一、前言
- 本篇文章带大家一起编译hue、并使用hue适配livy+spark,通过结合Hue、Livy和Spark SQL,可以在一个友好的Web界面中编写和执行SQL查询,并在远程的Spark集群上运行。
1、Hue 介绍
- Hue (Hadoop User Experience)是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,其基于Python Web框架Django实现。Hue为KMR集群提供了图形化用户界面,便于用户配置、使用以及查看KMR集群。hue官网、Github
- 访问HDFS和文件浏览
- 通过web调试和开发hive以及数据结果展示
- solr查询、结果展示、报表生成
- 通过web调试和开发impala交互式SQL Query
- spark调试和开发
- Pig开发和调试
- oozie任务的开发、监控和工作流协调调度
- Hbase数据查询和修改、数据展示
- Hive的元数据(metastore)查询
- MapReduce任务进度查看,日志追踪
- 创建和提交MapReduce,Streaming,Java job任务
- Sqoop2的开发和调试
- Zookeeper的浏览和编辑
- 数据库(MySQL、PostgreSQL、SQlite,Oracle)的查询和展示
2、livy 介绍
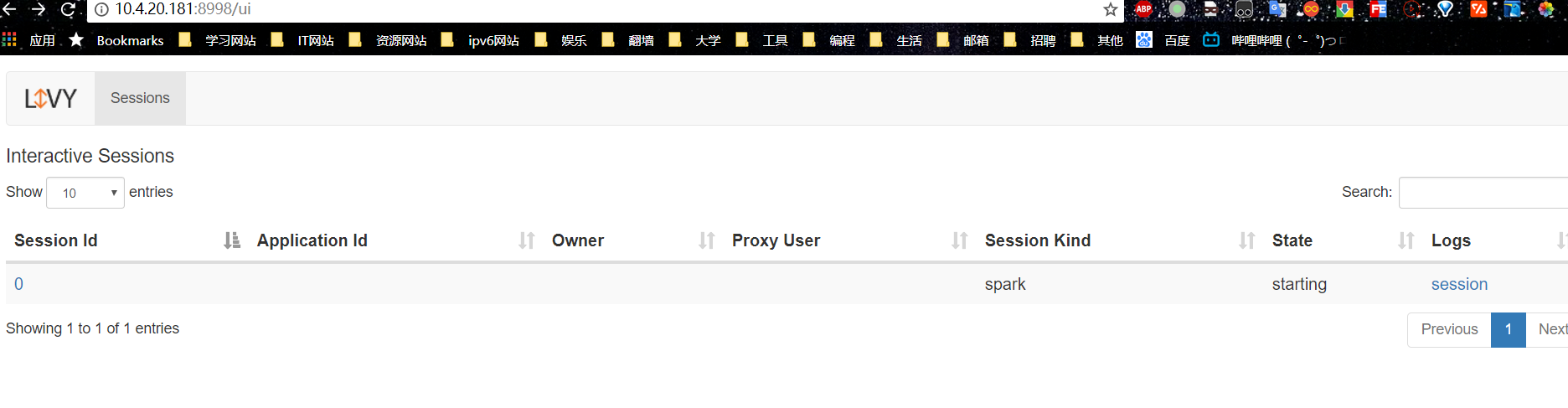
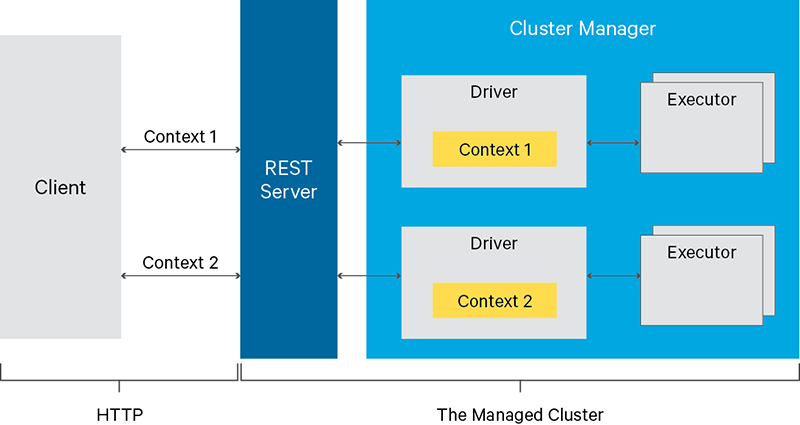
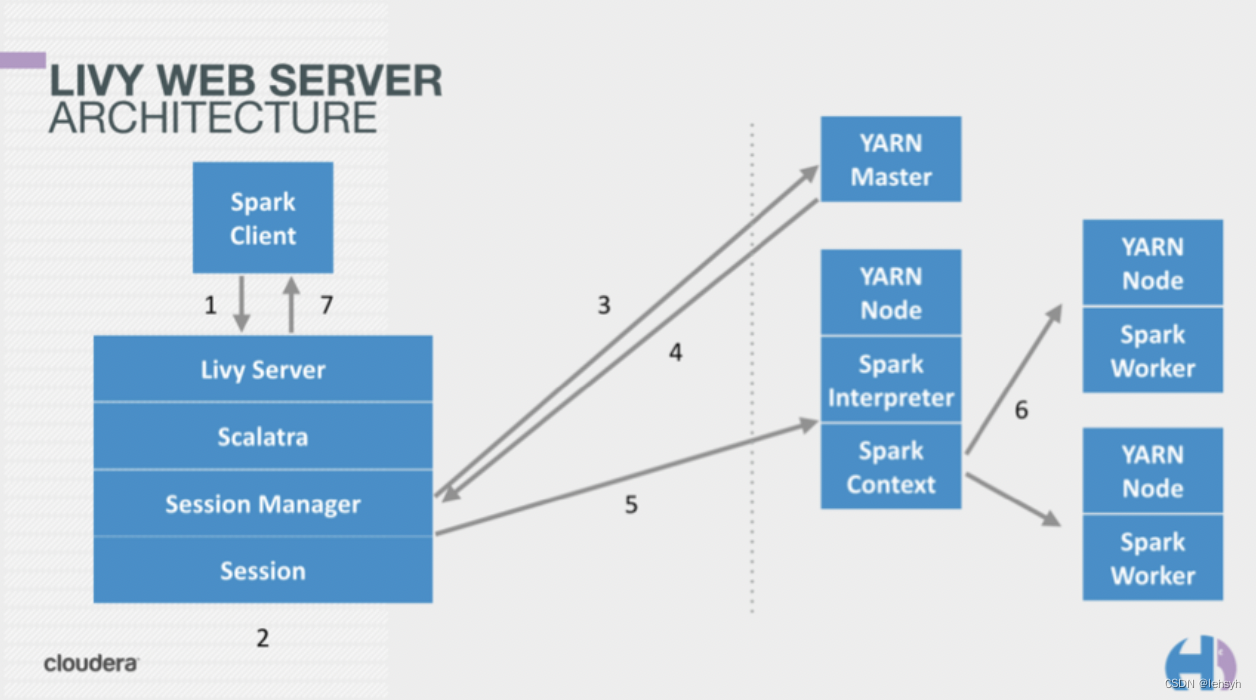
- Apache Livy是 一个可以通过REST接口轻松的与Spark集群进行交互的服务,它可以很方便提交Spark作业或者Spark代码,同步或者异步的进行结果检索以及Spark Context上下文管理, Apache Livy还简化了Spark和应 用程序服务器之间的交互,从而使Spark能够用于交互式Web移动应用程序。livy 官网、Github
二、编译安装Hue
| 名称 | 版本 |
|---|---|
| hue | 4.10 |
| livy | 0.8 |
| Spark | 3.2.1 |
考虑到编译比较繁琐复杂,已将相关编译好的包放在网盘,需要可以自取。
链接:https://pan.baidu.com/s/1BOsnKKwKmTohSGbzi-3QpQ
提取码:C3hp
1、安装依赖包
Hue依赖于许多软件包,需要在安装Hue之前安装这些软件包。
yum install \
ant \
asciidoc \
cyrus-sasl-devel \
cyrus-sasl-gssapi \
cyrus-sasl-plain \
gcc \
gcc-c++ \
krb5-devel \
libffi-devel \
libxml2-devel \
libxslt-devel \
make \
mysql \
mysql-devel\
openldap-devel \
python-devel \
sqlite-devel \
gmp-devel \
npm
2、编译Hue
到hue安装目录下,执行make。
-
make apps
其把安装包都打到当前的源码包中,如果迁移安装包,就需要把当前整个包都打包在一块,这样会造成安装包冗余大量的源码数据。 -
PREFIX=/data/hue-4.10 make install
如果有迁移安装包的需求,一定要注意安装包的路径,因为hue中一些依赖使用了绝对路径,所以在迁移安装包的时候,尽量保证路径不变。 -
编译成功后Hue可在编译机启动。如果需要在其他机器部署,需要将/data/hue-4.10目录打包压缩后复制到目标机器。尽量保证路径不变。
-
编译结束后可以输入echo $?查看状态码,若为0则编译成功:
3、遇到的问题
每一次编译过程如果出现问题,在重新编译前尽量make clean一下,避免上次的错误的编译安装残留影响后面的重新安装。
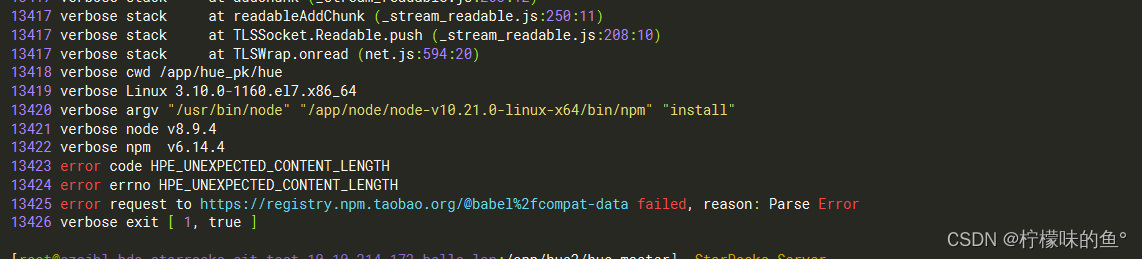
1. npm下载不下来
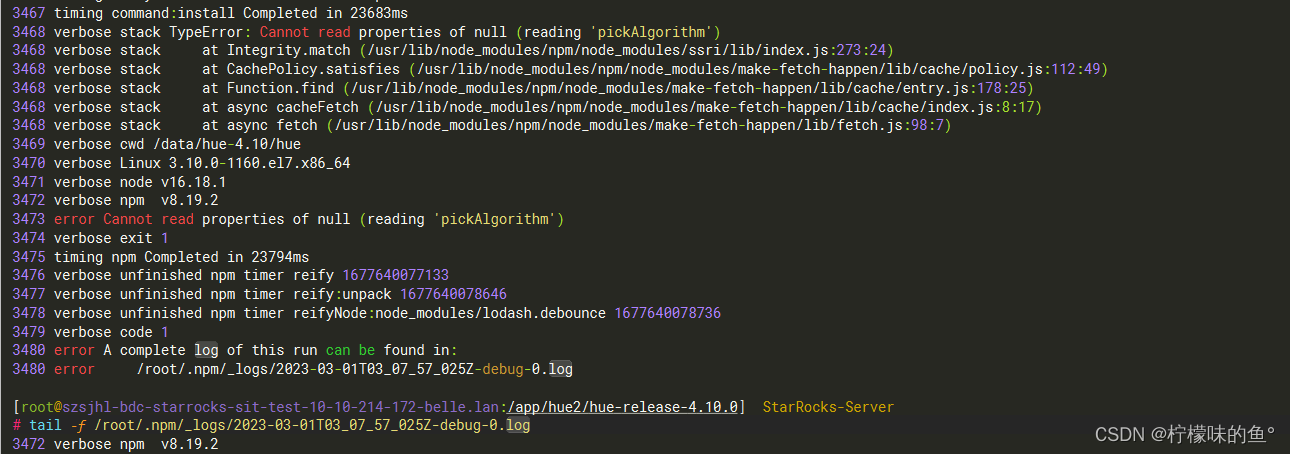
解决方式:npm默认镜像源为国外地址,所以下载会很慢或者下不下来,所以可以通过修改npm下载的镜像源为国内淘宝镜像源进行解决。
npm config set proxy null 清空代理npm cache clean --force 清空缓存npm config set registry https://registry.npm.taobao.org 设置代理
2. nodejs版本问题
- 其出现的原因是nodejs 18版本及以上涉及最新底层操作系统相关的包。所以在安装nodejs的时候,推荐使用18以下的版本。
三、配置Hue
- 将上一步编译打包后的Hue解压在目标机器/data/hue-4.10/。然后配置/data/hue-4.10/hue/desktop/conf/pseudo-distributed.ini
- 复制出一份配置文件
cp /data/hue-4.10/hue/desktop/conf/pseudo-distributed.ini.tmpl /data/hue-4.10/hue/desktop/conf/pseudo-distributed.ini
- 编辑配置文件,完整配置文件如下,可参考(MySQL元数据同步、HDFS文件浏览集成、livy集成、Hive集成、impala集成、yarn集成、LDAP等)
vim /data/hue-4.10/hue/desktop/conf/pseudo-distributed.ini[desktop]
secret_key=ZT0kMfPMbzRaHBx
http_host=0.0.0.0
http_port=8887
time_zone=Asia/Shanghai
app_blacklist=pig,zookeeper,hbase,oozie,indexer,jobbrowser,rdbms,jobsub,sqoop,metastore
django_debug_mode=false
http_500_debug_mode=false
cherrypy_server_threads=50
default_site_encoding=utf
collect_usage=false
enable_prometheus=true
[[django_admins]]
[[custom]]
[[auth]]
backend=desktop.auth.backend.LdapBackend
idle_session_timeout=600
[[[jwt]]]
[[ldap]]
ldap_url=ldap://ldap.cdh.com
ldap_username_pattern="uid=<username>,ou=People,dc=server,dc=com"
use_start_tls=false
search_bind_authentication=false
create_users_on_login=true
base_dn="ou=People,dc=server,dc=com"
bind_dn="cn=Manager,dc=server,dc=com"
bind_password="eFRrECKfQfoOB25"
[[[users]]]
[[[groups]]]
[[[ldap_servers]]]
[[vcs]]
[[database]]
engine=mysql
host=192.168.37.100
port=3306
user=hue
password=6a3ZsJtNs8SSCLe
name=hue_10
[[session]]
[[smtp]]
host=localhost
port=25
user=
password=
tls=no
[[knox]]
[[kerberos]]
[[oauth]]
[[oidc]]
[[metrics]]
[[slack]]
[[tracing]]
[[task_server]]
[[gc_accounts]]
[[[default]]]
[[raz]]
[notebook]
show_notebooks=true
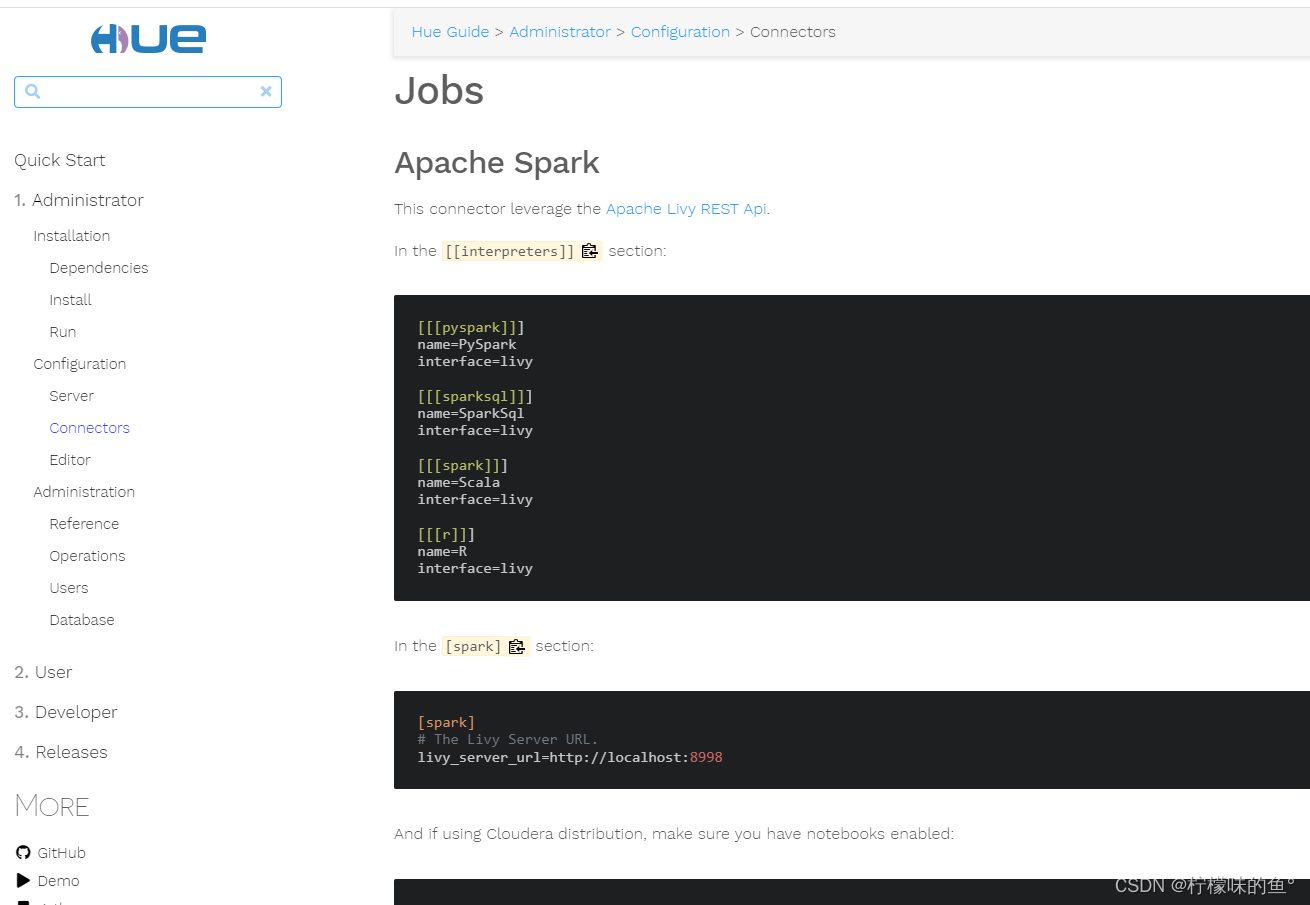
[[interpreters]][[[hive]]]
name=Hive
interface=hiveserver2[[[impala]]]
name=Impala
interface=hiveserver2[[[sparksql]]]
name=SparkSql
interface=livy[[[pyspark]]]
name=PySpark
interface=livy[dashboard]
is_enabled=true
[[engines]]
[hadoop]
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://nameservice1
webhdfs_url=http://192.168.37.20:14000/webhdfs/v1
hadoop_bin=/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hadoop/bin/hadoop
security_enabled=false
temp_dir=/tmp
[[yarn_clusters]]
[[[default]]]
resourcemanager_host=192.168.37.1
resourcemanager_api_url=http://192.168.37.1:8088/
proxy_api_url=http://192.168.37.1:8088/
resourcemanager_port=8032
logical_name=yarnRM
history_server_api_url=http://192.168.37.1:19888/
security_enabled=false
submit_to=true
hadoop_mapred_home=/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hadoop-mapreduce
hadoop_bin=/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hadoop/bin/hadoop
[[[ha]]]
resourcemanager_host=192.168.37.20
resourcemanager_api_url=http://192.168.37.20:8088/
proxy_api_url=http://192.168.37.20:8088/
resourcemanager_port=8032
logical_name=yarnRM
history_server_api_url=http://192.168.37.1:19888/
security_enabled=false
submit_to=true
hadoop_mapred_home=/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hadoop-mapreduce
hadoop_bin=/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hadoop/bin/hadoop
[beeswax]
hive_server_host=192.168.37.242
hive_server_port=10009
server_conn_timeout=120
download_row_limit=10000
auth_username=hive
auth_password=ZT0kMfPMbzRaHBx
use_sasl=true
thrift_version=7
hive_metastore_host=192.168.37.162
hive_metastore_port=9083
[[ssl]]
[metastore]
[impala]
server_host=192.168.37.242
server_port=21052
impersonation_enabled=True
server_conn_timeout=120
auth_username=hive
auth_password=ZT0kMfPMbzRaHBx
[[ssl]]
[spark]
livy_server_url=http://192.168.37.160:8998
[oozie]
[filebrowser]
[pig]
[sqoop]
[proxy]
[hbase]
[search]
[libsolr]
[indexer]
[jobsub]
[jobbrowser]
[[query_store]]
[security]
[zookeeper]
[[clusters]]
[[[default]]]
[useradmin]
[[password_policy]]
[liboozie]
[aws]
[[aws_accounts]]
[azure]
[[azure_accounts]]
[[[default]]]
[[adls_clusters]]
[[[default]]]
[[abfs_clusters]]
[[[default]]]
[libsentry]
hostname=192.168.37.1
port=8038
[libzookeeper]
[librdbms]
[[databases]]
[libsaml]
[liboauth]
[kafka]
[[kafka]]
[metadata]
[[manager]]
[[optimizer]]
[[catalog]]
[[navigator]]
[[prometheus]]
四、初始化Hue
sudo -u hue /data/hue-4.10/hue/build/env/bin/hue syncdbsudo -u hue /data/hue-4.10/hue/build/env/bin/hue migrate
四、启动Hue
sudo -u hue nohup /data/hue-4.10/hue/build/env/bin/hue runserver 0.0.0.0:8888 &
1、登录Hue
首次登陆会将输入的用户名和密码作为超级管理员,如果忘记密码,可以重新使用上面命令初始化。

2、Hue测试Spark
a、Spark-Sql
- Spark SQL是Apache Spark的一个模块,提供了一个用于结构化数据处理的高级API和查询语言。它使得在Spark中可以轻松地执行SQL查询。

b、Pyspark
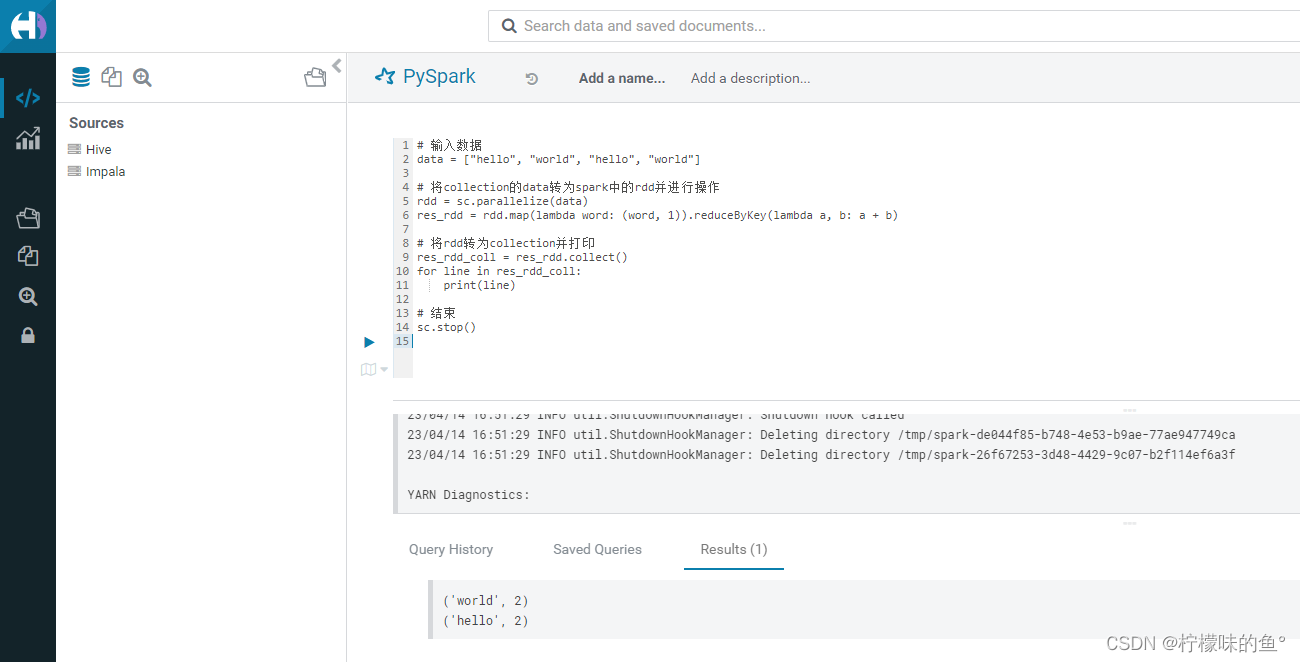
- PySpark是一种高效、易用的处理大数据集的Python API。它可以让Python开发人员在分布式计算环境下快速处理大规模数据集,并且可以通过各种数据处理方式进行数据分析和挖掘。下面是一个统计列表中每个单词出现次数pyspark的例子
# 输入数据
data = ["hello", "world", "hello", "world"]# 将collection的data转为spark中的rdd并进行操作
rdd = sc.parallelize(data)
res_rdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)# 将rdd转为collection并打印
res_rdd_coll = res_rdd.collect()
for line in res_rdd_coll:print(line)# 结束
sc.stop()
五、编写Hue system启动脚本
1、Hue shell脚本
- shell脚本如下,别忘记了用户需要执行权限
chmod +x /data/hue-4.10/hue/hue_service.sh
#!/bin/bashif [ $# -ne 2 ]; thenecho "please input two params,first is (hue),second is (start|stop)"exit 0
fiif [ "$1" == "hue" ]; thenif [ "$2" == "start" ]; thencd /data/hue-4.10/hue/logsecho "now is start hue"nohup /data/hue-4.10/hue/build/env/bin/hue runserver 0.0.0.0:8887 > /data/hue-4.10/hue/logs/info.log 2>&1 &exit 0elif [ "$2" == "stop" ]; thenhue_pid=$(netstat -nltp|grep 8887|awk '{print $NF}'|awk -F"/" '{print $1}')kill ${hue_pid}echo "hue has stop"exit 0elseecho "second param please input 'start' or 'stop'"exit 0fi
elseecho "first param please input 'hue'"
fi
2、Hue system脚本
- /usr/lib/systemd/system创建对应的hue.service文件
# /usr/lib/systemd/system/hue.service
[Unit]
Description=hue
Wants=network-online.target
After=network-online.target[Service]
Type=forking
User=hue
Group=hue
ExecStart=/data/hue-4.10/hue/hue_service.sh hue start
ExecStop=/data/hue-4.10/hue/hue_service.sh hue stop
Restart=no[Install]
WantedBy=multi-user.target
3、reload systemctl
systemctl daemon-reload
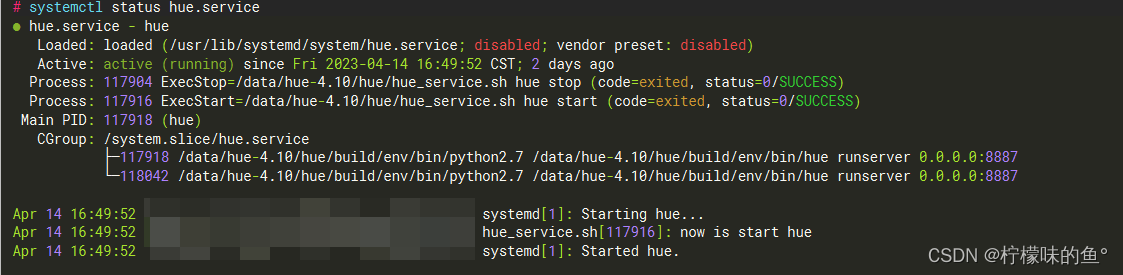
4、启动测试
systemctl start hue.service
5、验证
systemctl status hue.service
六、使用问题
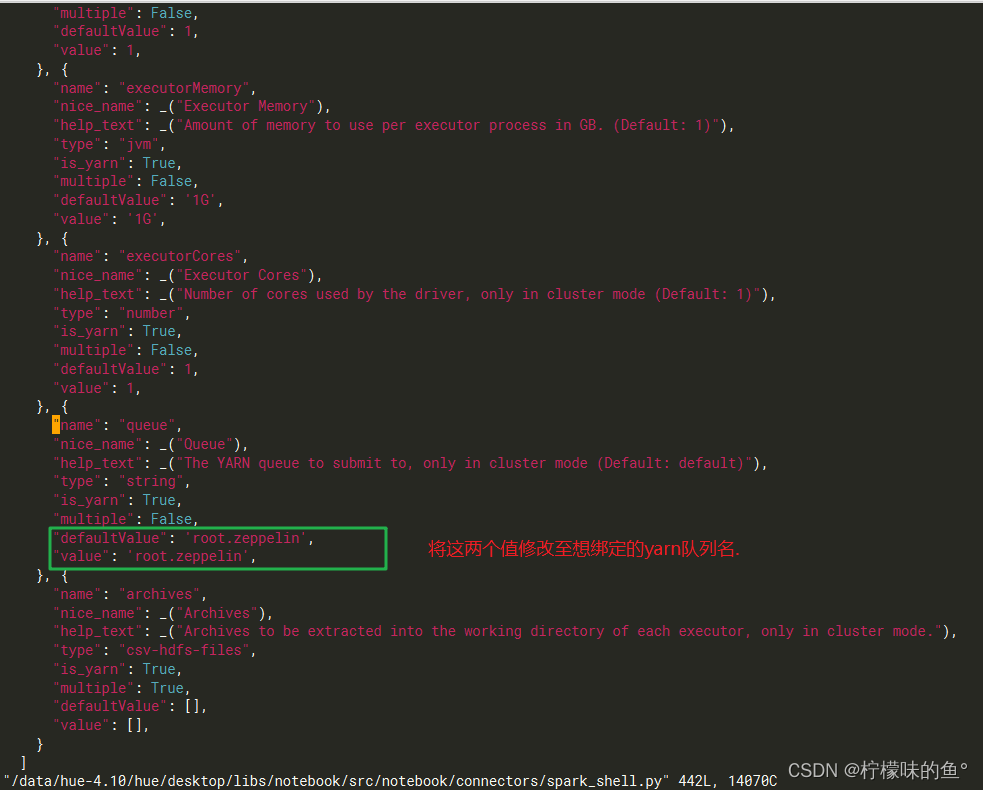
1、yarn 队列无法绑定
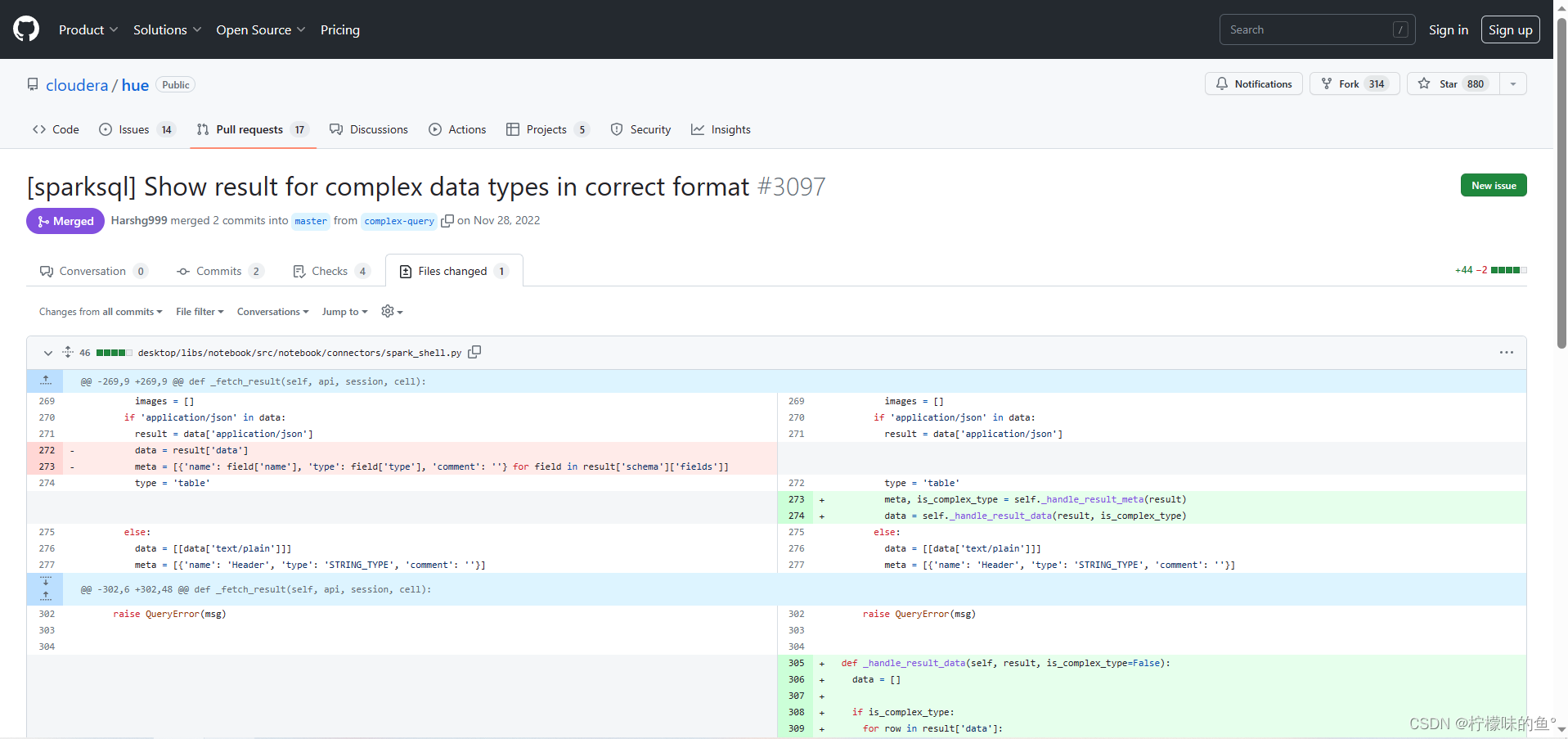
- 在hue中 livy 启动 Scala、Spark、PySpark都是使用的默认队列 root.default,这是因为默认在hue代码中绑定了YARN 队列名,我们可以通过修改hue源码进行修改队列。GitHub相关issues
vim /data/hue-4.10/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py
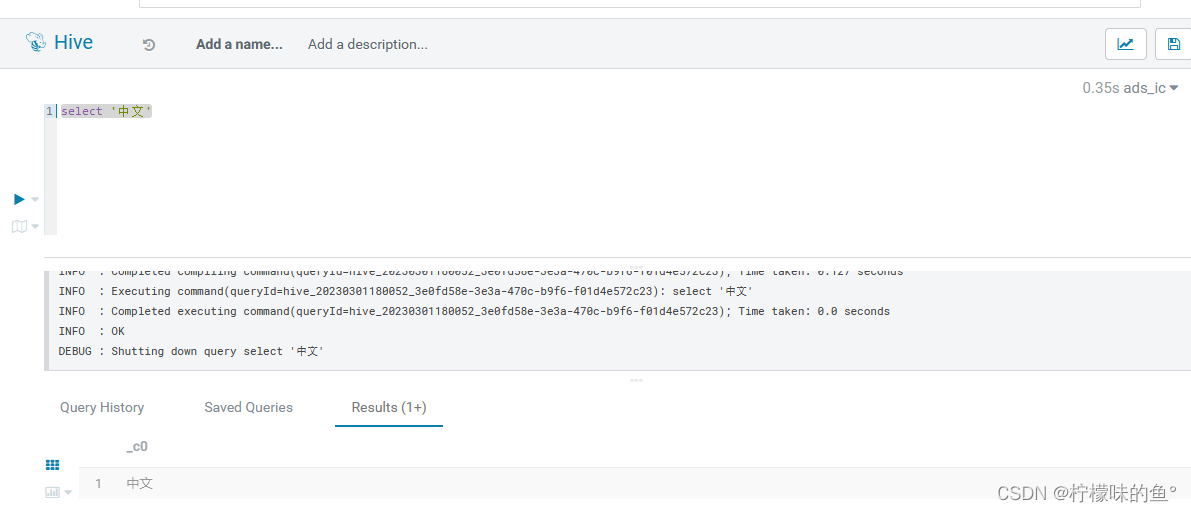
2、中文报错
- 在使用新版本hue 中文直接报错,GitHub相关issues
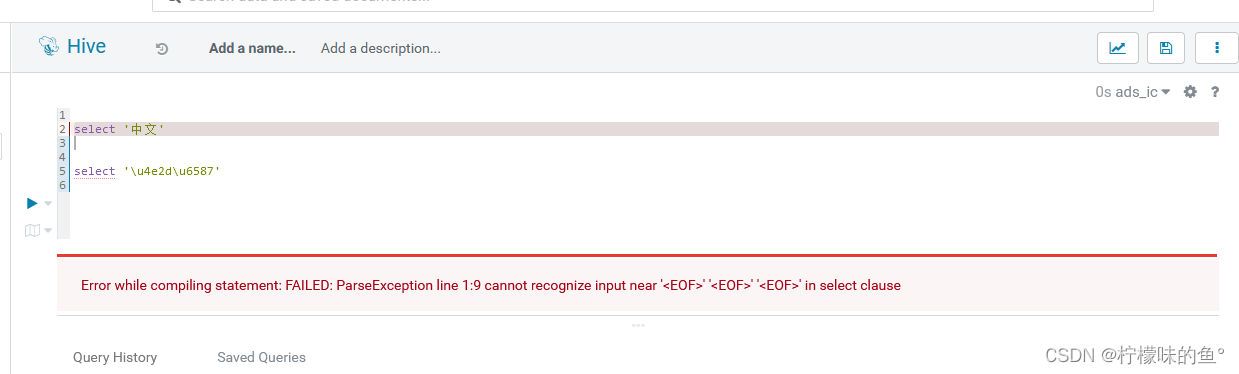
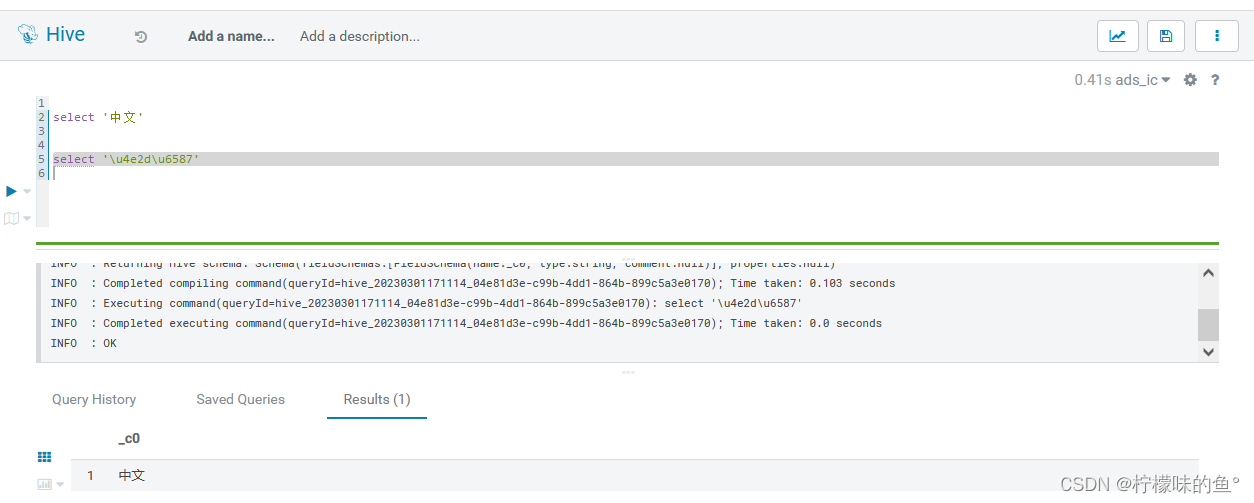
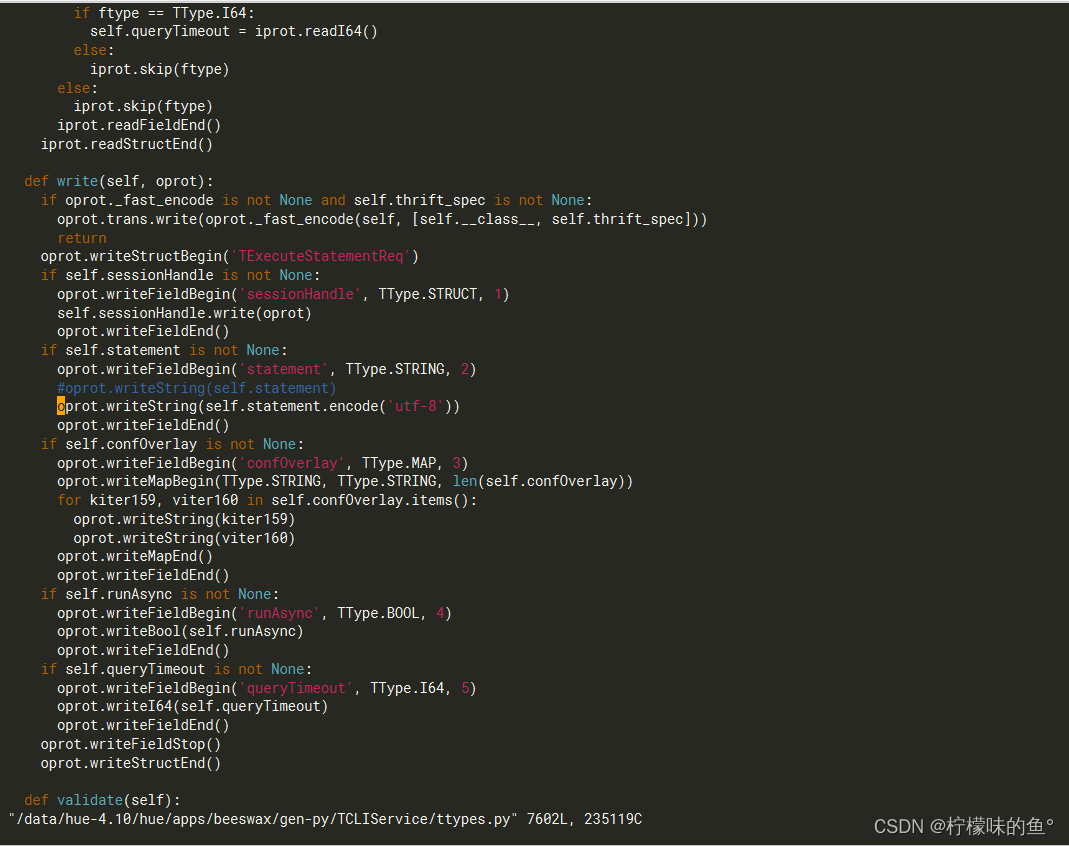
- 修改源码将其支持utf-8,oprot.writeString(self.statement) 编辑为 oprot.writeString(self.statement.encode(‘utf-8’))
vim /data/hue-4.10/hue/apps/beeswax/gen-py/TCLIService/ttypes.py
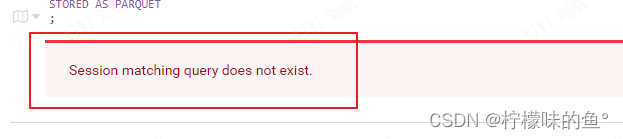
3、Session matching query does not exist.
- 会话匹配查询不存在,是hue的一个bug,很多人出现这种问题,现官方已修复GitHub相关issues,临时解决办法如下:
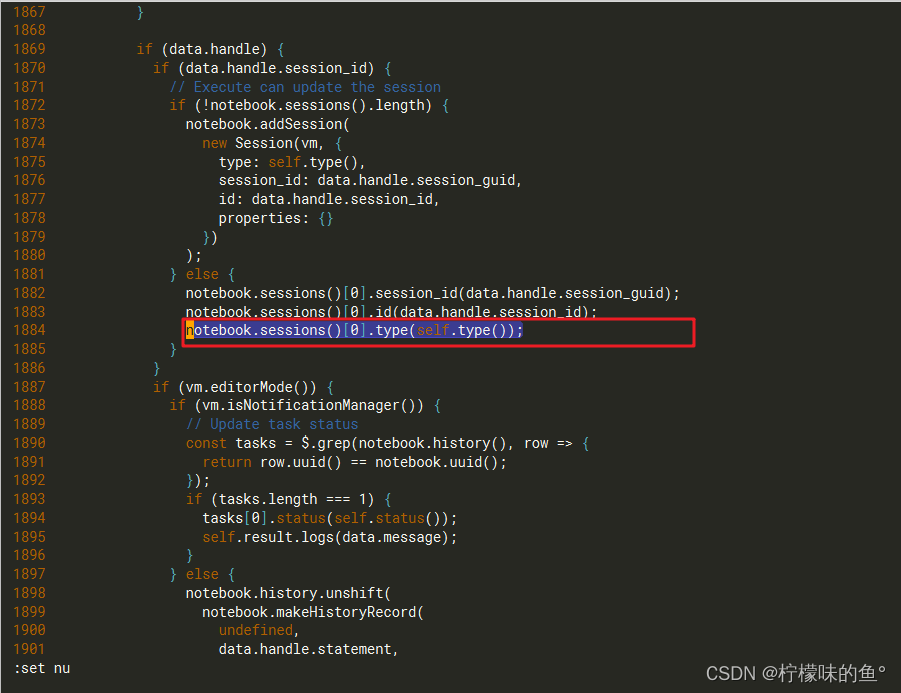
-- 在1884行增加一行代码,注意格式
vim /data/hue-4.10/hue/desktop/core/src/desktop/js/apps/notebook/snippet.jsnotebook.sessions()[0].type(self.type());
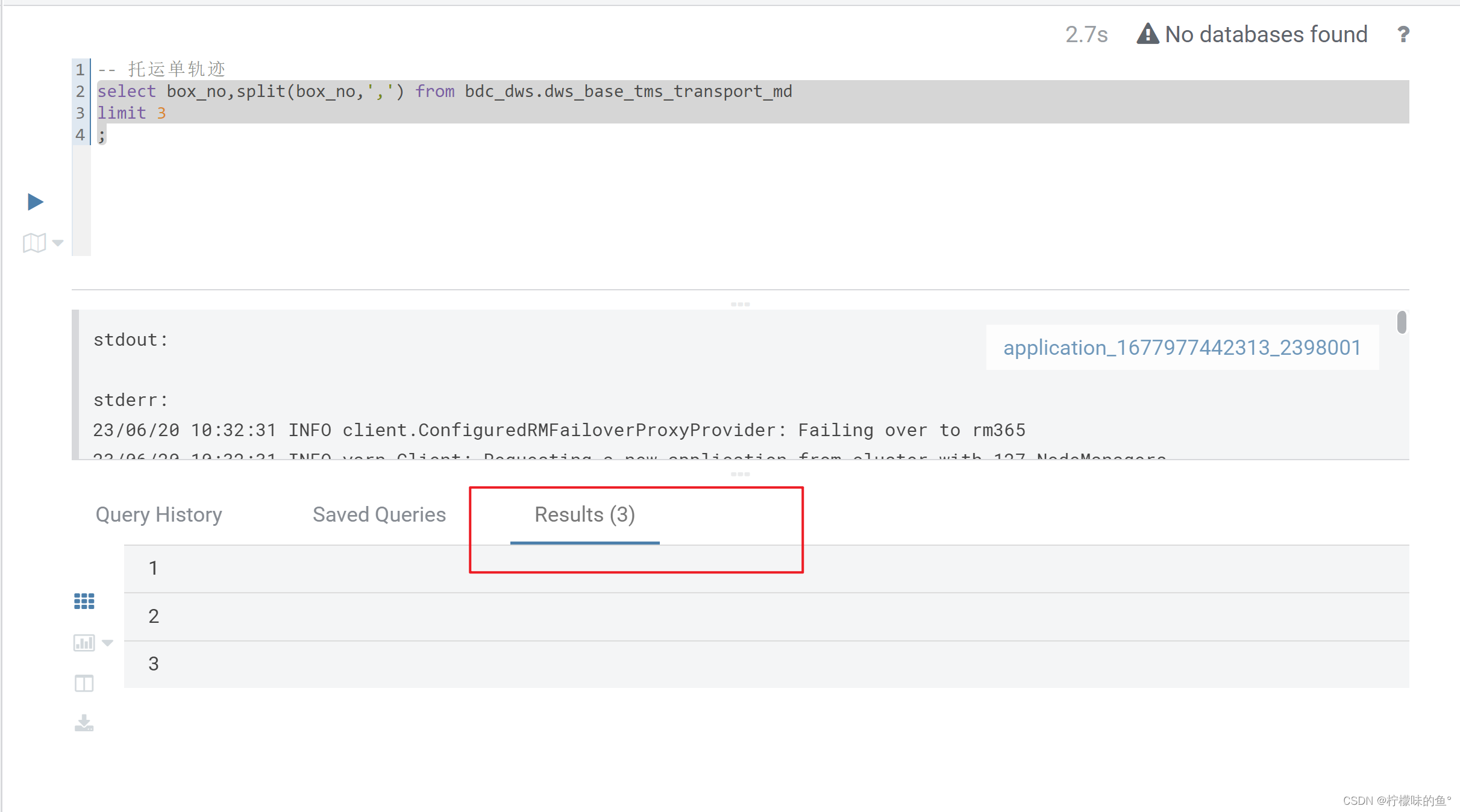
4、Spark-sql查询结果空白
- 这个也是hue的一个bug,GitHub相关issues,我们也是同样使用修改源码的方式修复。按照issues方法修改spark_shell.py文件即可,代码太多,这里就不贴出来了。
vim /data/hue-4.10/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py
七、总结
- Hue是一个开源的SQL助手,用于数据仓库。它可以与Livy集成,以便更轻松地开发SQL片段。Apache Livy提供了一个桥梁,可以与运行中的Spark解释器进行交互,以便可以交互地执行SQL、pyspark和scala片段。
- Hue 结合livy不仅可以添加sparksql+pyspark还可以添加Scala+R
相关参考借鉴:
hue 编译安装
HUE4.10编译打包
HUE编译