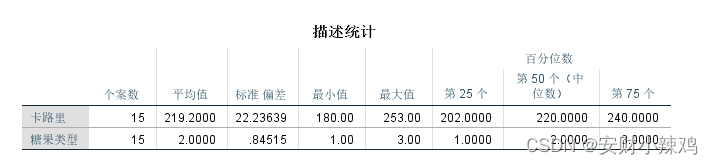
3 结果分析
(1)描述性统计量
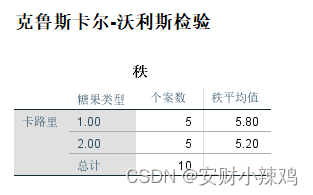
(2)秩统计表
(3)非参数检验结果表
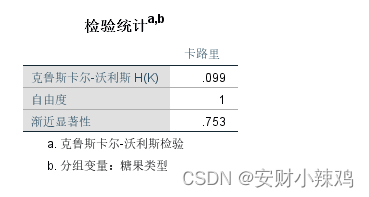
2.7 两配对样本非参数检验
2.7.1 概述
1.基本原理
两配对样本的非参数检验是在对两组配对样本的总体分布不甚了解的情况下,推断样本来自的两个总体的分布等是否存在显著差异的方法。这种检验对两个总体服从的分布不做要求,但要求数据必须是成对出现的,而且顺序不能够随意调换。下面简要介绍常用的四种检验方法:符号检验、Wilcoxon符号秩检验、 McNemar检验、 Marginal Homogeneity检验 。
2.7.2 SPSS操作流程
Step01:打开对话框
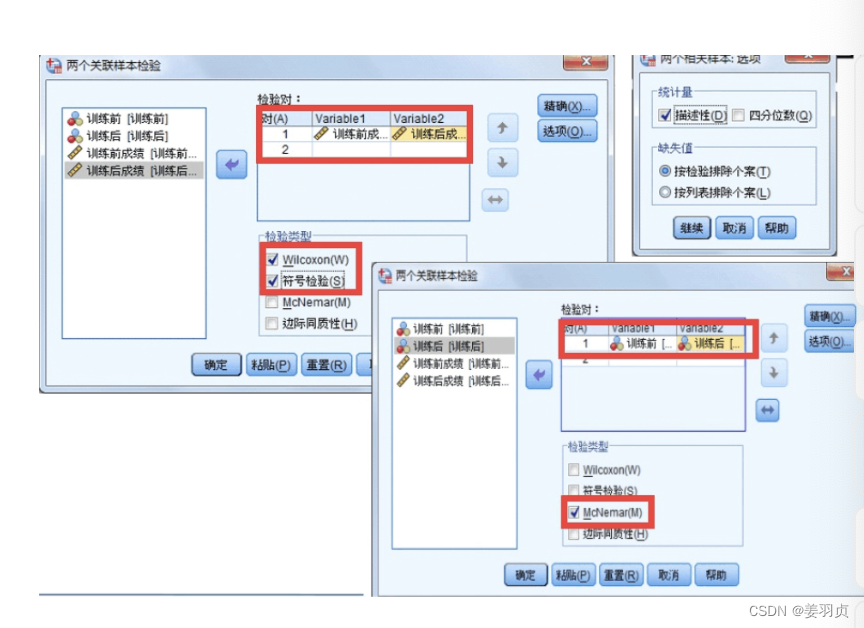
选择菜单栏中的【Analyze(分析)】→【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【2 Related Samples(2个相关样本)】命令,弹出【Two-Related-Samples Tests(两个关联样本检验)】对话框,这是两配对样本非参数检验的主操作窗口。
Step02:选择检验变量
在主对话框左侧的候选变量列表框中选择变量,将其添加至【Test Pairs(检验对)】列表框中。需注意的是,由于是进行配对检验,所以检验变量要成对添加至【Test Pairs(检验对)】列表框。
Step03:选择检验方法
在【Test Type(检验类型)】选项组中,用户需要选择两配对样本检验的方法。系统提供了四种常用方法:Wilcoxon符号秩检验、符号检验、McNemar检验、Marginal Homogeneity检验。
Step04:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法。
Step05:其他选项选择
【Options】按钮用于指定输出内容和关于缺失值的处理方法。
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
实例分析:音乐与入睡时间
2.7.3 实例介绍
- 实例内容
在关于放松(听音乐)对成年女性入睡所需时间影响的研究中,抽取了10名女性组成样本。下表给出了10个对象在有听音乐和不听音乐下入睡所需的时间(min)。就此数据你的结论是什么?
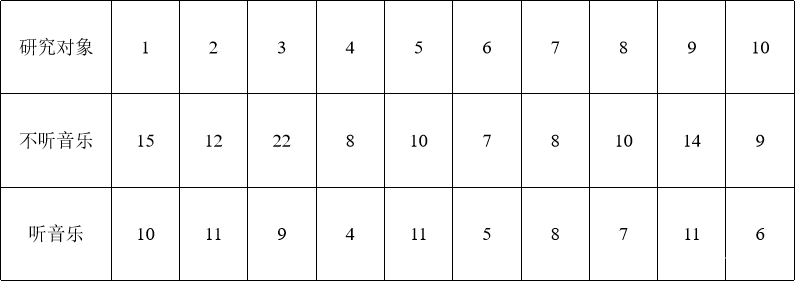
2 .实例操作
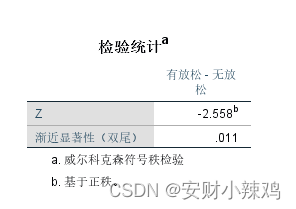
案例要分析听音乐是否会影响成年人的入睡时间,于是选择了10名女性,对她们分别进行听音乐和不听音乐两种条件下的入睡时间检测。由于选择的样本是相同的,因此表中的两组样本是成对数据。由于这里样本量较少,难以确定总体的分布,因此可以引入非参数的检验方法。故引入两配对样本非参数检验方法。同时这里的数据是连续性数据,故采用Wilcoxon符号秩检验。于是建立如下假设检验。
H0 :听音乐和不听音乐两种条件下入睡时间没有显著差异。
H1 :听音乐和不听音乐两种条件下入睡时间存在显著差异。
Step01:打开对话框
打开数据文件6-8.sav。选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【2 Related Samples(2个相关样本)】命令,弹出 【Two-Related-Samples Tests(两个关联样本检验)】对话框
Step02:在左侧的候选变量列表框中同时选择“x”变量和“y”变量作为成对检验变量,将其同时添加至【Test Pairs(检验对)】列表框中
提示:可以在【Test Type(检验类型)】选项组中选择检验方法。
Step03:单击【Options】按钮,在弹出的对话框的 【Statistics(统计量)】选项组中勾选【Descriptive(描述性)】和【Quartiles(四分位数)】复选框,表示输出基本统计量。再单击【Continue】按钮,返回主对话框。
(1)描述统计量表
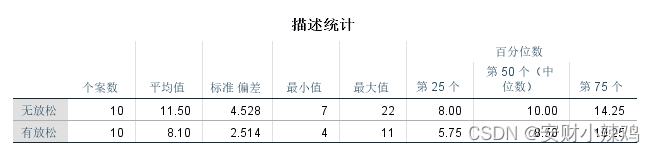
(2)秩统计表
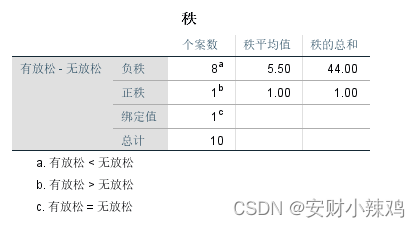
(3)非参数检验结果表
2.8 多配对样本非参数检验
2.8.1 概述
1 .基本原理
多配对样本的非参数检验是用来比较多个配对总体分布是否相同的非参数检验方法。这种检验方法对总体分布也没有要求,但样本必须是配对的,也不能更改其顺序。下面简要介绍常用的三种检验方法:Friedman检验 、Kendall协和系数检验、Cochran检验.
2.8.2 SPSS操作流程
Step01:打开对话框
选择菜单栏中的【Analyze(分析)】→【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【K Related Samples(K个相关样本)】命令,弹出【Tests for Sevearl Related Samples(多个关联样本检验)】对话框,这是多配对样本非参数检验的主操作窗口。
Step02:选择检验变量
在主对话框左侧的候选变量列表框中选择一个或几个变量,将其添加至【Test Pairs(检验对)】列表框中,这里表示需要进行多配对样本检验的变量。
Step03:选择检验方法
在【Test Type(检验类型)】选项组中,用户需要选择两配对样本检验的方法。
Step04:选择计算精确概率
【Exact】按钮用于选择计算概率P值的方法。
Step05:其他选项选择
【Statistics】按钮用于指定输出内容和关于缺失值的处理方法。
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果。
2.8.3 实例介绍
1 实例内容
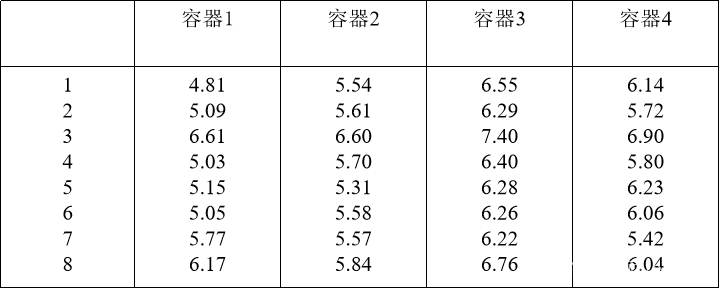
使用4种不同的容器存放果汁,经过半年的存放以后,请8位品尝员品尝,每位品尝员都给这4种容器存放的果汁的味道打分,得到的数据如下表。请分析这4种容器果汁味道的差异。
2. 实例操作
要研究不同果汁味道的差异,但这里涉及到四位品尝员的打分。由于他们都品尝了相同的果汁,因此表6-23中的数据是配对给出的。由于这里样本量较少,难以确定总体的分布,因此可以引入非参数的检验方法。同时这里的数据是连续性数据,故采用Friedman和Kendall’s W检验。于是建立如下假设检验。
H0 :四种果汁味道没有显著差异。
H1 :四种果汁味道存在显著差异。
Step01:打开数据文件6-9…sav,其中“vessel1”、“vessel2”、“vessel3”和“vessel4”变量分别表示四种容器果汁味道的分数。选择菜单栏中的【Analyze(分析)】 →【Nonparametric Tests(非参数检验)】→【Legacy Dialogs(旧对话框)】→【2 Related Samples(2个相关样本)】命令,弹出【K Related
Samples(K个相关样本)】对话框。
Step02:选择检验变量
在左侧的候选变量列表框中同时选择“vessel1”、“vessel2”、“vessel3”和“vessel4”变量作为配对检验变量,将其同时添加至【Test Variables】列表框中。
Step03:选择检验方法
在【Test Type(检验类型)】选项组中勾选【Friedman】和【Kendall’s W】复选框,作为配对样本检验的方法。
Step04:输出描述性统计量
单击【Options】按钮,在弹出的对话框的【Statistics(统计量)】选项组中勾选【Descriptive(描述性)】和【Quartiles(四分位数)】复选框,表示输出基本统计量。再单击【Continue】按钮,返回主对话框。
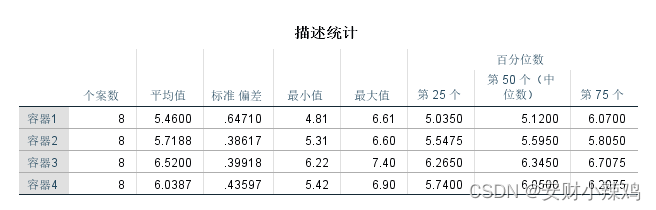
(1)描述统计量表
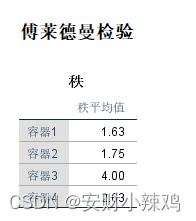
(2)秩统计表
(3) Friedman统计表
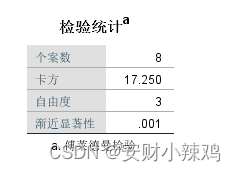
(4)Kendall协和系数统计表
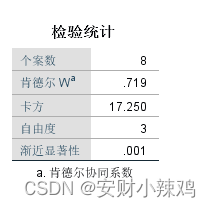
总结
以上就是今天要讲的内容,本文详细介绍了各种非参数检验以及其使用,利用SPSS的非参数检验模块实现,有利于对非参数检验的理解。