背景:
Apache Spark 是一个比较流行的大数据框架、广泛运用于数据处理、数据分析、机器学习中,它提供了两种方式进行数据处理,一是交互式处理:比如用户使用spark-shell,编写交互式代码编译成spark作业提交到集群上去执行;二是批处理,通过spark-submit 提交打包好的spark 应用jar到集群中进行执行。
这两种运行方式都需要安装spark客户端配置好yarn集群信息,并打通集群网络访问权限,这种方式存在增加client所在节点资源使用负担和故障发生的可能性,同时client节点故障带来的单点问题。其次是这种方式难以管理、审计以及进行权限管理和控制。
社区有开发一个基于spark 的REST服务livy,apache livy提供通过restful接口或者编程接口提交spark任务,支持提交scala、pyspark、sparkr交互式代码执行spark任务,这样可以通过livy restapi服务作为中转用来解决k8s集群中提交spark任务跑在yarn集群的问题。
Livy基本架构
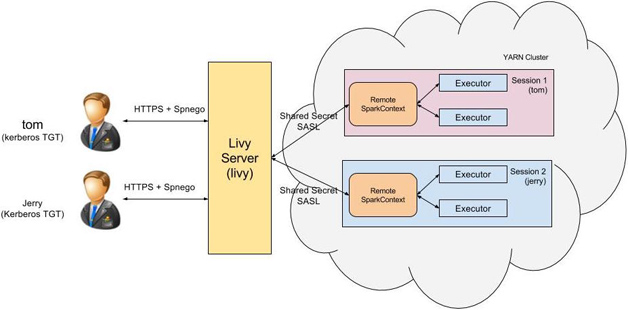
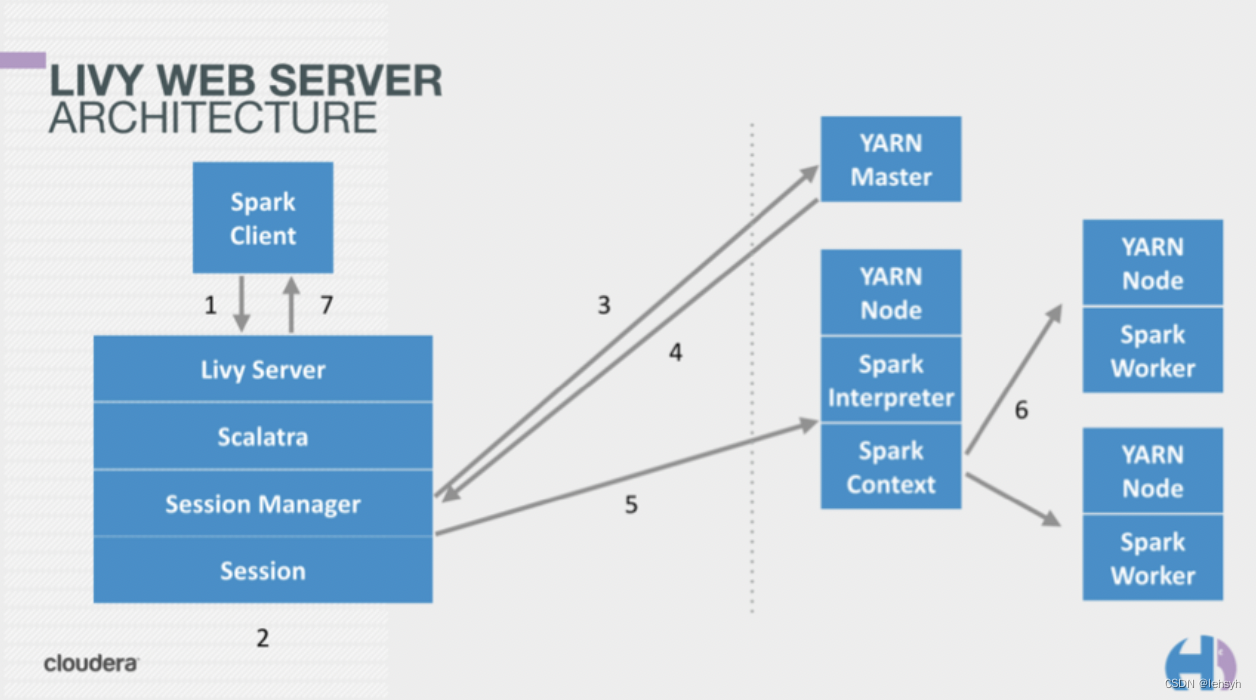
Livy把交互式和批处理都搬到了web上,提供restful接口,Livy一方面接收并解析客户端提交的REST请求,转换成相应的操作,另一方面它管理着客户端所启动的spark集群,下面是Livy的架构图:
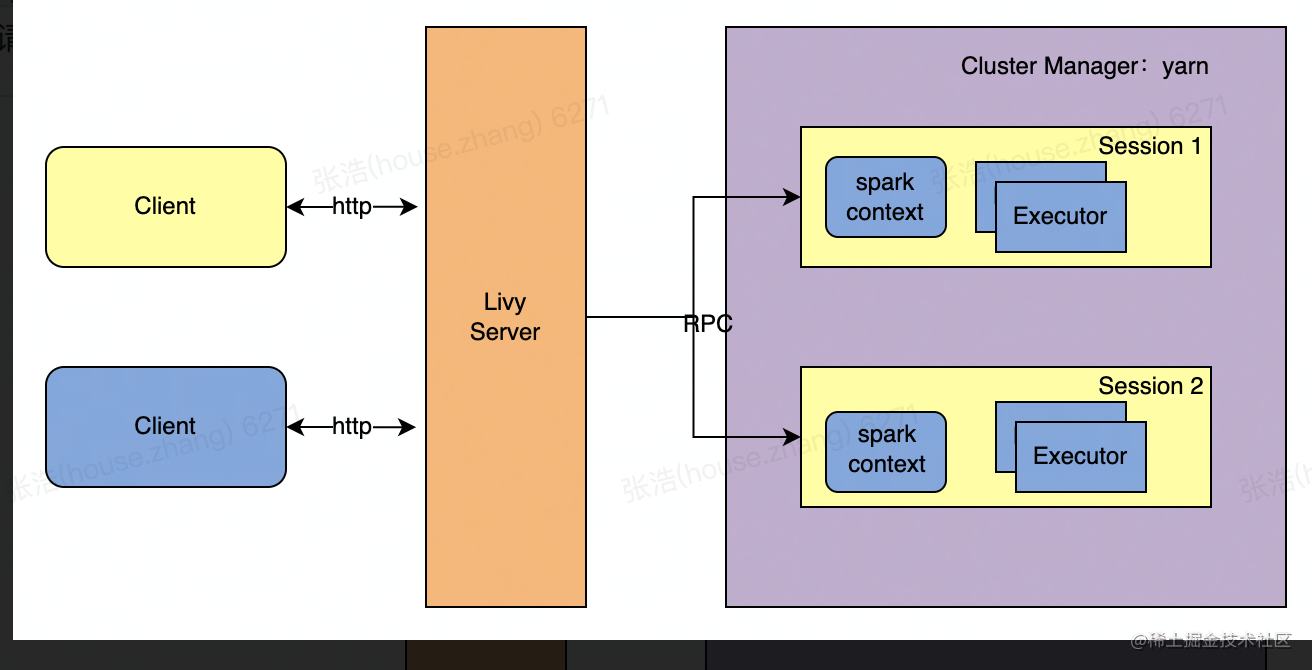
livy基本架构
Livy会为用户运行多个session,每个session就是一个常驻的spark context也可以成为一个spark集群。用户通过restful接口在对应的spark context执行代码,Livy服务端通过RPC协议与Spark集群进行通信。根据交互方式不同,Livy将会话分成两种类型:
交互式会话(interactive session):交互式会话在其启动后可以接收用户所提交的代码片段,在远端spark集群中编译并执行。
批处理会话(batch session):用户可以通过Livy以批处理的方式启动Spark应用。
这两种方式与原生spark是类似的,其中交互式会话它们的主要不同点是,spark-shell会在当前节点上启动REPL来接收用户的输入,而Livy交互式会话则是在远端的Spark集群中启动REPL,所有的代码、数据都需要通过网络来传输。
Livy具体实现
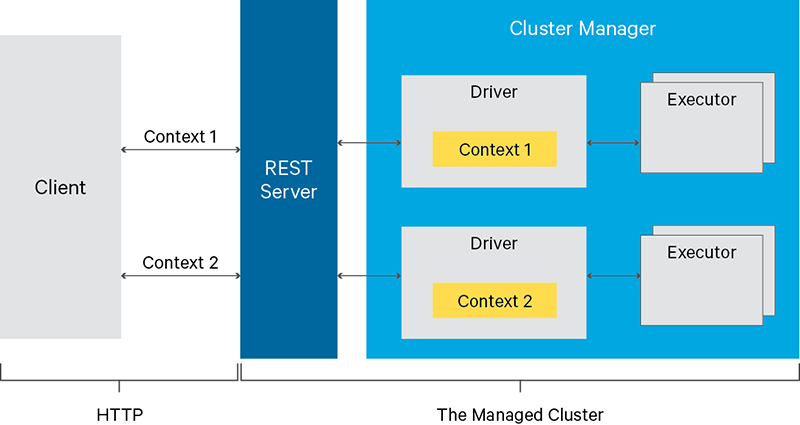
Livy的各个功能模块如下图所示:
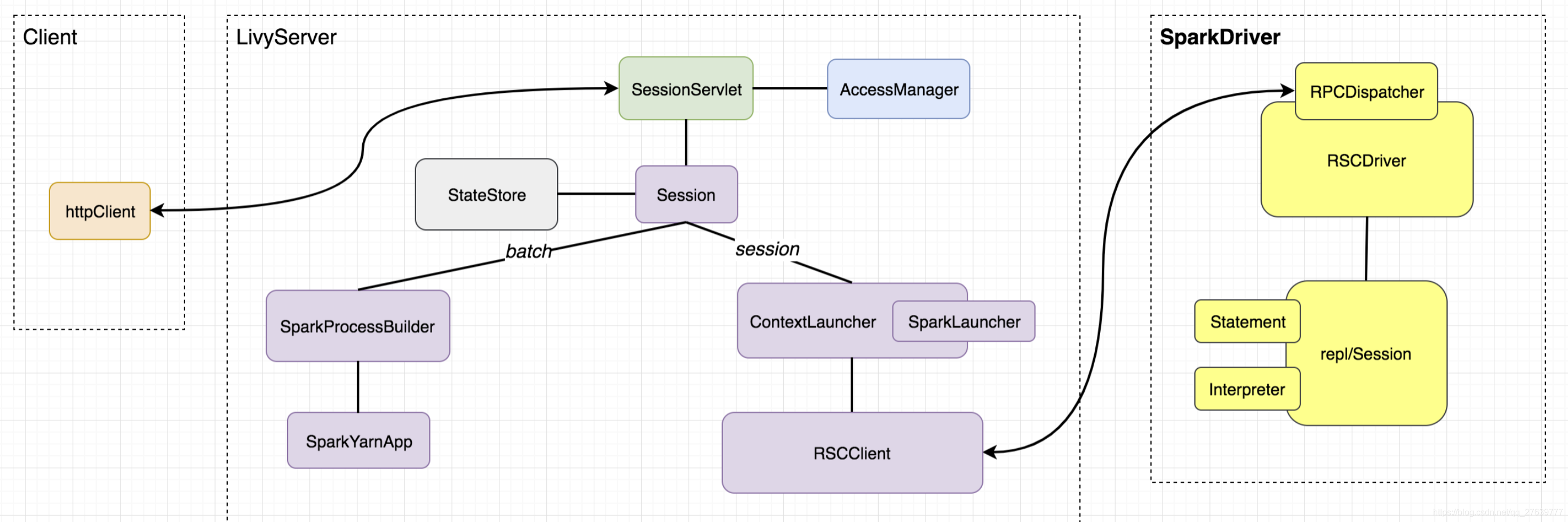
Client模块:spark任务提交请求客户端,可以通过任何http请求发送,不在livyserver模块中
任务请求路由router:用来暴露请求url,router核心功能就是通过client不同请求的uri及参数,指派给不同的类和函数进行处理。该模块的核心该模块核心类是 SessionServlet,有两个子类:InteractiveSessionServlet接收处理/sessions/下的所有请求,BatchSessionServlet接收处理/batches/ 下的所有请求,分别用来路由对session及batch相关的请求。
权限管理:权限管理由AccessManager类管理,权限管理类通过嵌入到Servlet过滤器中的成员变量进行权限方面的判断操作
其他重要特性
多用户支持
Livy引入了Hadoop中的代理用户(Proxy user )模式,代理用户模式广泛使用于多用户的环境,如HiveServer2,在此模式中超级用户可以代理普通用户去访问资源,并拥有普通用户相应的权限。有了代理用户模式的支持,不同的用户启动的会话会以相应的用户去访问资源。
失败恢复
Livy服务器是单点,所有操作都需要通过livy服务转发到Spark集群中,如何确保Livy服务端失效的时候, 所有会话不受影响,livy服务器恢复过来后能够与已有的会话重新建立连接以继续使用?
Livy提供的实效恢复机制,通过持久化会话的元信息,livy从失败中恢复会读取相关的元信息进行恢复,要开启失败恢复,需要对livy进行配置。
端到端安全
livy可以配置keberos认证、Https/SSl、及SASL RPC这三种安全机制,保障完整的端到端的安全,确保没有经过认证的用户,匿名的连接无法与livy服务中的任何一个环节进行通信。
Livy安装配置
1、livy的下载
https://livy.incubator.apache.org/get-started/
https://www.apache.org/dyn/closer.lua/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip
2、解压livy后,在livy-env.sh中添加
export SPARK_HOME=/usr/lib/sparkexport HADOOP_CONF_DIR=/etc/hadoop/confexport HADOOP_USER_NAME=hdfs
livy.conf相关配置
https://blog.csdn.net/RONE321/article/details/100517580
livy.impersonation.enabled=truelivy.repl.enable-hive-context=truelivy.server.host=0.0.0.0livy.server.port=8998livy.spark.deploy-mode=clusterlivy.spark.master=yarnlivy.server.session.timeout=5h #设置为5小时
4、开启livy服务
./bin/livy-server start
实战 livy 远程提交 spark作业
使用livy-session来执行spark-shell
https://livy.incubator.apache.org/docs/latest/rest-api.html
- 创建新的spark会话
curl -X POST --data '{"kind": "scala","proxyUser": "house"}' -H "Content-Type: application/json" http://192.168.106.11:8998/sessions
- 获取回话列表
curl http://192.168.106.11:8998/sessions
- 运行交互式代码
curl http://192.168.106.11:8998/sessions/{{sessionId}}/statements -X POST -H 'Content-Type: application/json' -d '{"code":"var a = 1;var b=a+1"}'
- 获取结果
curl http://192.168.106.11:8998/sessions/{{sessionId}}/statements/{{statId}}
- 删除会话
curl -X DELETE http://192.168.106.11:8998/sessions/{{sessionId}}
使用livy来执行 batch处理任务
livy session用来处理处理交互式请求,便于做ad-hoc即席查询,而livy batches方式用来处理非交互式请求相当于spark-submit操作。创建批处理任务案例如下:
curl -X POST -H "Content-Type: application/json" http://192.168.106.11:8998/batches --data '{ "conf": {"spark.master":"yarn-cluster"}, "file": "/user/hdfs/spark-examples-1.6.1-hadoop2.6.0.jar", "className": "org.apache.spark.examples.SparkPi", "name": "Scala Livy Pi Example", "executorCores":1, "executorMemory":"512m", "driverCores":1, "driverMemory":"512m", "queue":"default", "args":["100"]}'
总结
本文简单介绍了spark的运行方式,并介绍了基于Spark的REST服务livy。并详细介绍了其基本架构、核心功能。Livy不仅涵盖了Spark所提供了所有处理交互方式,还有多种企业级特性。
参考文档
https://github.com/apache/incubator-livy
https://www.cnblogs.com/shenh062326/p/6391057.html
https://cloud.tencent.com/developer/article/1042686
Livy - Getting Started
Apache Zeppelin 0.10.0 Documentation: Livy Interpreter for Apache Zeppelin
https://segmentfault.com/t/livy
https://www.yisu.com/zixun/56785.html
https://cloud.tencent.com/developer/article/1194700
https://www.modb.pro/db/107142