Livy 安装部署使用示例
- 1. Apache Livy 简介
- 2. 安装前置要求
- 3.下载安装包配置相关配置文件
- 4. 启动服务配置使用
- 5.提交任务获取运行结果
- 6.拓展参考
1. Apache Livy 简介
官网:https://livy.apache.org/
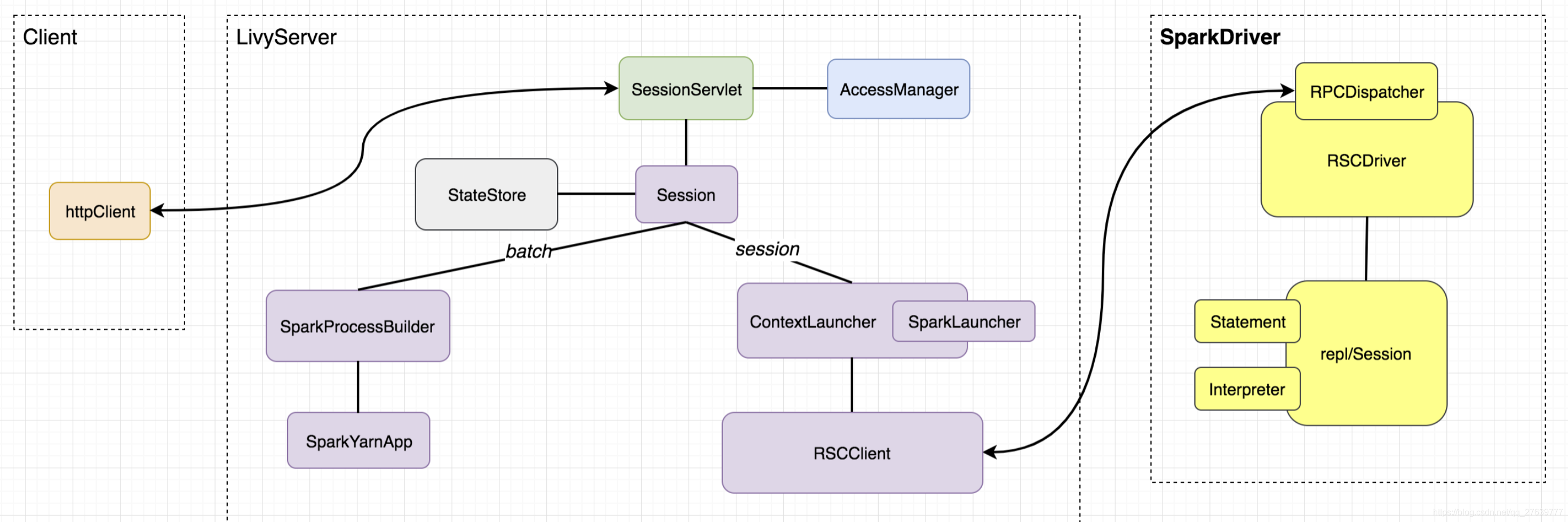
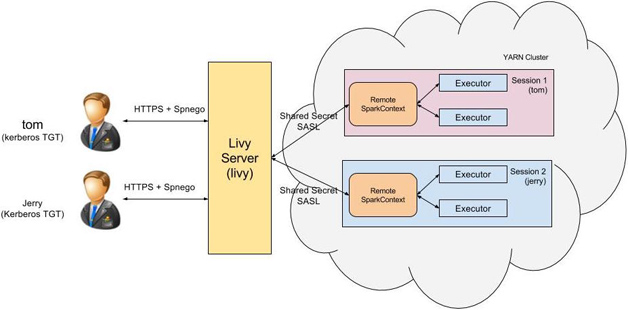
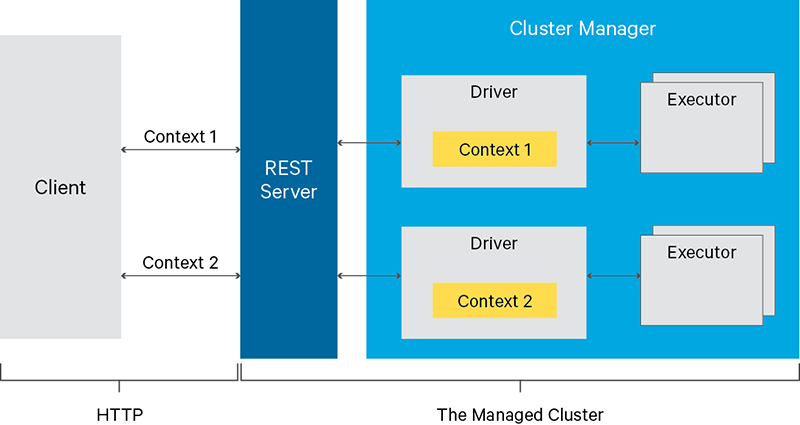
Livy是一个提供rest接口和spark集群交互的服务。它可以提交spark job或者spark一段代码,同步或者异步的返回结果;也提供sparkcontext的管理,通过restfull接口或RPC客户端库。Livy也简化了与spark与应用服务的交互,这允许通过web/mobile与spark的使用交互。其他特点还包含:
- 长时间运行的SparkContext,允许多个spark job和多个client使用。
- 在多个spark job和客户端之间共享RDD和Dataframe
- 多个sparkcontext可以简单的管理,并运行在集群中而不是Livy Server,以此获取更好的容错性和并行度。
- 作业可以通过重新编译的jar、片段代码、或Java/Scala的客户端API提交。
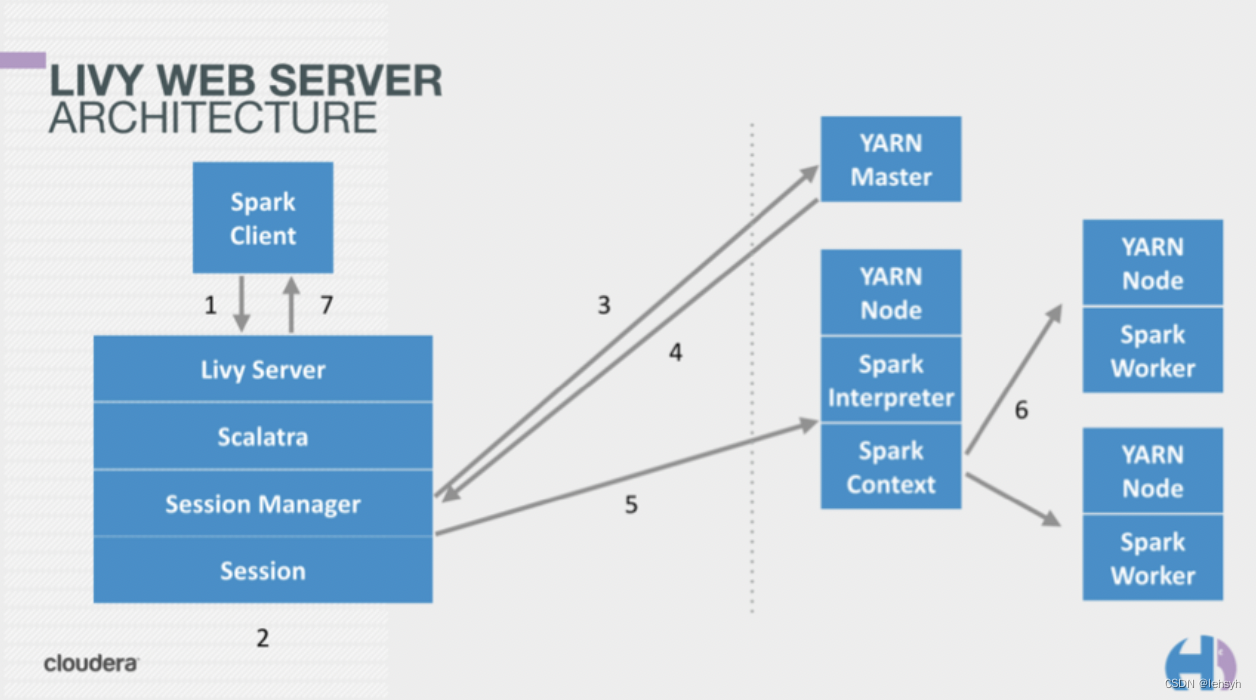
Livy结合了spark job server和Zeppelin的优点,并解决了spark job server和Zeppelin的缺点。
- 支持jar和snippet code
- 支持SparkContext和Job的管理
- 支持不同SparkContext运行在不同进程,同一个进程只能运行一个SparkContext
- 支持Yarn cluster模式
- 提供restful接口,暴露SparkContext
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WHen0wyM-1648538166777)(/Users/yangkezhen/Library/Application Support/typora-user-images/image-20220329114534773.png)]](https://img-blog.csdnimg.cn/07a0f2ac4f814e61b393b8bd176302cb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATWljaGVhbGt6,size_20,color_FFFFFF,t_70,g_se,x_16)
2. 安装前置要求
-
Spark 版本要求 1.6版本以上,支持的scala 版本为2.10 或者scala 2.11
-
设置环境变量
# 选择自己版本的Spark 和Hadoop 的目录 export SPARK_HOME=/usr/lib/spark export HADOOP_CONF_DIR=/etc/hadoop/conf -
注意:Spark3.0 版本及3.1 3.2 版本采用的是scala 2.12 与Livy 要求的不一致会导致报错,Livy 暂时不支持Scala 的2.12 版本
3.下载安装包配置相关配置文件
下载地址:https://livy.apache.org/download
Livy官网:https://livy.apache.org/get-started/
1.下载相关压缩包
livy-0.5.0-incubating-bin.zip
2.解压到指定目录
tar -zxvf livy-0.5.0-incubating-bin.zip -C ../app/
3.软连接
ln -s livy-0.5.0-incubating-bin livy
修改相关配置文件
livy.conf
livy.spark.master = yarn
livy.spark.deployMode = cluster
livy.environment = production
livy.impersonation.enabled = true
livy.server.csrf_protection.enabled false
livy.server.port = 8998
livy.server.session.timeout = 3600000
livy.server.recovery.mode = recovery
livy.server.recovery.state-store=filesystem
livy.server.recovery.state-store.url=/tmp/livy
livy-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_231
export HADOOP_HOME=/home/hadoop/app/hadoop
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop/bin/hadoop/etc/hadoop
export SPARK_CONF_DIR=/home/hadoop/app/spark/conf
export SPARK_HOME=/home/hadoop/app/spark/
export LIVY_LOG_DIR=/home/hadoop/app/livy/log
export LIVY_PID_DIR=/home/hadoop/app/livy/pid-dir
export LIVY_SERVER_JAVA_OPTS="-Xmx2g"
Spark-blacklist.sh
spark.master
spark.submit.deployMode# Disallow overriding the location of Spark cached jars.
spark.yarn.jar
spark.yarn.jars
spark.yarn.archive# Don't allow users to override the RSC timeout.
livy.rsc.server.idle-timeout
修改Hadoop 配置文件 core-site.xml
<property><name>hadoop.proxyuser.livy.groups</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.livy.hosts</name><value>*</value>
</property>
HDFS 上面创建livy 的用户目录
hdfs dfs -mkdir -p /user/livy
hdfs dfs -chown livy:supergroup /user/livy
4. 启动服务配置使用
启动Hadoop 和Livy
sh /home/hadoop/app/livy/bin/livy-server start
进入log 目录查看启动日志
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Welcome to
22/03/28 19:56:29 INFO LineBufferedStream: stdout: ____ __
22/03/28 19:56:29 INFO LineBufferedStream: stdout: / __/__ ___ _____/ /__
22/03/28 19:56:29 INFO LineBufferedStream: stdout: _\ \/ _ \/ _ `/ __/ '_/
22/03/28 19:56:29 INFO LineBufferedStream: stdout: /___/ .__/\_,_/_/ /_/\_\ version 2.4.5
22/03/28 19:56:29 INFO LineBufferedStream: stdout: /_/
22/03/28 19:56:29 INFO LineBufferedStream: stdout:
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Using Scala version 2.11.12, Java HotSpot(TM) 64-Bit Server VM, 1.8.0_231
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Branch HEAD
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Compiled by user centos on 2020-02-02T19:38:06Z
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Revision cee4ecbb16917fa85f02c635925e2687400aa56b
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Url https://gitbox.apache.org/repos/asf/spark.git
22/03/28 19:56:29 INFO LineBufferedStream: stdout: Type --help for more information.
22/03/28 19:56:29 WARN LivySparkUtils$: Current Spark (2,4) is not verified in Livy, please use it carefully
22/03/28 19:56:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/03/28 19:56:30 INFO RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
22/03/28 19:56:30 INFO StateStore$: Using FileSystemStateStore for recovery.
22/03/28 19:56:30 INFO BatchSessionManager: Recovered 0 batch sessions. Next session id: 0
22/03/28 19:56:30 INFO InteractiveSessionManager: Recovered 0 interactive sessions. Next session id: 0
22/03/28 19:56:30 INFO InteractiveSessionManager: Heartbeat watchdog thread started.
22/03/28 19:56:30 INFO WebServer: Starting server on http://hadoop01:12889
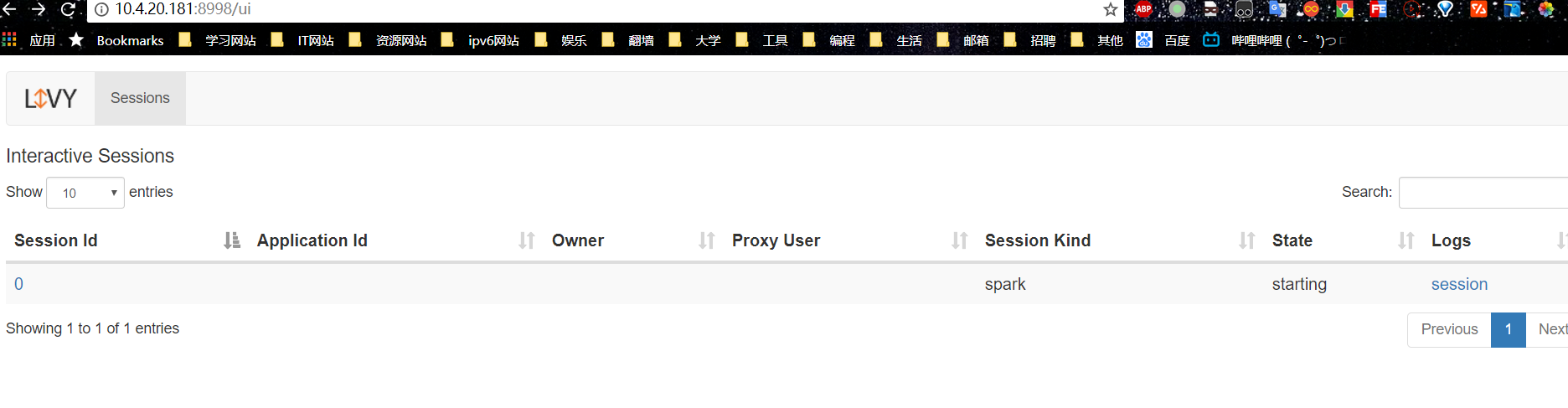
访问Livy 对应web 地址:http://localhost:8998
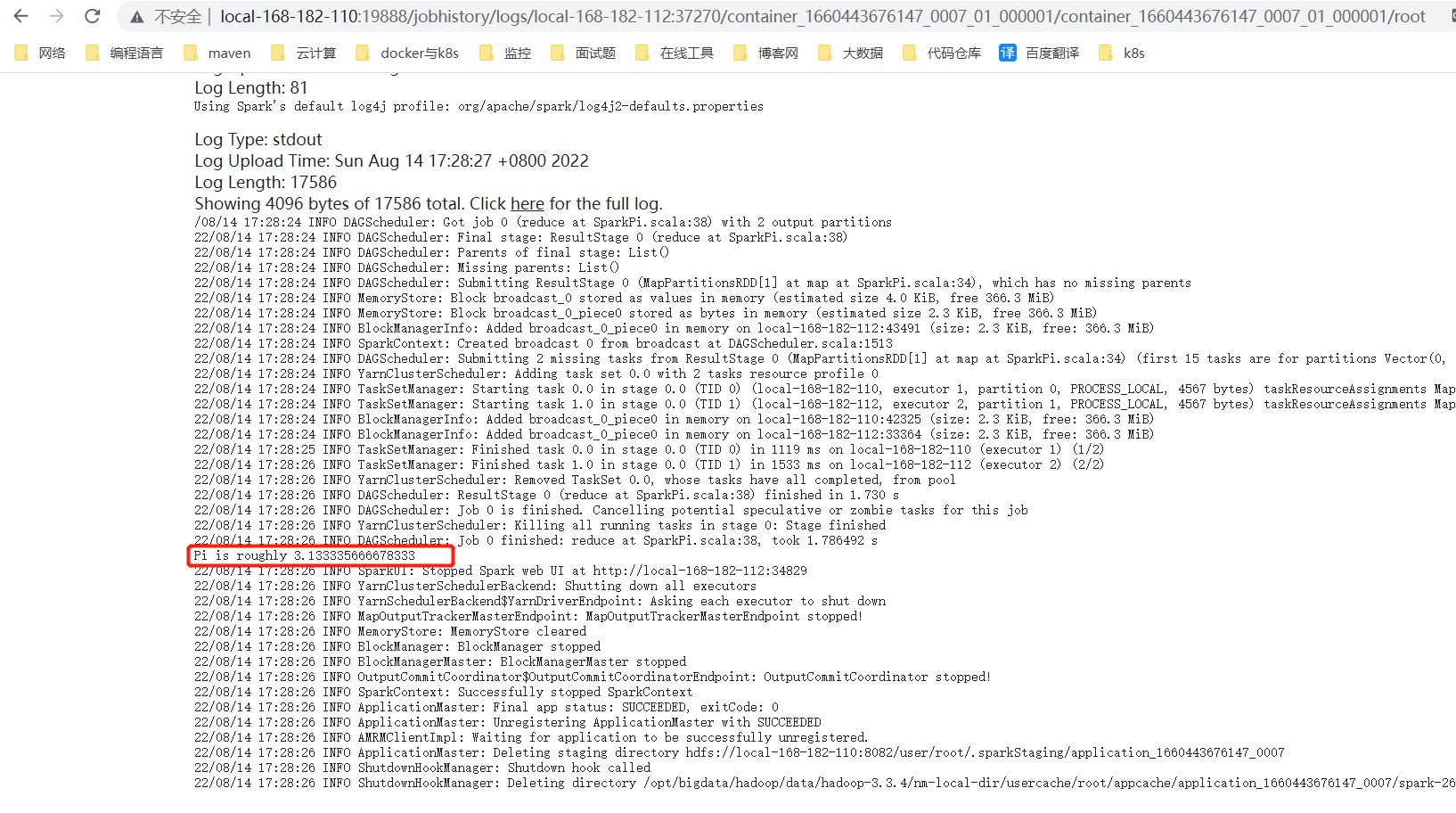
5.提交任务获取运行结果
新建Session
post http://localhost:8998/sessions
{ "kind":"spark"}执行结果为:
{"id": 0, -- session id "appId": null,"owner": null,"proxyUser": null,"state": "starting", -- session 状态"kind": "spark","appInfo": { -- app 信息"driverLogUrl": null,"sparkUiUrl": null},"log": ["stdout: ","\nstderr: ","\nYARN Diagnostics: "]
}
提交代码片段测试:
1.提交代码片段
POST http://localhost:8998/sessions/0/statements
参数:{ "code":"sc.makeRDD(List(1,2,3,4)).count"}2.查看执行结果:
GET http://localhost:8998/sessions/0/statements/0
结果为:
{"id": 0,"code": "sc.makeRDD(List(1,2,3,4)).count","state": "available","output": {"status": "ok","execution_count": 0,"data": {"text/plain": "res0: Long = 4\n"}},"progress": 1.0
}
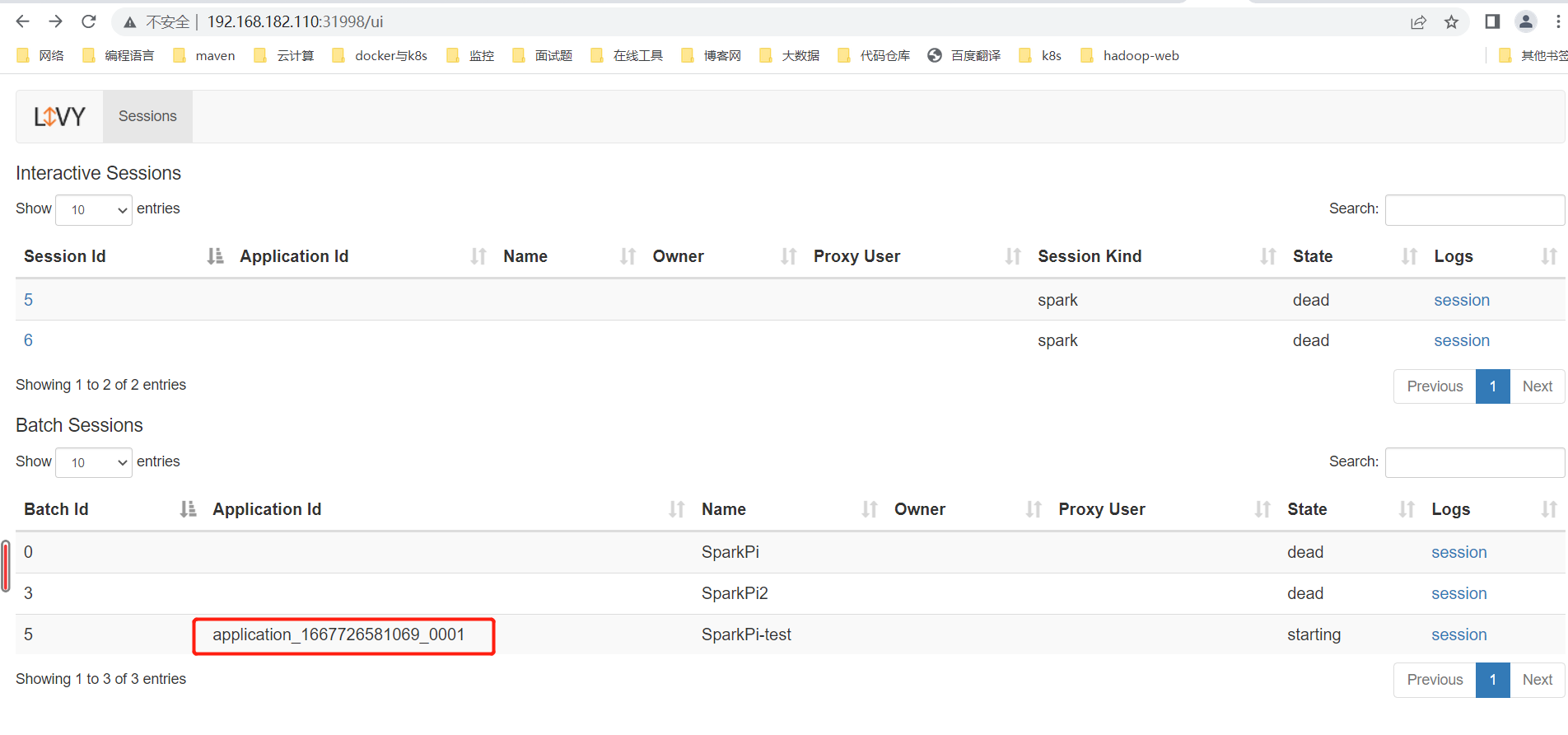
提交Jar 包测试:
POST http://localhost:8998/batches
参数:
{"file":"hdfs://hadoop01:9000/data/jars/spark-examples_2.11-2.4.5.jar","className":"org.apache.spark.examples.SparkPi","name":"SparkPi"
}获取执行结果:
GET http://localhost:8998/batches{"from": 0,"total": 1,"sessions": [{"id": 2,"state": "success","appId": "application_1648535069074_0001","appInfo": {"driverLogUrl": null,"sparkUiUrl": "http://hadoop01:8088/proxy/application_1648535069074_0001/"},"log": ["\t queue: root.hadoop","\t start time: 1648535413833","\t final status: UNDEFINED","\t tracking URL: http://hadoop01:8088/proxy/application_1648535069074_0001/","\t user: hadoop","22/03/29 14:30:14 INFO ShutdownHookManager: Shutdown hook called","22/03/29 14:30:14 INFO ShutdownHookManager: Deleting directory /tmp/spark-75f3b2db-7972-463c-894a-2f1190584242","22/03/29 14:30:14 INFO ShutdownHookManager: Deleting directory /tmp/spark-f9de9d4c-d5ef-4c39-875a-30228cd8164c","\nstderr: ","\nYARN Diagnostics: "]}]
}配置提交参数进行测试:需要注意参数的类型
POST http://localhost:8998/batches{"file":"hdfs://hadoop01:9000/data/jars/spark-examples_2.11-2.4.5.jar","className":"org.apache.spark.examples.SparkPi","name":"SparkPi","proxyUser":"hadoop","driverMemory":"1g","executorMemory":"2g","numExecutors":2,"queue":"root.default"}查询结果为:根据提交时返回的ID 匹配对应的结果
http://localhost:8998/batches
{"id": 6,"state": "starting","appId": "application_1648535069074_0003","appInfo": {"driverLogUrl": null,"sparkUiUrl": null},"log": ["\t queue: root.default","\t start time: 1648535958201","\t final status: UNDEFINED","\t tracking URL: http://hadoop01:8088/proxy/application_1648535069074_0003/","\t user: hadoop","22/03/29 14:39:18 INFO ShutdownHookManager: Shutdown hook called","22/03/29 14:39:18 INFO ShutdownHookManager: Deleting directory /tmp/spark-3167a453-a1d8-436a-b20c-412c9fb33ac9","22/03/29 14:39:18 INFO ShutdownHookManager: Deleting directory /tmp/spark-b048a123-8e7e-4d4a-8fde-9ff8c047f685","\nstderr: ","\nYARN Diagnostics: "]}
Yarn 上的信息为:

Starting with version 0.5.0-incubating, each session can support all four Scala, Python and R interpreters with newly added SQL interpreter. The kind field in session creation is no longer required, instead users should specify code kind (spark, pyspark, sparkr or sql) during statement submission.
创建SQL 方式的Session 初始化的是SparkSession 并不能直接查存在Hive 表里面的数据,这个部分还需进一步实现
6.拓展参考
有兴趣的可以参考如下文章对Livy 进行个性化定制
1.https://www.freesion.com/article/92911087759/
2.livy在交互式查询中的深度定制