livy分析应用实战
Github地址:最全livy代码实战
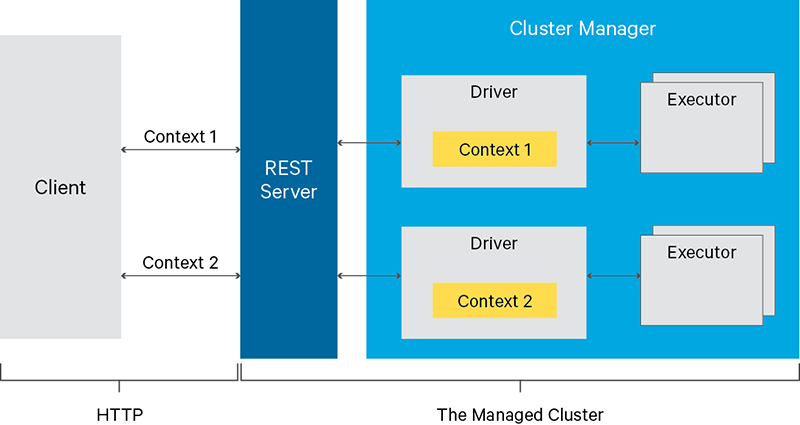
Apache Livy提供Rest service来与Apache Spark进行交互,通过Rest interface或RPC client来简化spark job和spark code snippet的提交,同步或异步获取结果,并提供对spark context的管理。
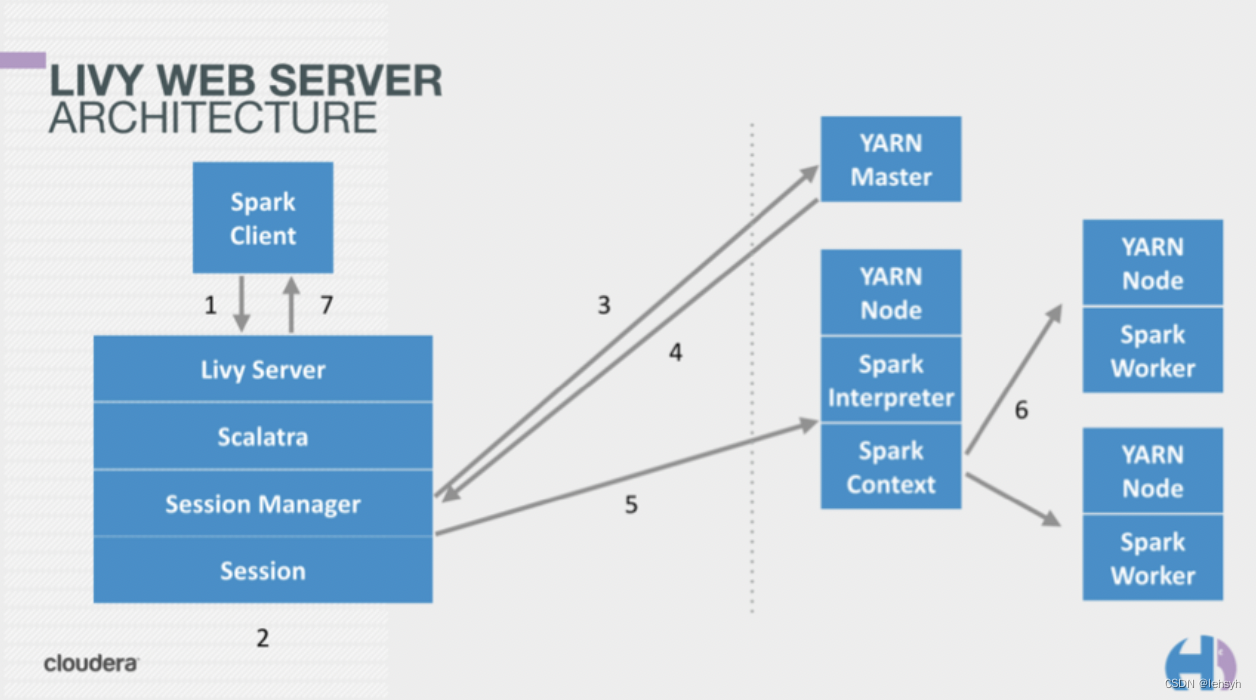
看下llivy官网的图,我们可以大概了解到livy的工作过程,其实就是充当了当我们提交作业到spark上的这个角色。以前我们直接要到有spark client的机器上进行submit的操作,现在我们只要使用restful就能完成所有的操作。
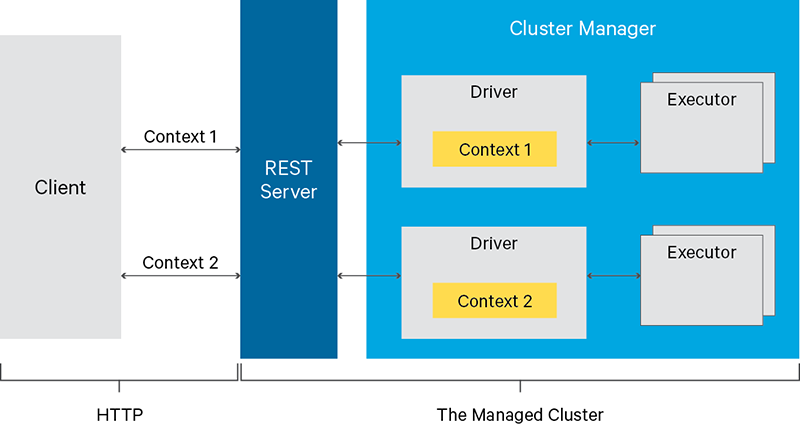
本文重点是我们从0到1分析运用最最实际的用法,其他的用法可以在此基础上探索。
1、livy安装
1、下载
下载最新版代码
https://github.com/apache/incubator-livy2、源码`编译
由于我要对接的是spark3.1.1版本,没有现成的livy版本,需要修改后再编辑
修改pom
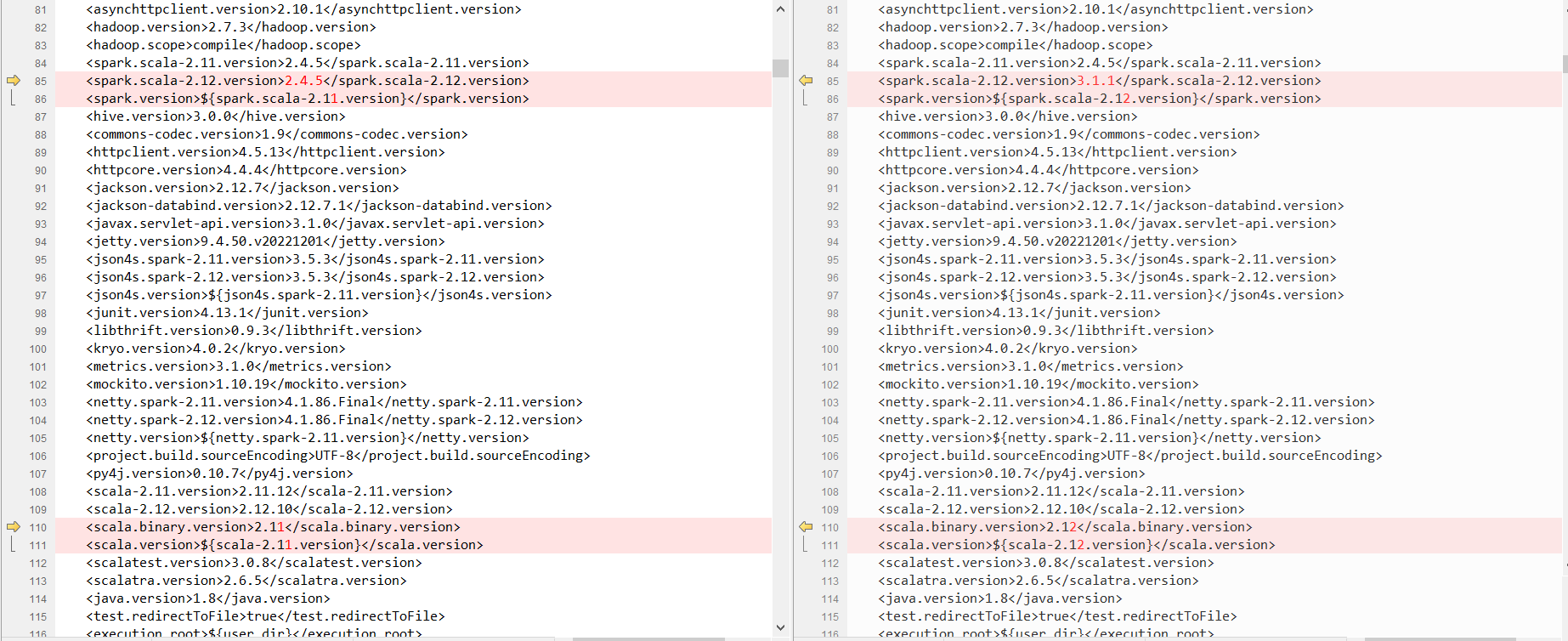

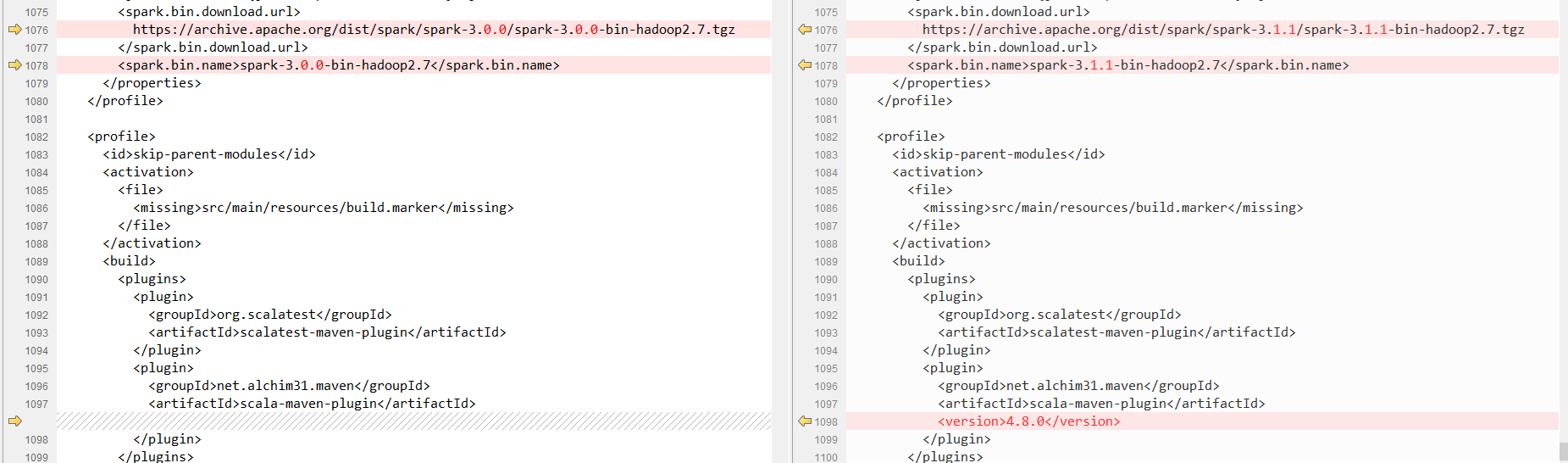
我用git bash进行编译的,因为里面有bash命令
mvn -DskipTests clean package
2、安装
unzip apache-livy-0.7.1-incubating-bin.zip
cd /opt
mv apache-livy-0.7.1-incubating-bin livy3、配置
cd /opt/livy
mkdir logs
mkdir tmfile
cd /opt/livy/conf
cp livy.conf.template livy.conf
cp livy-client.conf.template livy-client.conf
cp livy-env.sh.template livy-env.sh
cp log4j.properties.template log4j.propertiesvi livy.conf
livy.server.port = 18998
livy.server.host = 192.168.52.101
livy.spark.master = spark://192.168.52.101:7077
livy.server.session.timeout = 1h
livy.file.local-dir-whitelist = /opt/livy/tmpfile
livy.session.staging-dir=/opt/livy/tmpfile/tmp
livy.spark.deploy-mode = client
livy.repl.enable-hive-context = truevi livy-env.sh
#java路径
export JAVA_HOME=/usr/local/jdk
#spark路径
export SPARK_HOME=/opt/spark
#livyserver内存
export LIVY SERVER JAVA OPTS="-XmX1G"
#livy log存放位置
export LIVY_LOG_DIR=/opt/livy/logs
#livy PID文件存放位置
export LIVY_PID_DIR=/opt/livy/tmpfile/tmp
export LIVY_TEST=truevi livy-client.conf
livy.rsc.rpc.server.address = 192.168.52.1014、启动
启动之前把spark先启动了,这边spark的启动不展开了。
cd /opt/livy/bin
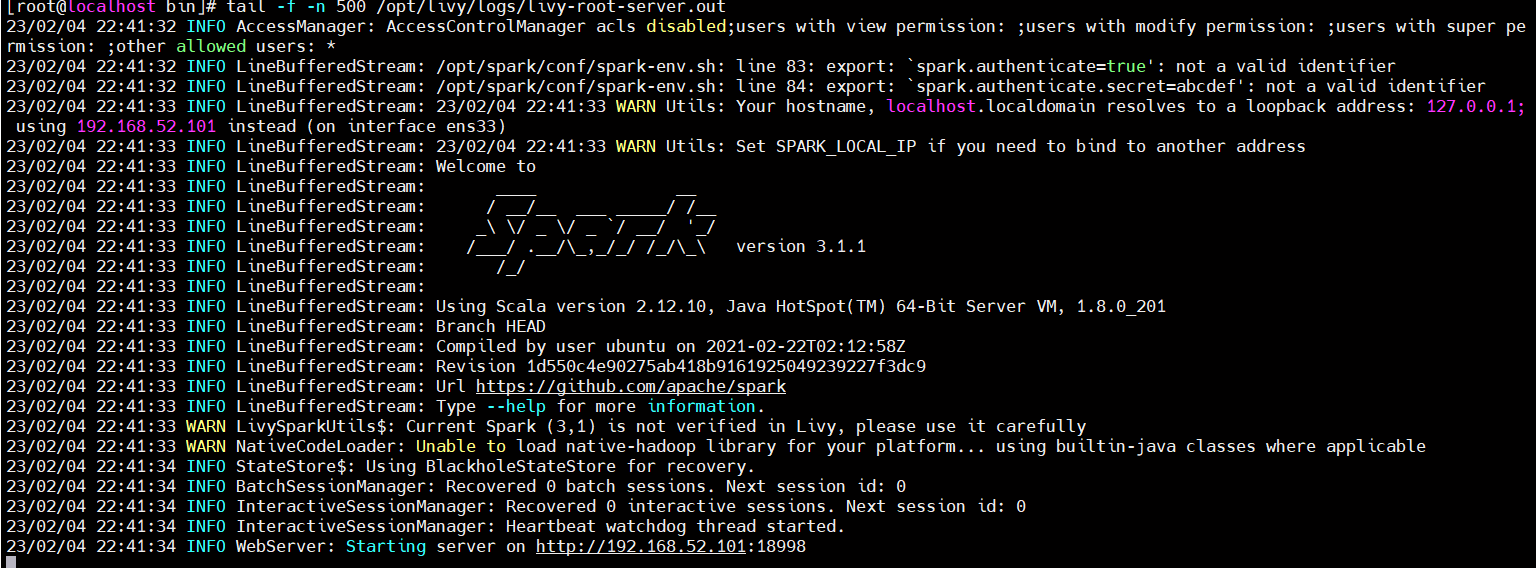
./livy-server start
2、livy使用
livy包括两种会话模型,我们一一通过代码去分析。
Github地址:最全livy代码实战
1、Batch Session方式
用户可以通过Livy以批处理的方式启动Spark应用,与spark中的sumbit是一样的,livy中就叫Batch Session,批量的,执行成功后,会关闭当前会话。
1、首先我们写一个spark算子
package com.mn.demoimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}/*** @program:hadoop* @description* @author:miaoneng* @create:2023-02-05 17:28**/
object WordCount {def main(args: Array[String]): Unit = {if(args.length < 2){println("要输入input和output")System.exit(1);}//spark上下文执行环境val conf:SparkConf = new SparkConf().setAppName("wordcount");val sc:SparkContext = new SparkContext(conf);val lines:RDD[String]= sc.textFile(args(0))val words:RDD[String] = lines.flatMap(_.split(" "))val wordAndOnes:RDD[(String,Int)] = words.map((_,1))val result:RDD[(String,Int)] = wordAndOnes.reduceByKey(_+_)result.repartition(1).saveAsTextFile(args(1))sc.stop()}
}2、打包
我们把spark程序打包,然后上传到livy的机器上【这边livy上可以加个函数,接收jar,放置在指定的地方】
我们的路径是 /opt/livy/tmpfile/jars/spark-1.0-SNAPSHOT.jar,同时这个路径也是在上面livy中配置了白名单的livy.file.local-dir-whitelist。否则你的jar将会提交不上去。
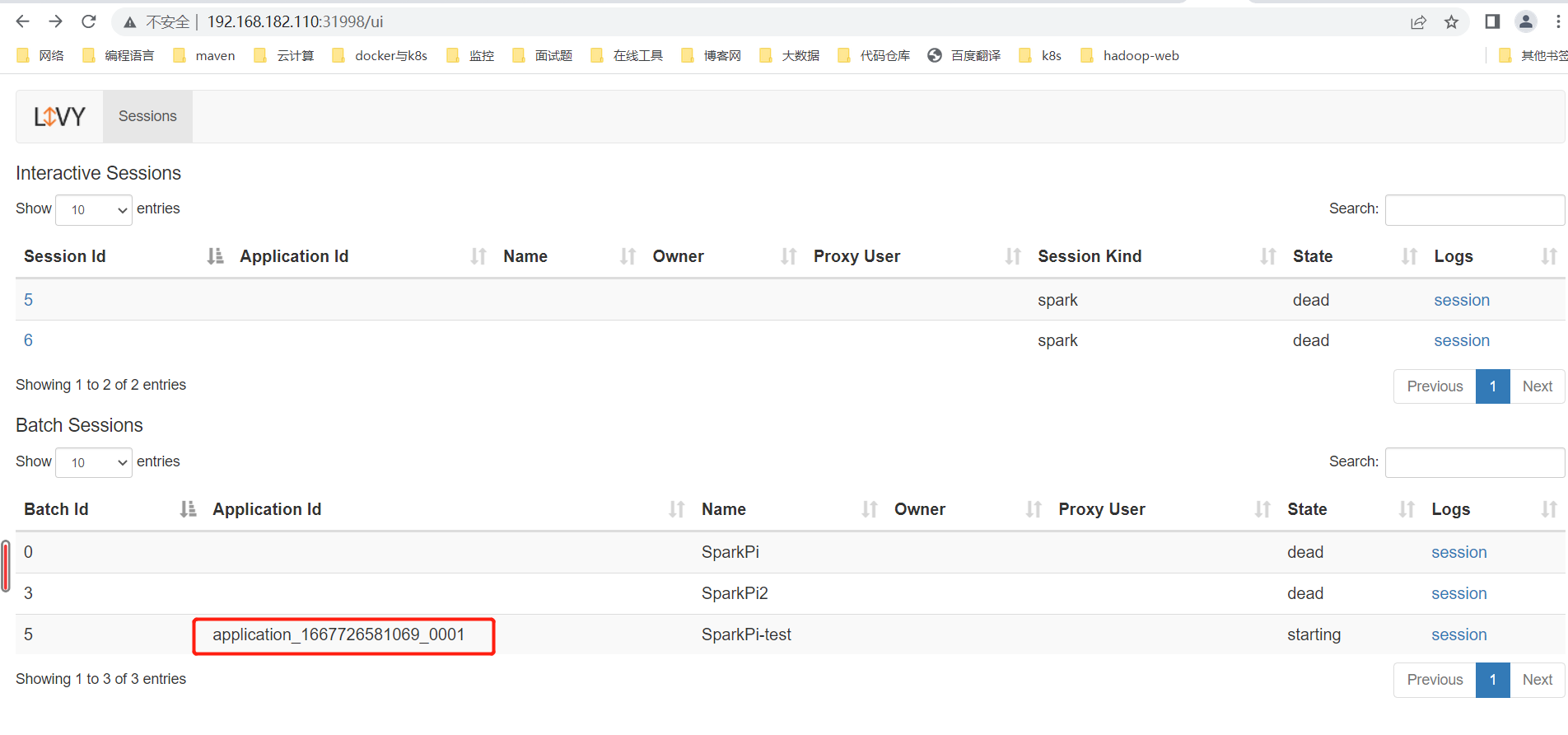
3、利用livy进行提交
package com.mn.livy;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.HttpEntity;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.livy.LivyClient;
import org.apache.livy.LivyClientBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** @program:hadoop* @description* @author:miaoneng* @create:2023-02-05 20:18**/
public class BatchDemo {private final static Logger logger = LoggerFactory.getLogger(BatchDemo.class);public static void main(String[] args) throws IOException, URISyntaxException {String livyUrl = "http://192.168.52.101:18998";Map<String ,Object> params = new HashMap<>();params.put("file","/opt/livy/tmpfile/jars/spark-1.0-SNAPSHOT.jar");params.put("className","com.mn.demo.WordCount");List<String > t = new ArrayList<>();t.add("/opt/test.txt");t.add("/opt/result");params.put("args",t);String ret = post(livyUrl + "/batches",new JSONObject(params).toString());Map<String, Object> v = (Map<String, Object>) JSON.parse(ret);String sessionId = v.get("id").toString();logger.info(sessionId);}public static String post(String url, String jsonStr) throws IOException {String mssg;CloseableHttpClient httpClient = HttpClients.createDefault();HttpPost httpPost = new HttpPost(url);RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(30000).setConnectionRequestTimeout(30000).setSocketTimeout(60000).build();httpPost.setConfig(requestConfig);httpPost.setHeader("Content-type", "application/json");CloseableHttpResponse httpResponse = null;try {httpPost.setEntity(new StringEntity(jsonStr, "utf-8"));httpResponse = httpClient.execute(httpPost);HttpEntity httpEntity = httpResponse.getEntity();return EntityUtils.toString(httpEntity);} catch (IOException e) {throw e;} finally {try {if (httpResponse != null) {httpResponse.close();}if (httpClient != null) {httpClient.close();}} catch (IOException e) {e.printStackTrace();}}}
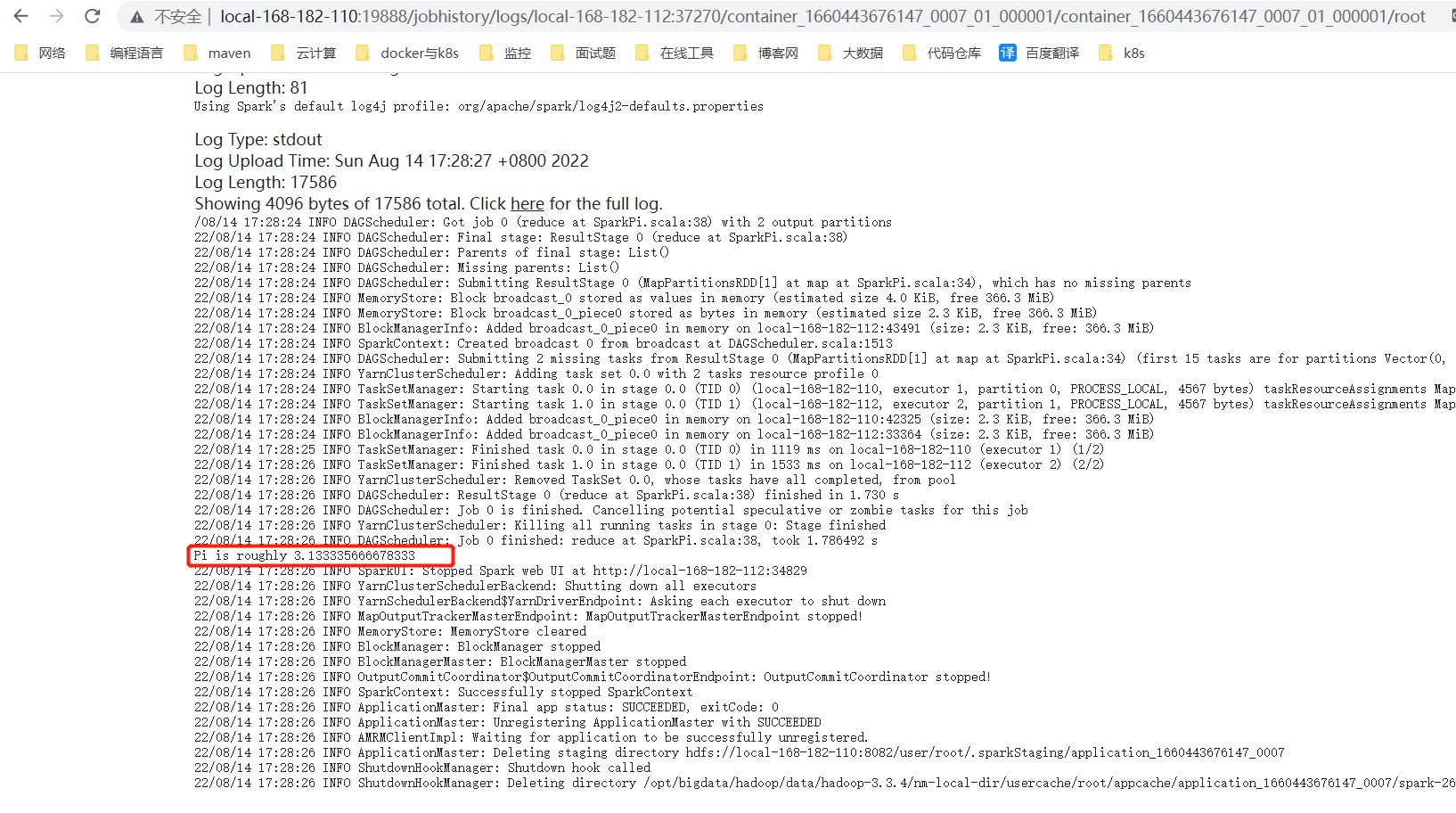
}4、结果
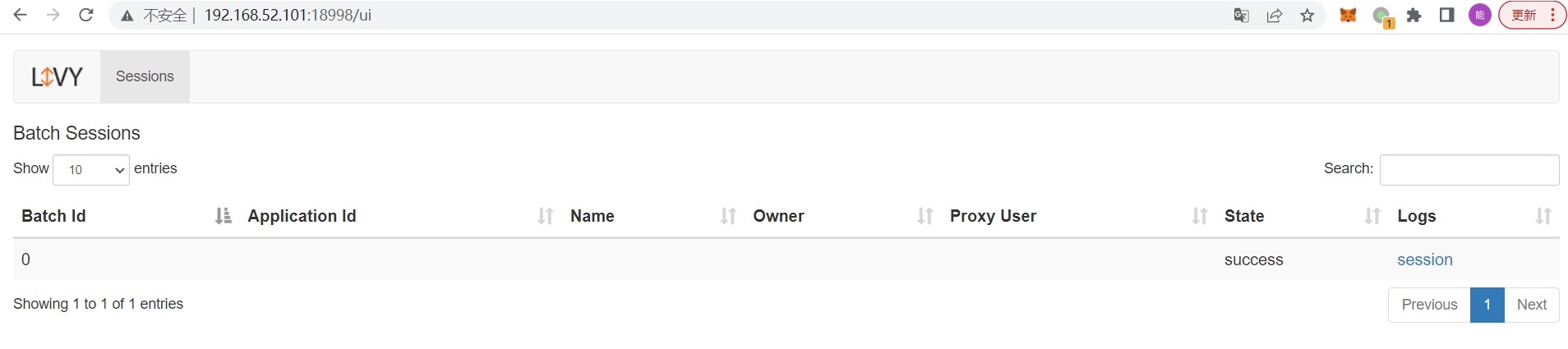
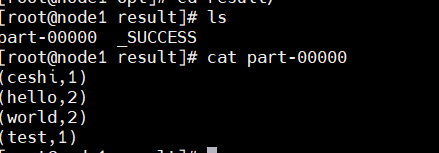
生成的结果也OK
2、Interactive session方式
第二种方式是交互式的,类似于spark-shell,交互式的。
我们第二个例子就不按照官网的demo来。
我们假设一个场景,我们用scala写好了一段代码,打个一个包,我让别人用java,根据类名,参数进行不断的提交。
例如:提交“add”,参数为10,10,那么spark帮我们计算出是20,提交“sub”,20和10,spark帮我们计算出为10。当然实际工作中会复杂很多。
通过连续性的工作就类似与spark-shell。下面我们来实现上面的场景。
分为核心算法jar:spark.jar
调用核心算法jar:livy.jar
未来还可以进一步封装成一个调用接口类:目前没有做。这样写业务的直接调用接口,完全感知不到livy的存在。
1、spark.jar
先进行写一个简单的scala程序。实现加,减操作。
此块代码就是spark处理的核心代码jar中。我们写在spark的jar中。
package com.mn.demoimport com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.spark.sql.SparkSession/*** @program:hadoop* @description* @author:miaoneng* @create:2023-02-11 12:29**/
object DataOperate {def operateData(spark:SparkSession,stepId:String,jsonDataStr:String):Int ={println(stepId)println(jsonDataStr)var obj:JSONObject = JSON.parse(jsonDataStr).asInstanceOf[JSONObject]val x = obj.get("x").asInstanceOf[Int]val y = obj.get("y").asInstanceOf[Int]if(stepId=="add"){add(x,y)}else if(stepId=="sub"){sub(x,y)}else{0}}def add(x:Int,y:Int): Int ={x+y}def sub(x:Int,y:Int):Int= {x-y}
}2、livy.jar
我们通过livy来写一个类调用spark代码的core类。
此代码放在我们自己写的livy的jar中。
package com.mn.core;import com.mn.demo.DataOperate;
import org.apache.livy.Job;
import org.apache.livy.JobContext;
import org.apache.spark.sql.SparkSession;/*** @program:hadoop* @description 作业* @author:miaoneng* @create:2023-02-11 13:19**/
public class MyJob implements Job<Integer> {// 方法名private String methodName = "";// 所存步骤参数private String params;public MyJob(String methodName, String params) {this.methodName = methodName;this.params = params;}@Overridepublic Integer call(JobContext jobContext) throws Exception {//让spark算子包进行计算return callSpark(jobContext.sparkSession(), methodName, params);}public Integer callSpark(SparkSession sparkSession, String methodName, String params) {return DataOperate.operateData(sparkSession, methodName, params);}
}3、业务调用
1、定义步骤:List stepList
2、拆解步骤。
3、通过livy调用spark。
目前我们演示,直接写在livy.jar中。
package com.mn.livy;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.mn.core.MyJob;
import org.apache.livy.LivyClient;
import org.apache.livy.LivyClientBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;/*** @program:hadoop* @description* @author:miaoneng* @create:2023-02-11 13:31**/
public class SeesionDemo {private final static Logger logger = LoggerFactory.getLogger(SeesionDemo.class);public static String url = "http://192.168.52.101:18998";public static void main(String[] args) {//定义步骤1,调用add方法,两个参数为x:10,y:10String jsonString1 = "{\"methodName\":\"add\",\"params\":{\"x\":10,\"y\":10}}";//定义步骤2,调用sub方法,两个参数为x:20,y:10String jsonString2 = "{\"methodName\":\"sub\",\"params\":{\"x\":20,\"y\":10}}";List<String> stepList = new ArrayList<>();stepList.add(jsonString1);stepList.add(jsonString2);try {callSpark(stepList);} catch (IOException e) {e.printStackTrace();} catch (URISyntaxException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}public static void callSpark(List<String> stepList) throws IOException, URISyntaxException, ExecutionException, InterruptedException {LivyClient livyClient = new LivyClientBuilder().setURI(new URI(url)).build();//换成你自己的路径//用livy客户端将我们写的Spark的算子包提交到spark环境中livyClient.uploadJar(new File("E:\\github\\hadoop\\spark\\target\\spark-1.0-SNAPSHOT.jar")).get();//livy写的业务操作jarlivyClient.uploadJar(new File("E:\\github\\hadoop\\livy\\target\\livy-1.0-SNAPSHOT.jar")).get();//spark.jar中用到的fastjson包//1、可以在打spark.jar的时候可以打成一个胖jar包//2、可以写个代码把要上传的jar规范好,让大家按照这个格式列好spark.jar用到的额外jar,然后一个个upload上去livyClient.uploadJar(new File("E:\\github\\jars\\fastjson-1.2.83.jar")).get();//拆解需要执行的步骤Integer ret = 0;for(int i =0 ;i < stepList.size();i++){JSONObject jsonObject = JSON.parseObject(stepList.get(i));String methodName = jsonObject.get("methodName").toString();String params = jsonObject.get("params").toString();ret = livyClient.submit(new MyJob(methodName,params)).get();logger.info("步骤"+i+":所做的操作是"+methodName+",结果为:"+ret);}livyClient.stop(true);}
}
4、参数
一些参数就在后期的使用中慢慢来加入。